
读书笔记:Effective Modern C++
在读了大半本Effective C++时,受益于其中许多代码规则,虽说不能让coding能力突飞猛进,至少你会开始对代码安全性有所思考,对任何开始接触C++具体项目的人,这都是一本首推的书。但对2025年的今天来说,仍然使用boost库的智能指针举例的00年代的书还是略显落后。庆幸的是,同作者Scott Meyers也意识到这个问题,在10年前出版了包含C++ 11/14特性的《Effetive Modern C++》,虽然C++ 17/20甚至26已经开始进入快车道,但对大多数场景C++11和14的影响绝不能称为老旧。
译文项目来自EffectiveModernCpp_CN,持续更新。
第一章 类型推导
条款01:理解模板类型推导
决定读Effective Modern C++的另外一个原因也来自条款一,大半年前我看了几篇模板编程和类型萃取的资料,写下了一篇文章:C++ Generic Programming:SFINAF与类型萃取,其中有不少当时也不敢肯定的结论,完全是通过一些零碎的demo总结出来的,但竟然在这本书的第一章的第一节得到印证,缘分也好,伏笔也罢,至少能让我相信,这本书将节省我一些独自写demo验证新特性的时间。
看这样的模板函数: 1
2
3
4
5template<typename T>
void f(ParamType param);
//调用类似:
f(expr);
这个问题看起来很抽象,实际上你肯定考虑过: 1
2void func(int& c)
void func(int &c) int类型还是变量c,这个答案没有对错之分,因为只是简单的类型写法,而在模板的推导中,划分给T还是划分给param是有严格的规则的,如果你喜欢看具体例子和讨论可以参考上述文章。
这里我们直接结合原书和之前的结论重新给出。
情况一:形参是非万能引用
结论1: 形参类型是左值引用、右值引用、指针类形式,那么T都是非引用,形参类型取决于匹配到什么类型;
如左值引用情况: 1
2
3
4
5
6
7
8
9
10template<typename T>
void f(T& param); // 左值引用
///左值情况:
int x=27; //x是int
const int cx=x; //cx是const int
const int& rx=x; //rx是指向作为const int的x的引用
f(x); //T是int,param的类型是int&
f(cx); //T是const int,param的类型是const int&
f(rx); //T是const int,param的类型是const int&const,就T就不含const了,这就是匹配的效果:const不会匹配到T里面
1
2
3
4
5
6
7
8
9
10template<typename T>
void f(const T& param); // 含const的左值引用
int x=27; //x是int
const int cx=x; //cx是const int
const int& rx=x; //rx是指向作为const int的x的引用
f(x); //T是int,param的类型是const int&
f(cx); //T是int,param的类型是const int&
f(rx); //T是int,param的类型是const int&
右值引用情况: 1
2
3
4
5
6
7
8
9
10
11template<typename T>
void f(const T&& param); // 右值引用(含const就不是万能引用)
int x=27; //x是int
const int cx=x; //cx是const int
const int& rx=x; //rx是指向作为const int的x的引用
test(27);
test(std::move(x)); // T是int,param的类型是const int&&
test(std::move(cx)); // T是int,param的类型是const int&&
test(std::move(rx)); // T是int,param的类型是const int&&
指针情况也类似,T不会被解释成指针:
1
2
3
4
5
6
7
8template<typename T>
void f(T* param); //param现在是指针
int x = 27; //同之前一样
const int *px = &x; //px是指向作为const int的x的指针
f(&x); //T是int,param的类型是int*
f(px); //T是const int,param的类型是const int*
这容易理解,原书没有特别提到,但是如果传入的是指针且形参带const又如何呢,我们会发现:当形参带const时,T也不一定是非const特性的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23template<typename T>
void ff(const T& param){
if(std::is_same<T, const char*>::value)
cout << "std::is_same<T, const char*>::value" << endl;
if(std::is_same<decltype(param), const char* const &>::value)
cout << "std::is_same<decltype(param), const char* const &>::value" << endl;
if(std::is_same<T, int*>::value)
cout << "std::is_same<T, int*>::value" << endl;
if(std::is_same<decltype(param), int* const &>::value)
cout << "std::is_same<decltype(param), int* const &>::value" << endl;
}
int main() {
const char* pname = "EdemMo";
ff(pname); //触发#1和#2
int name1 = 27;
int* pname1 = &name1;
ff(pname1); //触发#3和#4
cout << "done" << endl;
return 0;
}const char*字符串,T推导也是const char*,而不是char*;而传入同为指针的int*,T推导的是int*;当然基础好的会立马反应过来这根本是庸人自扰,const char*可不是普通的char*,const char*表示的是一个字符常量,说明字符内容是不可更改的,而形参T的const,传入指针时匹配指的是指针指向不可修改(这是指针常量范畴),因此它不会去除你的常量指针特性。同理,如果传入的类是const特性的常量指针,如const Widget*,那么这个常量特性也不会去除,条款04我们会看到印证这个特点的例子。从param表现来看也可知,当对const T&传入一个指针时,指针会被赋予指针常量的特性,它与原来指针本身的常量指针特性互不干扰。总而言之,当形参已经带const,不能一概认为T一定是被匹配为非const特性。
情况二:形参是万能引用
结论2:当形参是万能引用形式时,传入实参为左值、左值引用和右值引用,最终T和形参类型都会被推导为左值引用类型(这也是类型推导中T被推导成引用的唯一情况),而传入实参是右值时,适用结论1,即T为非引用,形参被推导为右值引用,我从之前的文章直接把demo抄过来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25template<typename T>
void func(T&& num){ //万能引用形式
if(std::is_lvalue_reference<T>::value)
cout<<"is_lvalue_reference<T>"<<endl;
if(std::is_rvalue_reference<T>::value)
cout<<"is_rvalue_reference<T>"<<endl;
if(std::is_lvalue_reference<decltype(num)>::value)
cout<<"decltype is_lvalue_reference"<<endl;
if(std::is_rvalue_reference<decltype(num)>::value)
cout<<"decltype is_rvalue_reference"<<endl;
}
//左值、左值引用、右值引用:输出is_lvalue_reference<T>和decltype is_lvalue_reference
int a = 5;
int& b = a;
int&& c = 10;
func(a);
func(b);
func(c);
//右值类型:仅输出decltype is_rvalue_reference
func(5);
func(std::move(a));
func(std::move(b));
func(std::move(c));
情况三:值传递
结论3: 形参是值传递形式时,传入实参的引用特性、const/volatile特性均被忽略。
这很容易理解,因为形参是实参的拷贝,实参的任何特性都不大可能影响拷贝的表现:
1
2
3
4
5
6
7
8
9
10template<typename T>
void f(T param); //以传值的方式处理param
int x=27; //如之前一样
const int cx=x; //如之前一样
const int & rx=cx; //如之前一样
f(x); //T和param的类型都是int
f(cx); //T和param的类型都是int
f(rx); //T和param的类型都是intconst char*传入时const特性会被去掉,但一种特殊的表示是const char* const expr,这样的实参传递给param,第二个const特性(指针常量)会被忽略、第一个const特性(常量指针)会被保留(即形参类型变成const
char*)。
情况四:传入实参是数组
结论4:形参是指针或数组形式,传入数组退化成指针;形参是引用形式,T是数组类型,形参是数组引用类型。
先看形参是指针或者数组的形式,这两种声明是完全等效的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15template <typename T>
void test(T* input){
if(std::is_same<T, const char>::value)
cout << "std::is_same<T, const char>::value" << endl;
if(std::is_same<decltype(input), const char*>::value)
cout << "std::is_same<decltype(input), const char*>::value" << endl;
}
template <typename T>
void ttest(T input[]){ //等效于指针声明
if(std::is_same<T, const char>::value)
cout << "std::is_same<T, const char>::value" << endl;
if(std::is_same<decltype(input), const char*>::value)
cout << "std::is_same<decltype(input), const char*>::value" << endl;
}
无论传入数组,还是指针,都退化成指针:即适用结论1,T将被推导成非引用,如const char,而形参自身被推导成指针,如const char*:
1
2
3
4const char name[] = "EdenMo";
const char* pname = name;
test(name);
test(pname); //均输出std::is_same<T, const char>::value、std::is_same<decltype(input), const char*>::value
最有趣的事情来了,C语言存在数组退化指针机制,当你想完整保留推导的数组特性,C++的引用可以满足你:
1
2template <typename T>
void func(T& param)const char[N],而形参的类型将被推导成const char(&)[N](奇怪但有用);而当你传入一个指针时,T会被推导成指针类型,如const char*,而形参类型被推导成指针的引用,如const char*&(奇怪且无用),一个验证示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18template <typename T>
void ttest(T& input){
///传入实参是数组:
if(std::is_same<T, const char[7]>::value) //#1
cout << "std::is_same<T, const char[7]>::value" << endl;
if(std::is_same<decltype(input), const char(&)[7]>::value) //#2
cout << "std::is_same<decltype(input), const char(&)[7]>::value" << endl;
///传入实参是指针:
if(std::is_same<T, const char*>::value) //#3
cout << "std::is_same<T, const char*>::value" << endl;
if(std::is_same<decltype(input),const char*&>::value) //#4
cout << "std::is_same<decltype(input),const char*&>::value" << endl;
}
const char name[] = "EdenMo";
const char* pname = name;
ttest(name); //触发#1和#2
ttest(pname); //触发#3和#4const char(&)[N]和const char*&,后者基本没什么用,但是前者可以结合constexpr和模板,获取数组长度:
1
2
3
4
5
6
7
8
9
10template <typename T, std::size_t N>
constexpr std::size_t getArraySize(T(&)[N]) noexcept{ //条款14会知:noexcept使得编译的代码更好
return N;
}
//调用:
int arr[] = {1,2,3,4,5};
int arr1[getArraySize(arr)]; //编译期定长
std::array<int,getArraySize(arr)> arr2;
cout << sizeof(arr1)/sizeof(int) << arr2.size() << endl; //5 5
情况五:传入实参是函数指针
函数和数组一样,都会退化成指针,因此没有什么新理论了,总结为:
| 模板形式 | 推导T类型 | 推导形参类型 |
|---|---|---|
| void func(T param) | void(*)(int,int) | void(*)(int,int) |
| void func(T& param) | void(int,int) | void(&)(int,int) |
| void func(T* param) | void(int,int) | void(*)(int,int) |
条款02:理解auto类型推导
把大量复杂的类型推导理论写在条款01是有缘由的,过去我一直错误认为模板推导仅用于泛型编程中,直到读完条款02,另一种理由是让你更胸有成竹地使用“auto”。
auto的推导原理和模板推导是一致的,当你简单地写下auto赋值时,相当于使用了三种模板推导:
1
2
3
4
5
6
7
8
9
10
11template <typename T>
void func(T param)
func(27); //相当于 auto x = 27;
template <typename T>
void func1(const T param)
func1(x) //相当于 const auto cx = x;
template <typename T>
void func2(const T& param)
func2(x) //相当于 const auto& rx = x;
同理,auto像条款01的情况二一样调用万能引用:
1
2
3auto&& uref1 = x;
auto&& uref2 = cx; //实参为左值,auto和uref1、uref2均是左值引用类型(int&)
auto&& uref3 = 27; //实参为右值,auto是int类型,uref3是右值引用类型(int&&)
数组、函数指针表现也与模板推导一致: 1
2
3
4
5
6
7const char name[] = "R. N. Briggs";
auto arr1 = name; //值传递:指针退化,arr1的类型是const char*
auto& arr2 = name; //引用传递:arr2类型是const char (&)[13]
void func(int, double);
auto func1 = func; //值传递:func1类型是void(*)(int,double)
auto& func2 = func; //引用传递,func2类型是void(&)(int,double)1
2
3
4
5
6void func(int, double);
auto& func2 = func; //引用传递,func2类型是void(&)(int,double)
//错误:不允许置空或二次赋值!
func2 = nullptr;
func2 = func_else;
C++11的统一初始化
auto和模板推导存在一个例外的区别:auto支持统一类型的花括号推导,而模板推导必须显式指明std::initializer_list<T>才能成功推导类型T;
C++
11引入了花括号初始化方式,称为统一初始化(uniform
initialization): 1
2
3
4
5
6
7//C++98语法:
int x = 27;
int x(27);
//C++11 支持:
int x = {27};
int x{27};std::initializer_list<int>,而不是int(其中auto x{27};在N3922后才修正为int):
1
2
3
4
5auto x = 27;
auto x(27); //都是int
auto x{27}; //修正为int
auto x = {27}; //注意,为std::initializer_list<int>
auto可以使用列表推导,但是要求列表元素必须同一种数据类型:
1
2auto list = {1, 2, 3, 4}; //ok,推导为std::initializer_list<int>
auto list1 = {1, 2, 3.3f}; //无法编译
而在模板中,无论列表元素类型相不相同,都无法直接使用列表推导,只能显式使用std::initializer_list<T>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19template <typename T>
void test(T param){
for(int x:param){
cout << x << ", ";
}
cout << endl;
}
template <typename T>
void ttest(std::initializer_list<T> param){
for(int x:param){
cout << x << ", ";
}
cout << endl;
}
///调用:
//test({1,2,3,4}); //错误:不存在模板
ttest({1,2,3,4}); //ok
同样的,在C++14中,允许使用auto作为函数返回值类型,但是仍然使用模板推导规则进行,所以auto仍然不支持推导返回列表的类型:
1
2
3
4//error code:
auto getArray(){
return {1,2,3};
}1
2
3
4
5
6
7 std::vector<int> vp;
auto resetVp = [&vp](const auto& newvp){
vp = newvp;
};
resetVp(std::initializer_list<int>{1,2,3,4}); //ok
resetVp({1,2,3,4}); //错误:不存在模板
std::initializer_list
再插点题外拓展,std::initializer_list是一种很轻量的结构,支持遍历打印,但不支持修改元素(增删改),适宜局部存储一些列表值、作为函数参数等,如:
1
2
3
4
5void doSomething(std::initializer_list<int> lst){
for(int x : lst){
...
}
}1
2
3
4
5void doSomething(std::initializer_list<Person> lst){
for(const auto& p : Person){
...
}
}1
2
3
4
5
6
7auto getArray1() {
return std::vector<int>{1, 2, 3}; //good
}
auto getArray1() {
return std::initializer_list<int>{1, 2, 3}; //危险!补药这么干啊......
}
条款03:理解decltype
decltype最常用的用法是推导变量的类型,相比于前两个条款的模板推导和auto推导,decltype只是简单地返回变量的类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const int i = 0; //decltype(i)是const int
bool f(const Widget& w); //decltype(w)是const Widget&
//decltype(f)是bool(const Widget&)
struct Point{
int x,y; //decltype(Point::x)是int
}; //decltype(Point::y)是int
Widget w; //decltype(w)是Widget
if(f(w)){ //decltype(f(w))是bool
......
}
template<typename T> //std::vector的简化版本
class vector{
public:
…
T& operator[](std::size_t index);
…
};
vector<int> v; //decltype(v)是vector<int>
if (v[0] == 0){ //decltype(v[0])是int&
......
}
其中值得注意的是,对于T类型的STL容器,使用operator[]往往会返回一个T&,但是例外是std::vector<bool>,其operator[]返回的不是bool&,在MSVC平台,其返回的是std::_Vb_reference<std::_Wrap_alloc<std::allocator<unsigned int>>>,而在类gcc平台,返回的是std::_Bit_reference&&,详见条款06;
C++11 允许自动推导单一lambda语句的返回类型,如: 1
2
3
4
5//这并不完美
template <typename Container, typename Index>
auto authAndAccess_decltype(Container& c, Index i)->decltype(c[i]){
return c[i];
}
C++ 14起则支持直接使用auto推导,如: 1
2
3
4
5//这也不完美
template <typename Container, typename Index>
auto authAndAccess_auto(Container& c, Index i){
return c[i];
}authAndAccess_decltype有了更严重缺陷,即推导引用丢失。
所以你不能给返回值赋值,根据auto和模板推导可知,返回的operator[]大概一个T&,而赋予一个auto值,相当于值递,忽略引用,因此auto和形参接受实参c[i]后,实际上都被推导成T,这是一种右值,不能被赋值:
1
2
3std::deque<int>dp{1};
authAndAccess_decltype(dp, 0) = 27; //ok
authAndAccess_auto(dp,0) = 27; //无法编译1
2
3
4
5
6int getx(){
int x = 27;
return x;
}
getx() = 27; //绝对错误!authAndAccess_auto不能通过编译,如果你需要真正返回一个可赋值对象,按模板编译,你需要使用auto&,此时auto推导的是int,但是会产生一个T&左值对象:
1
2
3
4
5template <typename Container, typename Index>
auto& authAndAccess_auto_c(Container& c, Index i){ //引用返回
return c[i];
}
authAndAccess_auto_c(dp,0) = 27; //ok
decltype(auto)
C++14有另外一种写法,满足了我们所有期待,可以这样:
1
2
3
4
5//这接近完美
template<typename Container, typename Index>
decltype(auto) authAndAccess_decltypeauto(Container& c, Index i){
return c[i];
}T&(如同在->decltype(c[i])做的那样)。
除了用作函数返回值,decltype(auto)可以作为类别声明使用,如:
1
2
3
4Widget w;
const Widget& cw = w;
auto myWidget1 = cw; //myWidget1的类型为Widget
decltype(auto) myWidget2 = cw; //myWidget2的类型是const Widget&auto&也能够保留cw的const和引用特性,但是你传入一个原始类型时,你必须又换成auto,而传入一个右值,或者一个来自完美转发的右值返回,你又得换成auto&&,否则你甚至无法完成编译,显然decltype(auto)比较强大且无脑。
对C++ 11,最后比较完美的右值容器模板应该为:
1
2
3
4template<typename Container, typename Index>
decltype(auto) authAndAccess_decltypeauto_uni(Container&& c, Index i){
return std::forward<Container>(c)[i];
}1
2
3
4template<typename Container, typename Index>
auto authAndAccess_decltypeauto_uni(Container&& c, Index i)->decltype(std::forward<Container>(c)[i]){
return std::forward<Container>(c)[i];
}
decltype古怪细节
最后是decltype的一点古怪细节,正如上文所述,decltype大部分场景下返回简单的类型,但是可能会被一个括号干扰:
1
2
3
4
5
6
7
8
9
10
11
12
13int x = 27;
decltype(x); //int
decltype((x)); //int&
decltype(auto) f1(){ //ok
int x = 0;
return x; //decltype(x)是int,所以f1返回int
}
decltype(auto) f2(){ //极其危险!
int x = 0;
return (x); //decltype((x))是int&,所以f2返回int&
}(x)写法是一个左值,因此如果结合了decltype(auto),那么f2将返回一个局部变量的引用,是危险的行为,应该警惕。
条款04:学会查看类型推导的结果
结论1:注意编译器、IDE提供的类型推导有可能是错误的。
对于简单类型,typeid返回类型名称的经过编译器处理的mangled
name(经修饰的名称),例如下面代码gcc会分别返回i和PKi,而MSVC会直白地返回int和int const*:
1
2
3
4
5
6
7
8
9
10
11
12
13
using namespace std;
int main() {
const int x = 27;
auto y = &x;
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << "done" << endl;
return 0;
}
但是如果是一些比较复杂的类型代码耦合产生的对象,如运行这样的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
using namespace std;
class Widget{
public:
Widget(int num){
_num = num;
}
~Widget(){}
private:
int _num;
};
std::vector<Widget> produce(std::vector<int>& vp){ //通过工厂模式返回一组对象
std::vector<Widget> res;
for(const auto& pos : vp){
Widget* temp = new Widget(pos);
res.emplace_back(*temp);
delete temp;
}
return res;
}
template<typename T>
void f(const T& param){
cout << "T type: " << typeid(T).name() << endl;
cout << "param type: " << typeid(param).name() << endl;
}
int main() {
std::vector<int> vp{1,2,3};
const auto widgetVp = produce(vp);
if(!widgetVp.empty()){
f(&widgetVp[0]);
}
Widget* wid = new Widget(10);
f(wid);
delete wid;
cout << "done" << endl;
return 0;
}1
2
3
4T type: PK6Widget
param type: PK6Widget
T type: P6Widget
param type: P6WidgetPK6Widget指的是Pointer to const Widget(const Widget*),而使用正常堆区构造,P6Widget指的是Pointer to Widget(Widget*),无论哪一个,两个结果和模板类型推导理论是相悖的,至少T和param的推导结果不应该相同。对于工厂模式,向左值引用传入一个左值常量指针即const Widget*,T应该是const Widget*,对应的param应该是const Widget* const&(此处为什么不是Widget*和const Widget*&,在条款01我已经讲过了)。可见,编译器的输出并非是完全可信的。
使用boost库能推导比较准确的结果: 1
2
3
4
5
6
7
template<typename T>
void f(const T& param){
cout << "T type: " << boost::typeindex::type_id_with_cvr<T>().pretty_name() << endl;
cout << "param type: " << boost::typeindex::type_id_with_cvr<decltype(param)>().pretty_name() << endl;
}
输出结果: 1
2
3
4
5T type: Widget const*
param type: Widget const* const&
T type: Widget*
param type: Widget* const&
第二章 auto
本章会覆盖描述关于auto必要的若干使用场景。
条款05:优先考虑auto而非显式类型声明
必须初始化
1 | int x; //可能声明一个未定义变量 |
闭包
闭包是一个抽象的概念,通常可以理解为Lambda函数,其特点就是能够捕获函数内的其他变量和环境,但是它的返回类型只有编译器才知道,这些特点使得我们专注于函数的功能,而无需太过纠结我们究竟想返回什么样的类型才算正确,例如:
1
2
3
4
5
6
7
8template <typename It>
void dwim(It b, It e){
while(b != e){
typename std::iterator_traits<It>::value curValue = *b; //curValue的类型来自迭代器指向的元素类型
//who cares?I choose auto:
auto curValue = *b;
}
}
另一方面,因为闭包不会显式说明要返回的类型,auto符合这种惰性习惯,如:
1
2
3
4
5
6
7
8
9//C++ 11:
auto derefUPLess = [](const std::unique_ptr<Widget>& p1, const std::unique_ptr<Widget>& p2){
return *p1 < *p2;
}
//C++ 14中更离谱:
auto derefUPLess = [](const auto& p1, const auto& p2){
return *p1 < *p2;
}std::function和std::bind,是的,这两种形式允许保存或者生成一个闭包(或者任何可调用对象),例如使用前者,你必须写成:
1
2
3std::function<bool(const std::unique_ptr<Widget>& p1, const std::unique_ptr<Widget>& p2)> func =
[](const std::unique_ptr<Widget> &p1, const std::unique_ptr<Widget> &p2){
return *p1 < *p2; };std::bind,在条款34也会发现根本比不上一个Lambda。
意料外的拷贝
auto还可以防止因为某些类型认识的错误,导致冗余的对象创建和销毁,如遍历一个哈希表:
1
2
3
4std::unordered_map<std::string, int> m;
for(const std::pair<std::string, int>&p : m){
...
}std::string,而是const std::string,所以为了完成这个类型转换,会特意地拷贝m中的对象作为临时对象,将引用绑定到该临时对象上,当使用完会被销毁,而这冗余的拷贝本来可以通过使用auto避免。
条款06:auto推导若非己愿,使用显式类型初始化惯用法
前几个条款怂恿开发者无脑使用auto,这个条款是悬崖勒马,一些情况下不掌握推导具体情况而使用有可能踩坑,其中一个坑来自std::vector<bool>,这个容器特点在条款03已经提过。
std::vector<bool>不同于其他std::vector<T>,在C++98时期就被认为一种设计失误。开始时他们希望std::vector<bool>实际占据更少的空间,事实上也做到了,容器内的每个bool对象只占据1比特,而不是1字节。但是代价却很大,因为不能对其取地址,其引用返回的也不是纯粹的bool&,这样的代码是一种错误:
1
2
3
4//这无法编译:
std::vector<bool> bvp(8,false);
bool* bp = &bvp[0];
bool& bpr = bvp[0];1
2//error:
bool* cbp = bvp.data();
但是C++ 11引入auto后,使得这样的代码通过称为可能: 1
2std::vector<bool> bvp(8,false);
auto a = bvp[4];operator[]返回对象的引用,std::vector<bool>是一种例外,其返回的是一个std::vector<bool>::reference对象(这个类定义于std::vector<bool>中),为了模拟bool&特性,这个reference类中必然含有一个指针以及记录bit的偏移量,这个指针会在语句声明完后被销毁(成为一个悬垂指针),所以任何函数再引用这个auto定义的a变量,会导致UB。
所以首先应该使用std::deque<bool>或其他类型STL替代std::vector<bool>,再者使用显式声明:
1
2std::vector<bool> bvp(8,false);
bool a = bvp[4]; //还可以
std::vector<bool>不是唯一,std::bitset的std::bitset::reference亦是如此,这种引入代理模范原来特性的,称为代理类,这两个例子的代理都是不可见的(基本不可能看到显式声明一个std::vector<bool>::reference),另外一些代理类是可见的,比如智能指针就完全模拟了指针特性,而且代理类往往可以作为原类的初始化条件,但要注意这些隐含的代理类结合auto都可能导致UB,应该避免。
第三章 拥抱现代C++
条款07:区别使用()和{}初始化对象
花括号初始化是很通用了,例如圆括号不能初始化普通成员,等于号无法初始化不能拷贝的成员(如std::atomic),如:
1
2
3
4
5
6
7
8
9
10
11
12class Person{
...
private:
int x{0}; //ok
std::actomic<int> y{0}; //ok
int x1(0); //error!
std::actomic<int> y1(0); //ok
int x2 = 0; //ok
std::actomic<int> y2 = 0; //error!
};1
2
3Widget x;
Widget y = x; //触发的是拷贝构造函数
x = y; //触发的是拷贝赋值函数
使用花括号也能触发构造函数,还能解决圆括号混淆调用构造还是作函数声明的歧义:
1
2
3
4Widget w(); //既可以是无参构造、也可以是函数声明
Widget w1{};
Widget w2{10}; //均ok
但使用花括号没有好到值得无脑推广,例如,它禁止变窄转换(narrowing
conversion),而等号、圆括号没有这个问题:
1
2
3
4
5double x, y, z;
int sum1{ x + y + z }; //error!
int sum2(x + y +z); //ok
int sum3 = x + y + z; //ok
再者,使用花括号初始化,如果构造函数含有std::initializer_list形参,会导致构造函数的选择产生倾向性!例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
using namespace std;
class Widget{
public:
Widget(int i, bool b){
cout << "This is Widget(int i, bool b)" << endl;
}
Widget(int i, double b){
cout << "This is Widget(int i, double b)" << endl;
}
Widget(std::initializer_list<long double> ld){
cout << "This is std::initializer_list<long double> ld" << endl;
}
};
int main(){
Widget w1(10, false); // This is Widget(int i, bool b)
Widget w2(10, 9.99f); // This is Widget(int i, double b)
Widget w3({false, 9.99f}); // This is std::initializer_list<long double> ld
Widget w4{10, false}; //全是This is std::initializer_list<long double> ld
Widget w5{10, 9.99f};
Widget w6{false, 9.99f};
return 0;
}std::initializer_list<T>时却引入了变窄转换,构造就会失败:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Widget{
public:
Widget(int i, bool b){
cout << "This is Widget(int i, bool b)" << endl;
}
Widget(int i, double b){
cout << "This is Widget(int i, double b)" << endl;
}
Widget(std::initializer_list<bool> ld){
cout << "This is std::initializer_list<long double> ld" << endl;
}
};
Widget w{10, 5.0}; //编译失败! 均不能变窄转换到bool
最后,使用花括号和圆括号的最大区别还是在设计上,例如std::vector<int>(10,20)和std::vector<int>{10,20}是完全不同的含义,创建一个接受任意对象参数的可变模板,你就需要面对这样的问题:
1
2
3
4
5
6template <typename T, typename... Ts>
void doSomeWork(Ts&&... params){
//create local T like this:
T localObj(std::forward<Ts>(params)...); //#1 //你选择使用哪种定义?
T localObj{std::forward<Ts>(params)...}; //#2
}1
doSomeWork<std::vector<int>>(10,20) ;
std::make_shared和std::make_unique(见条款21)的解决方法是使用圆括号。
条款08:优先考虑使用nullptr而非NULL或0
NULL和0其实都不是真正的指针类型,f(0)和f(NULL)都不太可能调用指针类型形参函数,而可能会调用整形形参的,NULL的一种实现是被定义为0L:
1
2
3void f(void*);
void f(int);
void f(bool);f(NULL)会导致二义性,对应long的参数,既可能调用int版本,也可能调用bool版本,但不太可能调用指针版本。
这是一种反直觉,所以C98里常常需要避免同时重载整形和指针类型。
而nullptr是std::nullptr_t类型,是真正的指针类型,会完美对应void f(void*)重载,而不会被解释为整形,此外,nullptr可以隐式转换到所有指针类型(包括智能指针),例如一个例子:
1
2
3
4
5
6
7
8
9
10
11int f1(std::shared_ptr<Widget> spw){
return 10;
}
double f2(std::shared_ptr<Widget> spw){
return true;
}
bool f3(Widget*){
return true;
}nullptr、NULL、0或者都可以通过编译,但是我们将其模板化,完整代码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
using namespace std;
using MuxGuard = std::lock_guard<std::mutex>;
class Widget{
};
int f1(std::shared_ptr<Widget> spw){
return 10;
}
double f2(std::shared_ptr<Widget> spw){
return true;
}
bool f3(Widget*){
return true;
}
//传入一个互斥量,每个函数参数都是指针,但指针类型不同
template <typename FunType, typename MutexType, typename PtrType>
decltype(auto) lockAndCall(FunType func, MutexType& mutex, PtrType ptr){ //看不懂返回值,你需要回顾前三条条款
MuxGuard mtx(mutex);
return func(ptr);
}
int main(){
std::mutex mtx;
lockAndCall(f1, mtx, nullptr);
lockAndCall(f2, mtx, nullptr);
lockAndCall(f3, mtx, nullptr);
//均无法编译:
// lockAndCall(f1, mtx, 0);
// lockAndCall(f2, mtx, 0);
// lockAndCall(f3, mtx, 0);
// lockAndCall(f1, mtx, NULL);
// lockAndCall(f2, mtx, NULL);
// lockAndCall(f3, mtx, NULL);
return 0;
}nullptr能完美推导成指针,而另外两种都会被推导为int导致无法找到函数模板而无法通过编译。
条款09:优先考虑using而非typedef声明别名
typedef和using都能声明一个别名,如:
1
2typedef std::unique_ptr<std::unordered_map<std::string, std::string>> UPtrMapSS;
using UPtrMapSS = std::unique_ptr<std::unordered_map<std::string, std::string>>
函数指针
using声明的函数指针更加直观: 1
2
3typedef void(*FP)(int, const std::string&);
using FP = void(*)(int, const std::string&);
函数模板
从C/C++/Qt
修炼手册就提过,using很容易结合模板使用,而typedef无法定义泛型的模板别名,实际上不准确,typedef结合struct或者class就可以定义模板别名,如:
1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T>
using MyAllocList = std::list<T,MyAlloc<T>>; //定义一个泛型列表,自定义分配器MyAlloc
template <typename T>
struct MyAllocList_T{ //需要定义一个模板类作为类型
typedef std::list<T,MyAlloc<T>> type;
}
//using调用:
MyAllocList<Person> p;
//typedef:
MyAllocList_T<Person>::type p;MyAllocList_T<T>::type被称为依赖类型,依赖类型的一个特点是模板内部你要加上typename声明这是一个类型含义,而不是对象,如:
1
2
3
4
5template <typename T>
class Widget{
private:
typename MyAllocList<T>::type list; //模板内部 的 类型前要加typename
};
编译器有必要根据typename来标识对象和类型,例如一种特化版本的,MyAllocList_T<T>::type被定义成对象:
1
2
3
4
5template<>
class Widget<Wine>{
private:
WineType type; //god! Widget<Wine>::type is an object !
};
而使用using则无需考虑是否要加"typename"声明,因为编译器会将其视作非依赖类型。
在函数模板上两种方法的区别也影响到了模板元编程中类型萃取的一些特性,如去除引用、常量特性的一些关键字:
1
2
3std::remove_const<T>::type // const T to T
std::remove_reference<T>::type //T& T&& to T
std::add_lvalue_reference<T>::type // T to T&
因此在C++14,std::transformation<T>::type全都成为了std::transformation_t<T>,尽管不支持C++14,使用using定义等效的定义是简单的:
1
2template <class T>
using remove_const_t = typename remove_const<T>::type;
条款10:优先考虑限域枚举而非未限域枚举
限域
众所周知,C++ 11
enum class比起C++98的enum,首要是支持限域:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16enum class Color{
black,
white,
red
};
enum class Cow{
black,
white,
red
};
Color c = Color::red;
Cow c = Cow::red; //OK
int red = 10; //变量叫red也ok
强类型
enum class声明的枚举类型属于强类型,意味着它不会被隐式地转换成整型或者浮点型:
1
2
3
4
5
6
7
8enum Color{black, white, red};
enum class Colorc{black, white, red};
Color c;
if(c < 9.9f){} //ok,隐式转换了
Colorc cc;
if(static_cast<double>(cc) < 9.9f){} //必须显示声明才能编译
但毕竟并非所有的隐式转换都是有害的,有时非限域类型更加方便,例如在tuple使用里面:
1
2
3std::tuple<std::string, std::string> t{"Eden", "White"};
cout << std::get<0>(t) << std::get<1>(t);1
2
3enum Define{name=0, Color = 1};
std::tuple<std::string, std::string> t{"Eden", "White"};
cout << std::get<Define::name>(t) << std::get<Define::Color>(t) << endl;enum class,就必须将显式转换声明出来:
1
std::get<static_cast<std::size_t>(Define::name)>(t);
std::size_t,C++
11是支持通过std::underlying_type获取枚举类型的真实底层类型的,但要求这个类型产生必须在编译期完成,所以模板函数使用constexpr,如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
using namespace std;
template <typename T>
constexpr typename std::underlying_type<T>::type toUtype(T e) noexcept{ //也可以替换成std::underlying_type_t<T>
return static_cast<typename std::underlying_type<T>::type>(e);
}
int main(){
enum class Define{name=0, Color = 1};
std::tuple<std::string, std::string> t{"Eden", "White"};
cout << std::get<toUtype(Define::name)>(t) << std::get<toUtype(Define::Color)>(t) << endl;
return 0;
}
前置声明
enum class默认使用int类型存储,因此能直接作前置声明,而enum必须显式指明底层类型才可以:
1
2
3
4enum class Status; //默认就是int
enum Status; //错误,无法获知大小
enum Status : std::uint8_t; //ok
条款11:优先考虑使用delete而使用未定义的私有声明
本条款是对读书笔记:Effective
C++(第三版)的条款06作更新说明,在C++
11以后,直接使用delete比将函数声明为private适用性更广,例如你无法将某个函数模板的特化单独列为private,而可以直接delete:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Widget {
public:
…
template<typename T>
void processPointer(T* ptr)
{ … }
private:
template<> //错误!
void processPointer<void>(void*);
};
class Widget {
public:
…
template<typename T>
void processPointer(T* ptr)
{ … }
…
};
template<> //还是public,
void Widget::processPointer<void>(void*) = delete; //但是已经被删除了
条款12: 使用override声明重写函数
重写一个函数,必须满足以下条件:
基类必须是virtual虚函数;
基类和派生类的函数名称必须一致(析构函数除外);
基类和派生函数形参类型必须一致;
基类和派生类的constness常量性必须一致,如
void doWork() const;基类和派生类的返回值和异常说明必须兼容;
(C++11新增)函数的引用限定符(referecne qualifiers)必须一致,函数的引用调用符指的是函数名后的
&和&&,其中&或者const &限定函数只能被左值调用,&&只能被右值调用,const&&能被左右值对象调用,如下:1
2
3
4void doWork() &;
void doWork() &&;
void doWork() const &;
void doWork() const &&;有时有必要区分左右值调用的对象,例如:
1
2
3
4
5
6
7
8
9
10
11class Widget{
public:
using DataType = std::vector<double>;
...
DataType& data(){
return values;
}
private:
DataType values;
};当使用类似工厂模式的对象获取返回值时,会变成:
这样的代码会从makeWidget产生的右值对象中的vector又拷贝出一个vector,纯属浪费(因为根本不可能直接使用右值对象本身的vector),因此完全可以将其利用起来避免一次拷贝,在Widget中新增一个右值限定符:1
auto vals2 = makeWidget().data();
1
2
3
4
5
6
7
8DataType data() &&{
return std::move(values); //此时触发移动拷贝
}
//左值版本也修改成左值限定符:
DataType& data() &{
return values;
}
因为有可能人工破坏或者忘记是否符合6个重写条件,因此本条款的核心是建议派生类的重写都需加上override关键字,当重写失败时编译器会报错,而且override仅在函数名后会被解析为关键字,意味着作为函数名称时也不会报错:
1
2
3void override(){ //ok
...
}
条款13:优先考虑使用const_iterators而非iterators
const_iterator的const含义同pointer-to-const,指向常量的指针(即常量指针),当我们没必要修改迭代器指向的值时可以考虑使用。
在C++98中,const_iterator的支持是非常不完善的,这样的代码可能不会通过编译:
1
2
3
4
5
6typedef std::vector<int>::iterator IterT;
typedef std::vector<int>::const_iterator ConstIterT;
std::vector<int> value{1, 2, 3};
ConstIterT it = std::find(static_cast<IterT>(value.begin()), static_cast<IterT>(value.end()), 4);
value.insert(static_cast<IterT>(it), 4);static_cast,就算是reinterpret_cast,也无法找到从const_iterator转换到iterator的方法,因此会导致编译失败;
而C++
11的find和insert都很好地兼容了const_iterator,尽管是non-const容器,通过cbegin、cend、crbegin和crend等:
1
2auto it = std::find(value.cbegin(), value.cend(), 4);
value.insert(it, 4);
C++
11唯一没弥补的遗憾仅支持std::begin、std::end,不支持cbegin,cend,rbegin,rend,crbegin,crend等,在C++
14才完善了这块的支持,但是这块的实现也不难,例如通过std::begin间接支持std::cbegin:
1
2
3
4template <class C>
auto cbegin(const C& container)->decltype(std::begin(container)){
return std::begin(container);
}const_iterator,C++
11支持下(加入编译参数"-std=c++11"),仅可以写成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
using namespace std;
template<typename T>
auto cbegin(const T& container)->decltype(std::begin(container)){
return std::begin(container);
}
template<typename T>
auto cend(const T& container)->decltype(std::end(container)){ //不支持C++14,也无法写成decltype(auto)
return std::end(container);
}
template <typename T>
void getInterator(const T& container){
auto begin = cbegin(container); //C++ 14则可以直接使用std::cbegin和std::cend
auto end = cend(container);
cout << *begin << *(--end) << endl;
}
int main(){
std::vector<int> value{1, 2, 3};
getInterator(value); //输出1 3
cout << "done" << endl;
return 0;
}
条款14:如果函数不抛出异常请使用noexcept
条款提到了三个方面,当确信函数不会抛出异常时,应该使用noexcept声明:
编译器生成的代码更加优化:不同于C++98的异常声明
throw()行为,C++ 11的noexcept在展开调用栈和可能展开调用栈行为很不同,直白的说,使用noexcept,C++ 11可能会直接调用std::terminate()终止程序,不会保证资源被反序析构,意味着运行时调用栈不用处于可展开状态,而C++ 98的则需要保证,因此灵活性优化实际不如C++ 11 :1
2int f(int x) throw(); //C++98写法,较少优化
int f(int x) noexcept; //C++11,极尽所能的优化移动操作的必要;许多STL接口遵循"如果可以则移动,如果必要则复制"策略,例如
std::vector::push_back、std::vector::reserve、std::deque::insert等,这些接口要求被处理对象声明noexcept时,才会真正进行移动操作,否则可能出现如果移动第n+1个对象抛出异常,前n个对象既无法复原、也无法继续移动的窘境。noexcept会依赖于成员组件的noexcept特性;例如一个Widget数组是否noexcept,取决于组成这个数组的Widget对象是否noexcept,如果低层次对象不保证noexcept,那么高层次抽象也不会保证noexcept;
但注意,不应该为了追求noexcept性能,盲目将函数声明为noexcept,大部分函数是异常中立函数(exception-neutral),这些函数自己不会抛出异常,但是其内部的函数可能会丢出异常。此外,析构函数,内存释放函数(operator delete/operator delete[])本身是隐式noexcept的。
条款15:尽可能地使用constexpr
对于变量而言,constexpr的含义就是const特性+编译期确定特性,当一个变量编译期确定且不再修改时,应该声明为constexpr。
constexpr函数则有点特殊,请记住:
constexpr的函数实参如果编译期确定,那么将在编译期运行;如果constexpr的实参并非编译期可知,并且处于需求编译期常量上下文,那么代码编译会失败;
尽管constexpr函数的值编译期不可知,constexpr会退化成普通函数,不会导致编译失败;
咋一看1和2好像非常矛盾,编译期不可知时究竟编译成不成功,关键在于constexpr的函数是否被用于需求编译期常量的上下文,例如:
1
2
3
4
5
6int x = 5;
constexpr int square(int n){
return n*n;
}
int y = square(x); //ok1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//全都报错!
std::array<int, square(x)>
template <int N>
struct Person(){
...
};
Person<square(x)> p;
case square(x):
constexpr int y = square(x);
enum class Color{
Blue = square(x),
...
}1
2
3
4
5
6
7
8class Person{
public:
constexpr void setNum(double newNum) noexcept{ //ok
num = newNum;
}
private:
num = 0;
};
条款16:让const成员函数线程安全
此条款强调const成员函数可能只是考虑其一般并发使用,因为不常修改成员变量,而如果需要引入缓存机制来修改变量,也是可以,变量加mutable即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Widget {
public:
…
int magicValue() const
{
if (cacheValid) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cachedValue = val1 + val2; //有点问题
cacheValid = true;
return cachedValid;
}
}
private:
mutable std::atomic<bool> cacheValid{ false };
mutable std::atomic<int> cachedValue;
};
重点不是这个,虽知std::atomic开销低于互斥锁,但是两个原子量需要赋值更新时是有问题的,上面的代码可能出现赋值更新,但是因为没有马上置为true,另一个线程会重新进行计算;先置true,再赋值,问题更大,完全可能返回一个未完成赋值的变量。
因此两个单元及以上的线程安全,还是建议使用互斥锁: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Widget {
public:
…
int magicValue() const
{
std::lock_guard<std::mutex> guard(mtx);
if (cacheValid) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cachedValue = val1 + val2; //有点问题
cacheValid = true;
return cachedValid;
}
}
private:
mutable std::mutex mtx;
mutable bool cacheValid{ false };
mutable int cachedValue;
};
条款17:理解特殊成员函数的生成
在C++ 98中,编译器自动生成的四个函数是默认构造函数、析构函数、拷贝构造函数、拷贝赋值运算符,它们是隐式public、inline且非虚的,唯一的例外是作为派生类且继承父类的虚析构函数。
C++ 11又引入了两种生成函数:移动构造函数和移动赋值运算符函数,如:
1
2
3
4
5class Widget{
public:
Widget(Widget&& rhs);
Widget& operator=(Widget&& rhs);
};
用户单独定义移动构造或者移动赋值,都会导致两个移动函数不会自动生成,拷贝也不会生成;而在拷贝中,定义拷贝构造不影响拷贝赋值的生成,定义拷贝赋值也不影响拷贝构造的生成;
用户单独定义了拷贝构造或拷贝赋值,移动函数也不会生成;
用户单独定义了析构函数,移动函数不会生成,但拷贝函数仍然可以生成,但被废弃;根据Rule of Three原则,析构函数、拷贝构造、拷贝赋值运算符函数,三个函数任意定义一个,应当同时自定义另外两个,现在也应该提供移动函数的定义。
如果你自定义了析构函数,还想继续使用默认生成的拷贝或者移动函数,可以使用default,最常用是在多态类中:
1
2
3
4
5
6
7
8
9
10class Base{
public:
virtual ~Base() = default; //虚析构也是属于你自定义的
//因此应当声明default:
Base(Base&&) = default; //支持移动
Base& operator=(Base&&) = default;
Base(const Base&) = default; //支持拷贝
Base& operator=(const Base&) = default;
};
第四章 智能指针
原始指针存在若干问题:
无法确认指针是单个对象还是数组对象,需要区分使用delete还是delete[],用错都是UB;
无法确认指针是否野指针/悬空指针;
需要知道使用什么析构还是delete直接删除;
没delete、多次delete都会造成问题;
C++ 11存在四种智能指针:std::unique_ptr、std::shared_ptr、std::weak_ptr和std::auto_ptr;std::auto_ptr,但最后一种属于C++98末期的产物,C++ 11后可以被std::unique_ptr完美替代。
条款18:独占资源使用std::unique_ptr
std::unique_ptr典型的使用是工厂函数返回一个指针,该工厂下含有三个子类:

调用者只需使用该对象,std::unique_ptr在自己销毁时会释放资源:
1
2
3
4
5
6
7template<typename... Ts>
std::unique_ptr<Investment> makeInvestment(Ts&&... params){ //参数为构造指针所需实参
...
}
//调用:
auto pInvestment = makeInvestment(arguments); //1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17auto delInvmt = [](Investment* pInvestment){
makeLogEntry(pInvestment); //打印日志
delete pInvestment;
}
template<typename... Ts>
std::unique_ptr<Investment, decltype(delInvmt)> makeInvestment(Ts&&... params){
std::unique_ptr<Investment, decltype(delInvmt)> pInv(nullptr, delInvmt);
if(/*一个Stock对象应被创建*/){
pInv.reset(new Stock(std::forward<Ts>(params)...));
}else if(/*一个Bond对象应被创建*/){
pInv.reset(new Bond(std::forward<Ts>(params)...));
}else if(/*一个RealEstate对象应被创建*/){
pInv.reset(new RealEstate(std::forward<Ts>(params)...));
}
return pInv;
}virtual ~Investment(),以调用子类析构来析构子类对象。
且注意,一般而言std::unique_ptr和一般的指针占用大小相当,但是如果使用了自定义删除器,智能指针的大小可能产生大尺寸膨胀。
再者,std::unique_ptr也可以指向原始数组指针,类似std::unique_ptr<T[]>,但因为智能指针结合vector等使用更加现代化,使用数组指针唯一的用处是意欲获取C风格数组对象的所有权。
最后std::unique_ptr能隐式且快速转换成共享指针: 1
std::shared_ptr<Investment> sp = makeInvestment(arguments);
条款19:对于共享资源使用std::shared_ptr
std::unique_ptr不支持拷贝语义,仅支持移动语义,而std::shared_ptr允许拷贝,拷贝的结果是增加指针的引用计数,引用计数大部分实现都是使用原始指针指向计数资源,因此std::shared_ptr大小是原始指针的两倍。
除了这些差异,一个细节是std::shared_ptr声明自定义删除器时删除器类型不属于智能指针的类型,这点和std::unique_ptr有别:
1
2
3
4
5
6
7
8
9auto loggingDel = [](Widget *pw){ //自定义删除器
makeLogEntry(pw);
delete pw;
};
//删除器类型是指针类型的一部分
std::unique_ptr<Widget, decltype(loggingDel)>upw (new Widget, loggingDel);
//删除器类型不是指针类型的一部分
std::shared_ptr<Widget> spw(new Widget, loggingDel); 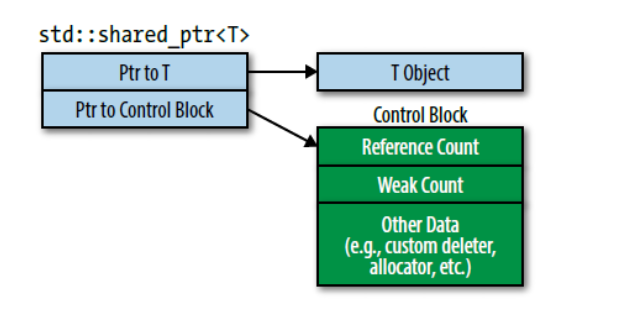
控制块的创建遵循以下规则: 1. 使用std::make_shared构造std::shared_ptr,总是会创建新的控制块;
从std::unique_ptr构造std::shared_ptr也会创建新的控制块,且独享指针会被置null代表控制权转移;
从原始指针上构造std::shared_ptr,会创建新的控制块;因此不建议使用原始指针构造共享指针,两次构造会导致一个原始指针含两个引用计数,从而销毁两次,造成UB;
1
2
3auto pw = new Widget;
std::shared_ptr<Widget> spw1(pw, loggingDel);
std::shared_ptr<Widget> spw2(pw, loggingDel); //二次构造,危险!从std::shared_ptr或者std::weak_ptr构造std::shared_ptr,不会创建新的控制块,因为它可以依赖传递而来的控制块;
由于第三点原因,尤其推荐使用std::make_shared构造共享指针,但如果使用自定义删除器就无法使用std::make_share了,可以写成:
1
2std::shared_ptr<Widget> spw1(new Widget, loggingDel); //在智能指针里面new
td::shared_ptr<Widget> spw2(spw1); //继承spw1的控制块1
2
3
4
5
6
7
8class Widget{
public:
void process(){
processedWidgets.emplace_back(this); //危险!
}
private:
std::vector<std::shared_ptr<Widget>> processedWidgets;
};1
2
3
4
5
6class Widget:public std::enable_shared_from_this<Widget>{
public:
void process(){
processedWidgets.emplace_back(shared_from_this());
}
};
最后要知道的是,std::shared_ptr不支持原始数组即std::shared_ptr<T[]>,也不能直接转换到std::unique_ptr;
条款20:当std::shared_ptr可能悬空时使用std::weak_ptr
std::weak_ptr不是独立的智能指针,而是std::shared_ptr的强化。
std::weak_ptr的第一个作用是在不增加std::shared_ptr引用数时,检查std::shared_ptr指向的对象是否仍然存在,如果指针悬空被称为弱引用过期,如:
1
2
3
4
5
6
7auto spw = std::make_shared<Widget>();
std::weak_ptr<Widget> wpw(spw);
spw = nullptr; //弱引用过期
if(wpw.expired()){
...
}1
std::shared_ptr<Widget> spw1 = wpw.lock();
1
2
3
4
5
6
7
8
9
10
11
12
13std::shared_ptr<const Widget> fasrLoadWidget(WidgetId id){
static std::unordered_map<WidgetID, std::weak_ptr<const Widget>> cache;
auto it = cache.find(id);
if(it != cache.end()){
auto objPtr = it->second.lock();
if(objPtr)
return objPtr;
cache.erase(it); //清理过期弱引用
}
auto objPtr = loadWidget(id);
cache[id] = objPtr;
return objPtr;
}
另一个弱引用典型使用是解除循环引用,在此前文章提过,不赘述;
条款21:优先考虑std::make_unique和std::make_shared而非使用new
使用make而不是new有若干好处:
make的异常安全性更好,例如在一个类的构造中:
构造会分成三步进行,首先new出Widget内存,然后执行computePriority计算优先级,最后绑定共享指针构造Widget,二三步的顺序可能对换,无论如何,后面两步发生异常时,new方法会导致内存泄漏,而对于make方法,如果先执行共享指针构造,那么将保证指针中对象有效,如果先执行computePriority函数,如果异常make方法能保证Widget资源析构,无论如何不会造成内存泄露;1
2
3processWidget(std::shared_ptr<Widget>(new Widget), computePriority());
processWidget(std::make_shared<Widget>(), computePriority());对make_shared而言,产生更少内存开销;make_shared分配的内存是一次性的,而new方法对象和控制块内存是分离的,更加占用程序空间。
但make方法不能替代所有场景的new方法,例如对于make_unique,至少两种场景受到限制:
前述条款所述,自定义删除器时需要使用new;
在条款7也提过,当使用花括号初始化时,你只能使用new或者曲线使用make,因为圆括号在容器中是n个m对象,而不是n和m对象:
1
2
3
4auto spv = std::make_shared<std::vector<int>>(new std::vector<int>{10, 20});
auto initList = {10, 20};
auto spv = std::make_shared<std::vector<int>>(initList);
对于make_shared,除了这两个场景,还有额外两个场景不能使用make:
不要使用make_shared去重载operator new和operator delete,后者new和delete都是默认sizeof(T)空间,使用make方法改变了内存布局和大小,在一些情况下会出现不兼容问题;
不希望使用连续空间时;虽然make_shared使用连续空间分配提高了程序性能和内存表现,但是其真正释放的时机取决于弱引用计数(通常情况下取决于是否还有weak_ptr指针引用这块内存),而new方法,只要引用计数为0(没有shared_ptr引用),对象内存优先释放,仅留下控制块内存等待弱引用归零。
因此,如何使用new、又避免内存泄露就成了下个问题,其实就是正常人的写法:
1
2std::shared_ptr<Widget> spw(new Widget); //先构造指针
processWidget(spw, computePriority()); //后构造对象1
processWidget(std::move(spw), computePriority());
条款22:当使用Pimpl与std::unique_ptr,在实现文件定义特殊成员函数
Pimpl(Pointer to
implementation)惯用法是在类的头文件定义中使用结构体或者类指针指向其他类或成员变量,以减少引入的头文件以减少编译时间,例如一个Widget类的定义:
1
2
3
4
5
6
7
8
9class Widget{
public:
Widget();
~Widget();
...
private:
struct Impl; //成员类都放在这里面
Impl* pImpl;
}1
2
3
4
5
6
7
8
9
10
11
12
13
struct Widget::Impl{
std::string name;
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget():pImpl(new Impl){}
Widget::~Widget(){delete pImpl;}
C++ 11 Pimpl必须定义析构
换到C++
11,只需要使用智能指针替换原始指针,但注意:Pimpl惯用法必须声明析构函数(可以空实现)或者使用default行为,因为std::unique_ptr禁止默认析构函数删除一个不完整类型(此处头文件的Impl仅含声明,缺省定义就算一种不完整类型),会触发static_assert,因此实例化Widget无法通过编译,要通过编译,必须让函数在析构前看到结构体Impl的完整定义,因此需要写成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class Widget{
public:
Widget();
~Widget();
...
private:
struct Impl; //成员类都放在这里面
std::unique_ptr<Impl> pImpl;
}
//cpp文件:widget.cpp
struct Widget::Impl{
std::string name;
std::vector<double> data;
Gadget g1,g2,g3;
};
Widget::Widget():pImpl(std::make_unique<Impl>()){}
Widget::~Widget(){}
//或者
Widget::~Widget() = default;
C++ 11 Pimpl移动实现必须放在实现文件
切记条款17,定义析构函数会导致移动函数无法自动生成,其中重要原因之一是移动函数本身会含有销毁成员pImpl的代码事件,因此直接在头文件中定义移动函数的默认实现也有问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Widget{
public:
Widget();
~Widget();
//错误代码:移动函数析构了不完整类型
Widget(Widget&& rhs) = default;
Widget& operator=(Widget&& rhs) = default;
//正确写法:仅声明,default或者空实现放在cpp文件:
Widget(Widget&& rhs);
Widget& operator=(Widget&& rhs);
private:
struct Impl;
std::unique_ptr<Impl> pImpl;
};
C++ 11 Pimpl含move-only类型需手动实现拷贝
因为使用了std::unique_ptr这种类指针,编译器不会自动生成拷贝函数,就算生成也未必是我们想要的深拷贝,因此我们在Widget类中最好也定义自己的拷贝函数:
1
2
3
4
5
6
7
8Widget::Widget(const Widget& rhs) //拷贝构造函数
: pImpl(std::make_unique<Impl>(*rhs.pImpl)){}
Widget& Widget::operator=(const Widget& rhs) //拷贝operator=
{
*pImpl = *rhs.pImpl;
return *this;
}
第五章 右值引用 移动语义 完美转发
条款23:理解std::move和std::forward
实际上,std::move并不移动什么,而std::forward也不会转发什么,它们并不产生任何执行代码,它们本质只是一种执行转换的函数模板。而且,使用std::move和std::forward都不会保证必然调用移动操作而不是拷贝操作。
std::move
例如C++ 11的一种std::move实现: 1
2
3
4
5template<typename T>
typename remove_reference<T>::type&& move(T&& param){
using ReturnType = typename remove_reference<T>::type&&;
return static_cast<ReturnType>(param);
}
移动函数对象不允许const特性
注意移动函数和拷贝函数不同,是不带const特性的: 1
2
3
4
5
6
7
8
9class string{
public:
...
string(const string& rhs);
string& operator=(const string& rhs);
string(string&& rhs);
string& operator=(string&& rhs);
};1
2
3
4
5
6
7class Person{
public:
//实际上还是使用拷贝函数
explict Person(const string text):value(std::move(text)){...}
private:
string value;
};
std::forward<T>
std::move唯一能保证的事情是一定会返回一个右值引用,std::forward的特性是保留左右值特性,当传入右值时调用右值版本函数:
1
2
3
4
5
6
7
8void process(const Widget& lvalue);
void process(Widget&& rvalue);
template<typename T>
void logAndProcess(T&& param){
log(...);
process(std::forward<T>(param));
}
条款24:区分万能引用和右值引用
只有两种情况被归结于万能引用: 1
2
3
4
5template<typename T>
void f(T&& param); //万能引用
Widget&& var1 = Widget();
auto&& var = var1; //万能引用1
2
3
4
5auto timeFuncInvocation = [](auto&& func, auto&&... params){
record start time...
std::forward<decltype(func)>(func(std::forward<decltype(params)>)(params)...);
record end time...
}
另外一些类型推导可能被误认为是万能引用,实际上都是普通右值引用而已:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//STL T&&不算T&&
template <typename T>
void f(std::vector<T>&& param); //右值引用
//const特性不行
template <typename T>
void f(const T&& param); //右值引用
//模板是类确定而不是函数确定
template <typename T>
class Person
{
public:
void f(T&& x); //右值引用
};
条款25:对右值引用使用std::move,对通用引用使用std::forward<T>
std::move意味着无条件的右值引用转换,而std::forward是有条件的转换,毕竟完美转发绑定的不总是一个右值;右值引用仅可以绑定一个可移动对象:
1
2
3
4
5
6
7class Widget{
public:
Widget(Widget&& rhs):name(std::move(rhs.name)), p(std::move(rhs.p)){...}
private:
std::string name;
std::shared_ptr<SomeDataStructure> p;
};
更糟糕的是,在forward的场合误用move会有更严重效果,如:
1
2
3
4
5
6
7
8
9
10
11class Widget{
public:
template<typename T>
void setName(T&& newName){
//nmae = std::forward<T>(newName); //good
name = std::move(newName); //wrong
}
private:
std::string name;
};1
2
3
4auto n = getWidgetName();
Widget w;
w.setName(n); //n资源被移走了
... //接下来使用n都是一种UB1
2
3
4
5
6
7
8
9class Widget{
public:
void setName(const std::string& newName){
name = newName;
}
void setName(std::string&& newName){
name = std::move(newName);
}
};w.setName("Eden")时,需要构造一个临时的std::string对象,等待赋值完成再析构该中间对象,如果传入是其他类对象,性能差异会更大。
此外,最致命的差异是,如果要支持任意可变参数,模板和万能引用是唯一选择,而不能使用重载函数:
1
2
3
4
5template<class T, class... Args>
shared_ptr<T> make_shared(Args&&... args);
//调用
auto sptr = std::make_shared(1,2,3,"EdenMo",...);
当值返回函数返回右值引用绑定的对象时,使用std::move往往性能更高,例如:
1
2
3
4
5Matrix operator+(Matrix&& lhs, const Matrix& rhs){
lhs += rhs;
//return lhs; //slower
return std::move(lhs); //faster
}
而如果一个未规约返回类型的值返回函数返回的是万能引用绑定的对象,则使用std::forward,代表如果绑定对象是右值,就返回这个移动右值,反之为左值,则返回左值的拷贝:
1
2
3
4
5template <typename T>
Fraction reduceAndCopy(T&& frac){
frac.reduce();
return std::forward<T>(frac); //右值移动,左值拷贝
}
但是,不是所有值返回函数都应该使用std::move,例如这样的代码:
1
2
3
4
5Widget makeWidget(){
Widget w;
return w; //足够简洁了!
//return std::move(w); //不要这么写!
}
条款26:避免在万能引用上重载
一个赋值函数: 1
2
3
4
5std::multiset<std::string> names;
void logAndAdd(const std::string& name){
log(...);
names.emplace(name);
}
当类似这样调用: 1
2
3
4std::string petName("Darla");
logAndAdd(petName); //传递左值std::string
logAndAdd(std::string("Persephone")); //传递右值std::string
logAndAdd("Patty Dog"); //传递字符串字面值1
2
3
4
5
6std::multiset<std::string> names;
template <typename T>
void logAndAdd(T&& name){
log(...);
names.emplace(std::forward<T>(name));
}1
2
3
4void logAndAdd(int idx){
log(...);
names.emplace(idx2string(idx));
}1
2short x = 2;
logAndAdd(x);
这样的重载问题在类的构造中更加严重,例如: 1
2
3
4
5
6
7
8
9
10
11
12
13
14class Person{
public:
template<typename T>
explicit Person(T&& n): name(std::forward<T>(n)){} //完美转发
explicit Person(int idx): name(idx2string(idx)){}
//事实上,编译器还会生成:
Person(const Person& rhs);
Person(Person&& rhs);
private:
std::string name;
};1
2Person p("Eden");
auto clonep(p); //编译失败!1
2const Person p("Eden");
auto clonep(p); //现在调用的是拷贝构造了1
2
3
4
5
6//wrong function:
class Son:public Person{
public:
Son(const Son& rhs):Person(rhs){...} //调用了基类的完美转发函数
Son(Son&& rhs) : Person(std::move(rhs)){...} //还是基类的完美转发函数
};
因此,万能引用是一种贪婪函数,其匹配优先级高于其他提升匹配,不要基于一个万能引用函数进行重载,正确的方式会在条款27介绍。
条款27:替代万能引用重载方法
几种普通的方法: 1. 放弃重载;除了构造函数,其他函数可以换个名字避免重载;
- 传值,这是一种反直觉的方法,但条款41会告诉我们在知道拷贝时按值传递:
1
2
3
4
5
6
7
8
9
10
11class Person {
public:
explicit Person(std::string n) //代替T&&构造函数,
: name(std::move(n)) {} //std::move的使用见条款41
explicit Person(int idx) //同之前一样
: name(nameFromIdx(idx)) {}
…
private:
std::string name;
};
tag dispatch
更高阶的方法可以使用类型萃取排除,在C++
Generic
Programming:SFINAF与类型萃取中我们介绍过使用std::false_type和std::true_type自定义的萃取类型的方法,称标签分发(tag
dispatch),以下是我写的一个达成目的demo: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
using namespace std;
std::multiset<std::string> names;
std::vector<std::string> vp{
"Eden",
"Mike",
"Lucy"
};
template<typename T>
void logAndAddImpl(T&& name, std::false_type){
names.emplace(std::forward<T>(name));
}
void logAndAddImpl(int idx, std::true_type){
names.emplace(vp.at(idx));
}
template <typename T>
void logAndAdd(T&& key){ //按T类型决议
logAndAddImpl(std::forward<T>(key), std::is_integral<std::remove_reference_t<T>>());
}
int main(){
short s = 1;
int x = 2;
size_t u= 0;
logAndAdd(s);
logAndAdd(x);
logAndAdd(u);
logAndAdd("shit");
for(const auto& pos : names){
cout << pos << "\t "; //Eden Lucy Mike shit
}
cout << "done" << endl;
return 0;
}
enable_if
对于若干个重载函数,标签方法是没问题的,但是回到类的构造中,各自左值、引用特性、继承关系等会导致标签分发排除尤其复杂,因此可以采用条件编译的方法,我们的完美转发模板,禁用于那些Person相关的参数,以免优先匹配阻碍拷贝函数的运行,尤其注意相关处理手段:
去除cv特性,去除引用特性,std::decay能做到(而且数组、函数都会退化成指针);
禁用派生类参数以免子类调用父类转发模板,std::is_base_of能识别;
完整demo如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
using namespace std;
std::multiset<std::string> names;
std::vector<std::string> vp{
"Eden",
"Mike",
"Lucy"
};
class Person{
public:
template <typename T, typename = typename std::enable_if<
!std::is_base_of<Person, typename std::decay<T>::type>::value && //T是Person或者Person的派生类禁用完美转发
!std::is_integral<typename std::remove_reference<T>::type>::value>::type> //T是整数类型时禁用完美转发
explicit Person(T&& newName): name(std::forward<T>(newName)) {
cout << "This is forwarding" << endl;
}
explicit Person(int idx): name(vp[idx]){ //整数类型都应该匹配这个
cout << "This is int" << endl;
}
explicit Person(const Person& p):name(p.name){ //构造时应该使用拷贝构造
cout << "Person copy" << endl;
}
explicit Person(Person&& p):name(std::move(p.name)){
cout << "Person right value copy" << endl;
}
virtual ~Person() = default;
private:
std::string name;
};
class Son : public Person{
public:
Son():Person(0){}
Son(const Son& rhs): Person(rhs){ cout << "Son copy" << endl; }
Son(Son&& rhs):Person(std::move(rhs)){ cout << "Son right value copy" << endl; }
};
int main(){
Person p1("Eden"); //forwarding
Person p2(2); //This is int
size_t x = 0;
Person px(x); //This is int
auto p3(p1); //Person copy
auto p4(p2); //Person copy
Son s1; //This is int
auto s2(s1); //Person copy、Son copy
auto s3(Son{}); //This is int、Person right value copy、Son right value copy
cout << "done" << endl;
return 0;
}auto s3(Son{})这一行会被RVO,编译器会直接在s3内存构造对象,而不是使用移动构造,所以要显式看到右值的移动构造,需要使用编译参数-fno-elide-constructors禁用这个优化。
条款28:理解引用折叠(reference collapsing)
C++是没有引用的引用语义的,这样的代码会报错: 1
auto& &rx = x;
1
2
3
4template<typename T>
void func(T&& param);
func(w);
T和param任一类型为左值引用,那么引用折叠的结果就是左值引用;当引用都是右值引用时,结果才是右值引用;
std::forward<T>的工作机制实际上就是引用折叠的效果,例如std中std::forward<T>的一种大致实现如下:
1
2
3
4template<typename T>
T&& forward(typename remove_reference<T>::type& param){
return static_cast<T&&>(param);
}
当传入一个左值,如Widget, T会被推导为Widget&,于是引用折叠成:
1
2
3
4template<typename T>
Widget& forward(Widget& param){
return static_cast<Widget&>(param);
}当传入一个右值时,T被推导成非引用,即Widget,于是:
在1中,param被转发到一个左值引用,在2中,param被右值引用了,返回一个右值,它们都与std::forward的期望行为相当。1
2
3
4template<typename T>
Widget&& forward(Widget& param){
return static_cast<Widget&&>(param);
}
至此,万能引用的本质就清楚了:
根据类型推测T的左右值,只有传入右值时被推导为T,否则推导T&;
引用折叠生效;
有四种情况会产生引用折叠,模板推导和auto是其中两种,还有两种情况分别是:
使用typedef时:
当我们实例化模板时Widget<int&> w,引用折叠得到typedef int& RvalueRefToT;1
2
3
4
5
6template<typename T>
class Widget{
public:
typedef T&& RvalueRefToT;
...
};使用decltype时,如果推导产生引用的引用,会发生引用折叠。
条款29:假定移动操作不存在,成本高,不要使用
移动操作尤其快速的一个情况是,数据存储在堆中,移动操作所做的只需要将指向这些内容的指针拷贝到新对象中,然后将原指针置空,大部分STL的移动操作就是如此,这样的操作允许了在常数时间内进行移动:
1
2std::vector<Widget> vw1;
auto vw2 = std::move(vw1);
还有一些特殊情况,如std::string虽然提供了常数时间的移动操作和线性时间的拷贝操作,但许多std::string的实现使用了小字符串优化(small string optimization,SSO),当字符串长度小于15个字符时,这些字符串将被存储在缓存而不是堆区,移动这些内存并不比拷贝更快速。
C++ 11的标准库进行了大幅的修改以适应移动语义,当然条款14告诉我们当强大异常安全保证没有被提供时(没有声明noexcept),尽管移动操作更快,也可能进行拷贝,例如那些移动函数没有声明noexcept。
条款30:熟悉完美转发失败的情况
完美转发的含义是:被传递函数的目标与执行传递的那个源对象是同一个对象。这个含义排除了值传递的形参,因为它们是调用者传入的对象拷贝;也排除了指针形参,因为我们不希望强迫调用者传入指针对象。所以通常目的的转发,往往指的是引用对象。
另一方面,完美转发除了指对象本身,还转发它们的显著特性,例如左右值特性、const/volatile特性等,所以完美转发也一般使用万能引用。
可变参数的完美转发是很常见的,例如各种STL的emplace函数,智能指针的工厂函数std::make_unique、std::make_shared等:
1
2
3
4template<typename ...Ts>
void fwd(Ts&&... param){
f(std::forward<Ts>(params)...);
}
花括号初始器
假设f和fwd的定义如下: 1
2
3
4void f(const std::vector<int>& v);
f({1,2,3}); //ok,列表可隐式转换至std::vector
fwd({1,2,3}); // 错误,无法编译
其实这个原因在条款2就表明了,即模板推导无法推导std::initializer_list对象,如果使用你必须显式地指明,而auto与模板推导为数不多的区别就是auto是能够推导std::initializer_list的:
1
2auto il = {1,2,3};
fwd(il); //ok
NULL或者0
正如条款8描述,NULL和0都不是真正的指针类型,它们都不能作为空指针被完美转发。所以万能引用中的空指针参数必须使用nullptr;
只声明不定义的静态成员变量
在两年半前的C++记忆恢复集要之二:类与对象就知道:静态成员变量必须类内声明、类外提供定义,但事实上,如果不涉及使用静态成员变量的指针时,只使用声明也是ok的,编译器会将值直接展开到每一个使用num值的地方:
1 | class Person{ |
但是,如果使用了指针,必须提供类外定义,否则能通过编译,但是链接会报错:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Person{
public:
static const size_t num;
};
const size_t Person::num = 20; //注释掉此类外定义,f1函数报错
void f(const size_t num){
cout << "num = " <<num << endl;
}
void f1(const size_t* num){
cout << "num = " << *num << endl;
}
int main(){
f(Person::num);
f1(&(Person::num));
cout << "done" << endl;
return 0;
}
在万能引用这里情况也类似,因为万能引用中,底层对引用的操作实际上和指针是一致的,只是引用是一种可自动解引用的指针。
重载函数或模板函数
当传入一个重载函数时,f能够决议符合类型声明的那个重载对象,但是fwd本身是泛型模板,没有类型相关信息来参与决议:
1
2
3
4
5
6
7
8void f(int(*pf)(int))
//其实也等效于隐式指针写法:void f(int pf(int));
int processVal(int value); //#1
int processVal(int value, int priority); //#2
f(processVal); //ok,自动匹配#1
fwd(processVal); //无法编译!
模板函数也是类似: 1
2
3
4
5template<typename T>
T workOnVal(T param) //处理值的模板
{ … }
fwd(workOnVal); //错误!哪个workOnVal实例?1
2
3
4
5
6
7using ProcessFuncType = //写个类型定义;见条款9
int (*)(int);
ProcessFuncType processValPtr = processVal; //指定所需的processVal签名
fwd(processValPtr); //可以
fwd(static_cast<ProcessFuncType>(workOnVal)); //也可以
位域
当使用位域时,万能引用的转发会失败: 1
2
3
4
5
6
7
8
9
10
11
12
13struct IPv4Header {
std::uint32_t version:4,
IHL:4,
DSCP:6,
ECN:2,
totalLength:16;
};
void f(std::size_t sz); //要调用的函数
IPv4Header h;
…
f(h.totalLength); //可以
fwd(h.totalLength); //错误!
此处,fwd的形参是一个引用,h.totalLength是一个non-const位域,C++严禁将non-const位域绑定到引用,因为根本无法解引用,C++没办法创建一个可以指向任意bit的指针(最小的指针是8位的)。
位域可以传递的形参只有两种,一是值传递的形参,例如f函数那样,第二是const
T&,要挽救万能引用无法直接完美转发位域的简单方法是创建一个副本:
1
2auto length = static_cast<std::uint16_t>(h.totalLength);
fwd(length); //转发这个副本
第六章:Lambda表达式
第六章:Lambda表达式
条款31:避免使用默认捕获模式
引用捕获是Lambda表达式的默认捕获模式,但使用引用捕获容易导致变量过期导致UB:
1
2
3
4
5
6
7
8
9
10
11
12
13using FilterContainer = std::vector<std::function<bool(int)>>;
FilterContainer filters;
void addDivisorFilter()
{
auto calc1 = computeSomeValue1();
auto calc2 = computeSomeValue2();
auto divisor = computeDivisor(calc1, calc2);
filters.emplace_back( //危险!对divisor的引用
[&](int value) { return value % divisor == 0; } //将会悬空!
);
}1
2
3
4
5
6
7
8
9
10
11
12
13void addDivisorFilter()
{
static auto calc1 = computeSomeValue1(); //现在是static
static auto calc2 = computeSomeValue2(); //现在是static
static auto divisor = //现在是static
computeDivisor(calc1, calc2);
filters.emplace_back(
[=](int value) //什么也没捕获到!
{ return value % divisor == 0; } //引用上面的static
);
++divisor; //调整divisor
}
条款32:使用初始化捕获来移动对象到闭包中
有时候,按值捕获和按引用捕获都不是你想要的方式,如果你更希望通过移动操作,或者如果你有一个只能被移动的对象想要放入闭包中,C++11无法实现,但C++14支持了新的捕获机制来支持移动捕获,这种方式称为初始化捕获(init
capture)或者通用lambda捕获(generalized lambda
capture),例如将一个std::unique_ptr移动到闭包的方法: 1
2
3
4
5auto pw = std::make_unique<Widget>();
auto func = [pw = std::move(pw)]{
return pw->...;
}1
2
3auto func = [pw = std::make_unique<Widget>()]{
return pw->...;
}1
2
3
4
5
6
7
8
9
10
11
12
13class IsValAndArch{
public:
using DataType = std::unique_ptr<Widget>;
explicit IsValAndArch(DataType&& ptr):pw(std::move(ptr)){}
bool operator()()const{
return pw->...;
}
private:
DataType pw;
};
auto func = IsValAndArch(std::make_unique<Widget>())();
如果在C++
11中坚持使用lambda来实现对右值的移动,最接近的方式是使用std::bind:
1
2
3
4
5std::vector<int> data;
auto func = std::bind([](const std::vector<int>& data)mutable{ //注意不是std::vector<int>&& data
data = ...
}, std::move(data));
闭包本身产生的operator()默认是const,防止篡改数据成员,因此加上mutable将产生非const的operator();
此处最困惑的地方是为什么std::bind的参数不使用右值引用而是左值引用,要注意,std::bind内部的对象是左值对象,对于传入一个左值实参,这个对象构造是来自拷贝构造,而对于传入上述类似的右值实参,这个对象来自移动构造。
如果在C++ 14中,实现简单一些: 1
2
3
4std::vector<int> data;
auto func = [data = std::move(data)]{
data = ...
};
条款33:对于std::forward的auto&&形参使用decltype
泛型lambda函数是C++
14中最值得期待的新特性之一,因为现在在lambda函数中能够使用auto关键字:
1
2
3auto f = [](auto x){
return func(normalize(x));
};1
2
3
4
5
6
7class SomeCompilerGeneratedClassName{
public:
template<typename T>
auto operator()(T x) const{
return func(normalize(x));
}
};1
2
3auto f = [](auto&& x){
return func(normalize(std::forward<???>(x)));
};std::forward<T>,而是:
1
2
3auto f = [](auto&& x){
return func(normalize(std::forward<decltype(x)>(x)));
};
那么问题就来了,decltype好像不能把右值特性完美转发到std::forward,但参考条款28对std::forward的实现,我们会发现右值和右值引用对std::forward转发效果是一致的:
1
2
3
4template<typename T>
T&& forward(remove_reference_t<T>& param){ //C++ 14 std::forward的实现
return static_cast<T&&>(param);
}1
2
3Widget&& forward(Widget& param){ //C++ 14 std::forward的实现
return static_cast<Widget&&>(param);
}1
2
3Widget&& && forward(Widget& param){
return static_cast<T&& &&>(param);
}1
2
3Widget&& forward(Widget& param){
return static_cast<T&&>(param);
}
条款34:考虑lambda表达式而非std::bind
std::bind并不是全新的产物,C++ 11中的bind是C++ 98的std::bind1st和std::bind2nd的后续,其在2005年加入了命名空间std::tr1::bind,尽管接口细节与C++ 11有所不同;但C++ 11起,lambda几乎是比std::bind更好的选择;
理由一:lambda比std::bind更易读
假设有这样的一种设置闹钟函数,我们先进行一些类型定义:
1
2
3
4
5using Time = std::chrono::steady_clock::time_point; //时间类型
enum class Sound{Beep, Siren, Whistle}; //声音类型
using Duration = std::chrono::steady_clock::duration; //时长类型
设计一个一小时后响30秒的闹钟,通过参数来指定闹钟声音类型,lambda C++
11的写法很简单: 1
2
3
4auto setSound = [](Sound sound){
using namespace std::chrono;
setAlarm(steady_clock::now() + hours(1), sound, seconds(30));
};1
2
3
4
5auto setSound = [](Sound sound){
using namespace std::chrono;
using namespace std::literals;
setAlarm(steady_clock::now() + 1h, sound, 30s);
};
而如果使用std::bind,因为占位符的缘故,用户传入类型时并不知道占位符对应的类型,他们必须自行查阅setAlarm的参数类型:
1
2
3using namespace std::chrono;
using namespace std::literals;
auto setSound = std::bind(setAlarm, steady_clock::now() + 1h, std::placeholders::_1, 30s); //还不完全正确
理由二:时间参数计算时间不对
如上的写法,auto setSound = std::bind(setAlarm, steady_clock::now() + 1h, std::placeholders::_1, 30s);中的steady_clock::now()传递给的是std::bind,而不是setAlarm,因此该时刻会从std::bind时开始计算,而不是setAlarm真正被调用时。
而lambda时间会从setAlarm被调用时才设置,这种情况要std::bind获取正确的时间参数,必须依赖std::plus。
std::plus本质是定义在<functional>一个仿函数,其实现类似:
1
2
3
4
5struct plus{
auto operator()(auto a, auto b){
return a+b;
}
};1
2
3
4
5
6
7
8
9int a = 2;
int b = 3;
std::plus<int> adder_int; //只能加int
int c = adder_int(a,b);
//C++ 14后:
double a = 2.2f;
double b = 3.3f;
auto c = std::plus<>()(a,b);
此处,std::bind要实现时间延迟,就要向调用对象传入std::plus这样的参数,再嵌套一层std::bind:
1
auto setSound = std::bind(setAlarm, std::bind(std::plus<>(), steady_clock::now(), 1h), std::placeholders::_1, 30s);
理由三:std::bind不能区分调用对象的重载版本
如果setAlarm除了该三参数函数,还有一个四参数的重载版本,lambda是能够通过编译的,但std::bind的编译会失败,要std::bind能够通过编译,必须通过函数指针转换:
1
2using setAlarm_3params = void(*)(Time t, Sound sound, Duration duration);
auto setSound = std::bind(static_cast<setAlarm_3params>(setAlarm), std::bind(std::plus<>(), steady_clock::now(), 1h),std::placeholders::_1,30s);
理由四:std::bind产生代码可能较弱性能
由于理由三,在重载版本时引入了函数指针,参数传递经过函数指针,这种写法不太可能产生可内联的代码,而lambda的参数被捕获到闭包中,因此lambda执行速度往往更高。
std::bind传值特性
因为std::bind没有lambda哪种显式表明对象和参数传值特性的特点,因此我们只能记住它的工作方式,即:在std::bind绑定可调用对象时,传入的对象都是值传递,而调用时传入的参数,都是引用传递的(此类函数调用运算符使用了完美转发),如一个压缩类:
1
2
3
4
5
6enum class Compress_level{Low, Normal, High};
Widget compress(const Widget& w, Compress_level level);
Widget w;
auto func = std::bind(compress, w, std::placeholders::_1); //绑定时,w是值传递
func(Compress_level::High); //调用时,Compress_level是引用传递
C++ 11 std::bind还值得用的两个用例
在C++ 14后,几乎没有用例表明std::bind比lambda更优越,但对于C++ 11,std::bind有两个用例:
其一是条款32中提到的,lambda和std::bind能够模拟一种移动对象的lambda实现。
其二比较复杂,如果需要包装的对象是多态对象(如模板),使用std::bind能够产生可调用对象,如这样一个对象类:
1
2
3
4
5
6
7class PolyWidget{
public:
template<typename T>
void operator()(const T& param){
...
};
};1
2PolyWidget p1(1995);
PolyWidget p2("I am spider man");1
2
3
4
5
6PolyWidget pw;
auto bindpw = std::bind(pw, std::placeholders::_1);
...
bindpw(1995);
bindpw("I am spider man");
在C++ 11中无法使用类似的lambda实现,在C++ 14中可以,因为直到C++
14,lambd才支持参数模板推导: 1
2
3auto bindpw = [pw](const auto& param){ //维持了和std::bind一样的传值特性
pw(param);
};
回调指针:
1
2
3
4
5
6
7
8
9
10
11
12
13
14void doProcessAsync(std::function<Widget(Compress_level)> callback);
//原始函数
Widget compress(const Widget& w, Compress_level level);
Widget w;
//std::bind提早绑定对象w
auto bindfunc = doProcessAsync(std::bind(compress,w, std::placeholders::_1));
//C ++14 lambda
auto bindfunc = doProcessAsync([w](Compress_level level){
return compress(level);
});动态绑定,缩减参数(绑定不同对象,统一容器调用):
对比普通调用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Compressor {
public:
template<typename T1, typename T2>
Widget operator()(T1&& w, T2&& lev) {
return compress(w, lev);
}
};
Widget w1, w2, w3;
auto compress1 = [w1](CompLevel lev) { return compress(w1, lev); };
auto compress2 = [w2](CompLevel lev) { return compress(w2, lev); };
auto compress3 = [w3](CompLevel lev) { return compress(w3, lev); };
std::vector<std::function<Widget(CompLevel)>> compressors = {
compress1, compress2, compress3
};
Compressor comp;
for (auto& comp : compressors) {
comp(CompLevel::High); // 每个都压缩不同的 widget
}1
2
3
4Compressor comp;
comp(w1, CompLevel::High);
comp(w2, CompLevel::High);
comp(w3, CompLevel::High);
第七章:并行API
C++ 11的伟大标志之一是将并发整合到语言和库中,从C++ 11 新特性总结(三):多线程编程可知,C++ 11引入了五个头文件支持并发编程,不同于pthreads或者Windows threads,C++ 11的并发支持是约束在编译器层面的,因此使用者能够通过标准库写出跨平台多线程程序。
条款35:优先基于任务编程而不是基于线程
如果开发者想要执行一个异步任务,通常有两种方法。
其一是通过创建线程std::thread执行;其二是将任务传递给std::async,作为任务策略执行;
第二张基于任务的方法通常比基于线程的方法更优,其原因在于:
- std::async对返回值更友好,能够容易通过std::async返回的future对象提供的get函数获取这个返回值;而如果任务异常,get函数能够提供抛出异常的访问,线程也能够被直接终止(本质是通过std::terminate),而线程对于这些返回值、异常都无能为力;
C++并发中,thread被总结了三种含义:
硬件线程(Hardware threads): 真实执行的线程,现代计算机体系结构为每个CPU核心提供一个或者多个硬件线程;
软件线程(Software threads): 亦称系统线程,指操作系统管理的在每个硬件线程上执行的线程,一般数量比硬件线程更多,因为线程被IO、锁、条件变量阻塞时,操作系统可以为其他未阻塞软件线程提供吞吐量;
std::threads是C++被执行时的对象,本质是一种软件线程句柄(handle);其存在多种状态:
null表示空句柄,处于默认构造状态,不对应任何软件线程也没有任务执行;
moved from(moved to对应的软件线程开始执行),但注意:
1
2
3
4
5
6
7
8
9
10
11std::thread t1(task);
std::thread t2(task);
std::thread t3;
std::thread t4(task);
t2 = std::move(t1); //error!
t3 = std::move(t1); //ok
t4.join();
t4 = std::move(t1); //okjoined: 连接唤醒和被唤醒的两个线程;
detached表示两个连接的线程分离;
所以,原因之二是:
- 软件线程是有限的资源,如果开发者试图创建大于系统支持的线程数量,会抛出std::system_error异常,即使编写的代码被声明为noexcept,仍然抛出异常:
即使没有超出系统线程限额,但线程并行的本质是系统将硬件核心时间切片,然后为每个软件线程分配,当线程时间片耗尽,会切换到另一个线程执行,线程的切换涉及上下文切换,如果再发生硬件核心漂移(指的是指令、数据缓存没有命中,比如前一个线程使用数据很少,或者被新线程数据覆盖),切换开销很大;
1
2int doAsyncWork() noexcept;
std::thread t(doAsyncWork); //线程不足,一样抛出异常
而软件线程和硬件线程的最佳比例取决于软件线程的执行频率,如果IO密集型线程转换成计算密集型线程,那么这个比例也会变化,cpu cache的性能也会造成一些影响,而std::async将这种调校比例的事情隐藏于标准库中,应用层无需过多考虑;
也因此,std::async不保证创建线程,只保证任务的执行,在一些gui程序中,这样的特性可能带来响应变慢,因此可以使用std::launch::async选项向std::async传递调度策略保证任务在不同线程上执行。
标准库作者使用了比较前沿的线程调度算法,涉及窃取算法、线程池等,这些给使用std::async的开发者带来回报;
但也存在一些场景使用std::thread更有优势:
需要访问非常基础的线程API;C++ thread提供了底层系统级线程的API访问,如native_handle获取线程句柄,在Windows平台返回HANDLE,在Linux平台返回pthread:
1
2std::thread t([]{ /* some work */ });
auto handle = t.native_handle();需要自行实现线程池、线程调度等场景;
条款36:确保异步为必须时,才指定std::launch::async
std::async提供两种线程调度选项:
std::launch::async: 任务必须异步执行,即一定会在不同的线程被执行;
std::launch::deferred: 当且仅当调用get()或者wait()尝试获取执行结果时,任务才会被执行,意味着任务会被延迟到需要获取结果时才执行,而如果一直不调用get或者wait,任务不会被执行,包括使用wait_for/wait until接口,都不会触发执行。
有意思的是,std::async的默认模式不是二者其中之一,而是二者都用了,这种写法是等效的:
1
2auto func = std::async(f);
auto func = std::async(std::launch::async | std::launch::deferred, f);
无法保证是否有新线程创建执行任务;
无法保证任务是否被立刻执行;
如果不能保证wait和get被调用,无法保证任务是否被执行;
所以使用默认模式,有可能造成deferred相同的阻塞问题: 1
2
3
4
5
6
7
8
9
10//wrong code:
using namespace std::literals;
void f(){
...;
}
auto func = std::async(f);
while(func.wait_for(100ms) != std::future_status::ready){ //f可能永远不被执行,始终返回std::future_status::deferred
......
}1
2
3
4
5
6
7
8
9
10
11
12
13
14using namespace std::literals;
void f(){
...;
}
auto func = std::async(f);
if(func.wait_for(0s) == std::future_status::deferred){ //deferred模式
func.wait();
...
}
else{ //async模式
while(func.wait_for(100ms) != std::future_status::ready){
......
}
}
线程本地变量
使用默认模式的std::async,另一个重要的点是不能使用线程本地变量,因为两种模式会产生不同的效果,线程本地变量(thread-local
storage,TLS)是比较小众的概念,但它也不是什么很崭新的对象,C++
11引入了thread_local关键字来支持,其可以用于修饰局部变量、全局变量和类静态变量等,被用于线程间隔离,每个线程有自己独立的变量副本,如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
using namespace std;
//全局线程本地变量
thread_local int cnt = 0;
void func(){
while(cnt < 10){
cnt ++ ;
cout << "Thread 2: " << cnt << endl;
}
}
void func1(){
while(cnt < 10){
cnt ++ ;
cout << "Thread 3: " << cnt << endl;
}
}
int main(){
cnt = 5;
func();
auto fut = std::async(std::launch::deferred, func);
std::async(std::launch::async,func1);
fut.wait(); //使deferred执行
cout << "done" << endl;
return 0;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Thread 2: 6
Thread 2: 7
Thread 2: 8
Thread 2: 9
Thread 2: 10
Thread 3: 1
Thread 3: 2
Thread 3: 3
Thread 3: 4
Thread 3: 5
Thread 3: 6
Thread 3: 7
Thread 3: 8
Thread 3: 9
Thread 3: 10
由于deferred不能保证会另起线程执行,因此线程本地变量有可能使用主线程的初始化,产生不同结果。
故总的来说,满足以下条件,可以使用std::async的默认模式:
任务不一定迫切需要并行处理;
不会读写本地的线程本地变量;
能够保证调用wait或者get,或者能够接受函数不被执行的结果;
使用wait_for或者wait_until时考虑deferred状态;
否则,都需要使用std::launch::async调度模式;
条款37:保证std::thread在所有路径上最终均是unjoinable
本条款主要描述了使用std::thread后要让其进入unjoinable状态。
每个std::thread对象都在joinable和unjoinable两种状态之一:
joinable:正在运行的线程、被blocked或者等待调度线程,甚至运行结束的线程都可以认为是joinable的;
unjoinable:默认构造的线程(还没有绑定函数执行)、被moved-from的线程、joined的线程、detached的线程,均属于unjoinable;
std::thread如此重视是否joinable的重要原因是,当连接状态的析构函数被调用,执行逻辑会被终止。
如以下是一个用例,filter函数接受一个参数maxVal,执行0到maxVal的值过滤,满足一定条件,这些过滤值能够被某些逻辑计算,过滤和计算都是耗时操作,因此引入并发是合理的行为,而且我们希望自行管理线程优先级,这需要获取底层句柄,因此只能使用std::thread而不是std::async:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//wrong code:
constexpr auto tenMillion = 10000000;
bool doWork(std::function<bool(int)>filter, int maxVal = tenMillion)
{
std::vector<int> goodVals;
std::thread t([&filter, maxVal, &goodVals](){
for(auto i=0; i<maxVal; i++){
if(filter(i)) goodVals.push_back(i);
}
});
auto thread_handle = t.native_handle();
... //set priority
if(conditionsAreStatisfied()){
t.join();
performComputation(goodVals);
return true;
}
return false;
}1
constexpr auto tenMillion = 10'000'000;
先构造了t再设置优先级是一种无效设置,但这不是本条款重点,在条款39中会介绍如何在挂起一个线程;
最主要的问题是,当conditionsAreStatisfied返回假时,t的析构被调用,程序会异常终止。至于t的析构为什么使用这种模式,是因为其他两种模式更糟糕:
隐式join模式:将等待其底层异步执行线程完成,但条件已经返回假了,还继续执行并行函数是浪费时间和性能的,而且难以追踪;
隐式detach模式:线程转为后台执行,但是会引起内存非法访问问题,例如上述代码goodVals使用了引用捕获,如果detach将push到一个未定义内存。
所以标准委员会采用了程序终止的方式来析构线程,这也要求开发者要保证使用std::thread时在所有路径上都保证线程unjoinable,这些路径包括return/continue/break/goto/exception等。
当我们想在每条路径执行某种操作,RAII是一种选择,但是标准库没有RAII的std::thread实现,原因在于标准委员会拒绝join和detach作为默认选项,如果我们接受此二者之一的方式,自行实现RAII
std::thread并不复杂: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25class ThreadRAII{
public:
enum class DtorAction{join, detach};
ThreadRAII(std::thread&& t, DtorAction a):action(a),t(std::move(t)){}
~ThreadRAII(){
if(t.joinable()){
if(action == DtorAction::join){
t.join();
}
else{
t.detach();
}
}
}
ThreadRAII(ThreadRAII&&) = default;
ThreadRAII operator=(ThreadRAII&&) = default;
std::thread& get(){
return t;
}
private:
DtorAction action;
std::thread t;
};
构造器接受std::thread右值,因为std::thread不可复制;
习惯上我们会把thread的构造放在参数构造最后一个,能保证构造完成、线程运行时其他成员变量也构造完成;
调用join前检查是否joinable很重要,因为在unjoinable线程上调用join会导致UB;
get接口避免了复制完整的std::thread,类似智能指针通过get返回底层指针对象;
不必要担心joinable判断存在线程竞争,因为只有std::thread能够改变自己的状态,而std::thread被占用时,其析构不会被调用;
根据条款17,当重写了一个函数的析构函数,其移动操作不会默认生成,但此处我们能够使用移动操作,故声明默认移动操作行为;
把ThreadRAII应用在前述例子: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19constexpr auto tenMillion = 10000000;
bool doWork(std::function<bool(int)>filter, int maxVal = tenMillion)
{
std::vector<int> goodVals;
ThreadRAII t([&filter, maxVal, &goodVals](){
for(auto i=0; i<maxVal; i++){
if(filter(i)) goodVals.push_back(i);
}
}, ThreadRAII::DtorAction::join);
auto thread_handle = t.get().native_handle();
... //set priority
if(conditionsAreStatisfied()){
t.get().join();
performComputation(goodVals);
return true;
}
return false;
}
当然,适中的方法是中断线程,但C++ 11不直接支持可中断线程,也不在本书的讨论重点,具体可参考C++ Concurrency In Action 9.2节(这是下一个坑。
条款38:关注不同线程句柄的析构行为
条款37表明了joinable的std::thread和non-deferred任务的future对象都是相应的系统线程的句柄,std::thread的析构采用了程序终止,因为隐式的join和detach带来的后果有时更糟糕,但future的析构表现与此不同,有时候执行的是隐式的join,有时候是隐式的detach,有时二者都没有执行,所以程序永远不会终止;
因此,研究future的线程句柄是一个有趣的行为。
future对象和对应的promise对象能够看成是一种通信信道,被调用者通过promise将结果写入信道,调用者通过future将结果从信道读出,被调用者的结果存储在一个被称为共享状态(shared state)的位置,这是一个基于堆的存储对象,结果的生命周期与最后一个关联的future生命周期一样,但标准未指定其类型、接口和实现,库的作者可以自由发挥。
之所以要存储在这样的位置,因为:
若存储于promise端,当异步任务执行完,该局部变量会被销毁;
若存储于future端,future有可能被用于构造shared_future,future被销毁后,shared_future还能被复制很多次,但不是所有的结果类型都可以被拷贝;
一种简化的实现如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 简化的实现概念
template<typename T>
struct shared_state {
std::mutex mutex_;
std::condition_variable cv_;
bool ready_ = false;
// 结果存储在这里,不在future对象中
union {
T value_;
std::exception_ptr exception_;
};
};
// 引用计数,由shared_ptr管理
template<typename T>
class future {
std::shared_ptr<shared_state<T>> state_; // 指向独立的状态
......
};
template<typename T>
class shared_future {
std::shared_ptr<shared_state<T>> state_; // 指向同一个状态
......
};
future的共享状态决定了future自身的析构行为:
non-deferred任务(如std::launch::async)的最后一个关联共享状态的future析构函数会在任务完成前block住,本质是其线程析构使用了类似隐式的join的行为;之所以使用这种设计,因为std::launch::async会保证启动新的线程,如果没有join,那么可能会导致新线程访问了非法内存;
non-deferred任务,若不是最后一个关联的future对象,其线程析构像是一种detach,future本身数据被销毁,共享状态应用数-1;
deferred任务对应的future对象析构,既不会detach,也不会join,这个任务永远不会执行,也意味着必须在deferred future还存在时使用get或者wait才能使任务执行; 这里重点注意的是,std::async的最后一个关联共享状态析构时可能会阻塞等待,所以这样的类其析构时也可能被阻塞:
1
2
3
4
5
6class Widget{
public:
...
private:
std::shared_future<double> fut; //might block destructor
};
std::packaged_task
鉴于类中直接构造的shared_future对象可能有阻塞问题,C++
支持其他方式来创建共享状态,例如通过std::packaged_task的方法:
1
2
3
4
5
6
7
8
9
10
11
12int calcValue();
std::packaged_task<int()> pt(calcValue);
auto fut = pt.get_future();
std::thread t(std::move(pt)); //std::packaged_task不能被拷贝,只能使用赋值
...
//三种可能,都不会引起异常的future对象析构
1. nothing to do
2. t.join();
3. t.detach();
对t什么都不做:如条款37,程序会直接终止;
join t:t本身会阻塞,不需要future析构函数执行阻塞;
detach t:t已经detach,也不需要future来detach;
条款39:对于一次性事件通信考虑使用无返回futures
线程同步中有一种经典任务,一个任务发生了特定事件,然后通知另一个异步执行的线程,第二个收到改信号才能继续执行,该信号可以是数据已经初始化完成、计算完成或者检测到重要的传感器信号,这种情况,最佳的线程间通信方案是什么呢?
方案一:条件变量
最直接的方案是使用条件变量: 1
2
3
4
5
6
7
8
9
10std::condition_variable cv;
std::mutex mtx;
//检测任务:
cv.notify_one(); //只有一个反应线程
cv.notify_all(); //有多个反应线程
//反应任务:
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock);
没有数据竞争但也使用了互斥锁;一个线程在执行完通知另一个线程,对某块的共享数据的访问显然不存在数据竞争,但因为条件变量必须和互斥量、互斥锁结合使用,这个设计稍有不适;
检测方的notify如果在反应方进入wait状态之前,这个唤醒会被丢失,反应方会长久阻塞;
wait语句存在虚假唤醒(spurious wakeups)问题;由于操作系统信号处理机制、尤其是多核处理器内存同步、条件变量内部实现等原因,规范允许了条件变量虚假唤醒,在唤醒条件不满足时,线程可能也会被虚假唤醒,处理方法也很简单,在wait的外部添加while循环检查退出条件是否满足,C++ 11中习惯使用lambda进行等效的循环检测:
1
2
3cv.wait(lock [](){
return ready == true;
});
方案二:全局boolean
既然共享数据不存在竞争,只是存在反应线程和检测线程的通知,所以可以通过共享bool变量来控制任务的开启和结束:
1
2
3
4
5
6
7
8//检测线程:
std::atomic_bool flag(false);
flag = true;
//反应线程:
while(flag == false); //wait for event
//do reaction...
方案三:promise-future对
如果只是一次性通信事件,可以考虑使用promise和future对:
1
2
3
4
5
6
7std::promise<void> p; //当没有结果参数需要传递,use void
//检测线程:
p.set_value();
//反应线程:
p.get_future().wait();
共享状态是动态分配的,会产生基于堆分配和释放开销;
promise和future只能被设置和获取一次,通信是一次性的;
线程挂起
promise-future也是线程挂起的一个方案: 1
2
3
4
5
6
7
8
9
10
11std::promise<void> p;
void react();
void detect(){
std::thread t([](){
p.get_future().wait();
react();
});
...// do something
p.set_value();
t.join();
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17std::promise<void> p;
void detect(){
auto sf = p.get_future().share();
std::vector<std::thread> vp_thread;
for(int i=0; i < thread_num; i++){
vp_thread.emplace_back([sf]){
sf.wait();
react();
}
}
//hang up
p.set_value();
...
for(auto& t : vt){
t.join();
}
}
条款40:当需要并发时使用std::atomic,特定内存才使用volatile
本条款主要是讨论std::atomic和volatile在并发上的特点,以下。
读写(read-modify-write,RMW)操作,对于volatie,其不具备任何并发的特性:
代码过程中,其他线程可能读取到任何的值,同理,如果同时两个线程同时执行++vi,vi得到的也不是2,其结果不可预测,因为数据存在竞争时,编译器能够以任何逻辑处理,并非是编译器作恶,而是在没有数据竞争的情况下编译器的优化才有效;1
2
3
4volatile int vi(0);
vi = 10;
++vi;
--vi;指令重排,对于volatile,编译器和硬件实现可能都会修改执行顺序,例如:
这两句都是无关变量,没有严格的先后关系,因此编译器很可能会更改顺序进行优化,而std::atomic严格限制了这种指令重排优化,当看到valAvaliable为true,impatValue一定是被赋值完成;1
2
3volatile bool valAvaliable(false);
auto impatValue = computeImportantValue();
valAvaliable = true;赋值优化,像这种代码:
正常情况下,这种代码都会被优化为:1
2
3
4auto y = x;
y = x;
x = 10;
x = 20;虽然我们本意不会写这样,但是代码经过模板实例化、内联、重排后,像这些冗余的操作并不少见;1
2auto y = x;
x = 20;
对于volatile,相当于声明了这是特殊的内存,因此编译器不会对冗余赋值执行优化,这在嵌入式设备尤其重要,因为变量指向传感器的值,或者不同的控制指令,或者那种类似mmap的内存,其每次赋值都是有不同意义的;
与volatile类似,对于std::atomic同样是一种特殊内存,不会像正常内存那样优化,但是直接写编译不通的,因为std::atomic模板的拷贝构造是被删除的(见条款11),因为编译器无法将读取和写入同时构成一个原子操作,硬件也无法做到,只能先原子读取、再原子写入,所以类似:
1
2std::atomic_int y(x.load());
y.store(x.load());
综上,volatile和std::atomic实际上是不同的东西,当然可以结合使用volatile std::atomic<T>,
可用于那种变量本身关联了mmap、传感器类似的内存,但又需要并发访问的场景。
第八章:微调(Tweaks)
条款41:如果参数可拷贝且移动操作开销很低,考虑使用按值传递
从条款24可知,定义一个万能引用即可实现左值拷贝、右值移动:
1
2
3
4
5
6
7
8
9class Widget{
public:
template<typename T>
void addName(T&& name){
names.push_back(std::forward<T>(name));
}
private:
std::vector<std::string> names;
};
模板可能不止为std::string的左右值实例化函数,可能也会为其他可转换为std::string的类型实例化函数(条款25);
不是所有参数都能被万能引用完美转发,例如初始化列表、位域等(条款30);
传递了不合法的参数类型,编译器可能产生错误(条款27);
模板函数的完整定义必须写在头文件,造成体积膨胀;
此处,按值传递完美解决了上述问题:
1 | class Widget{ |
name完全是一个参数拷贝,不影响外围的变量值,其作用域也仅限于该函数,move掉也没关系;唯一的代价是,使用值传递,对于左值需要一次拷贝和一次移动,对于右值需要两次移动,均比引用方法多了一次移动,因此如果移动开销很低,可以考虑使用值传递;
几种情况策略选择:
需要避免重载和万能引用带来的各种问题,考虑按值引用;
当参数只支持移动(例如std::atomic/std::unique_ptr),直接写右值重载即可避免一次移动;
移动开销很低;
只对那种总是复制的函数才考虑按值传递,例如如果函数对长度过长的不执行push,那么按值传递的copy就没有意义了,不如直接按引用传递,因为它可能避免所有开销,而按值传递至少存在一次拷贝或者移动;
但还要注意,按值传递有时候是复杂的策略,我们还要讨论一些个例,如:
1
2
3
4
5
6
7
8
9class Password{
public:
explicit Password(std::string pwd) : text(std::move(pwd)){}
void changeTo(std::string newPwd){
text = std::move(newPwd);
}
private:
std::string text;
};
这种情况下,按值传递可能使得方案开销大大增长: 1
2
3
4std::string init_pwd("adffghjjdasasasagsd");
Password p(init_pwd);
std::string new_pwd("xxxxxxxxxxxxx");
p.changeTo(new_pwd);
此外,在长的调用链中,按值传递的开销会变得难以计算,因此,使用按值传递还是需要谨慎估计;
C++按值传递的切割问题(slicing problem)
切割问题指的是在继承体系中,如果给一个基类参数传递一个子类对象,该子类对象特有的数据成员会被切割掉,只保留基类部分,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
using namespace std;
class Animal{
public:
virtual void doAction() const{
cout << "Has Animal: " << nums << endl;
}
protected:
int nums = 100;
};
class Dog : public Animal{
public:
Dog(int num){
Animal::nums = num;
}
void doAction() const override{
cout << "Has Dog : " << nums << endl;
}
private:
int age = 10; //被切割
};
void test(Animal animal){
animal.doAction();
}
void test1(const Animal& animal){
animal.doAction();
}
template <typename T>
void test2(T animal){
animal.doAction();
}
int main(){
Dog dog(20);
test(dog); //Has Animal: 20
test1(dog); //Has Dog : 20
test2(dog); //Has Dog : 20
cout << "done" << endl;
return 0;
}
条款42:考虑使用emplacement代替insertion
优先考虑emplacement条件
满足以下条件,emplace接口会优于push/insertion接口:
值是通过构造器添加到容器,而不是直接赋值,如:
此时,需要向vs赋一个新值,而移动赋值需要一个源对象,因此会存在和push一样的临时对象创建,emplace的优势消失殆尽;而如果是构造器的情况:1
2
3std::vector<std::string> vs;
vs[0] = "abdc";
vs.emplace(vs.begin(), "1234"); //向已存在的内存赋值emplace支持完美转发(只要不是那种转发失败情况,见条款30),字面常量abdc会被转发到vs中的std::string构造,而如果使用insertion,会多一次临时变量的构造和析构,因此前者性能更优;1
2std::vector<std::string> vs;
vs.emplace_back("abdc"); //构造器添加传递的参数类型和容器参数类型不同;通常条件下,emplace更优是因为类型和容器类型不完全一致,例如前面的字符常量和std::string,所以产生临时变量,如果没有这种差异,不能期望emplace更优;
容器是元素能够重复的容器;如果是那种只接受非重复元素的容器,要求判断元素是否存在于容器中,因此emplace会创建一个新值的节点进行判断,如果不存在,链接这个节点,否则析构;而insertion不存在创建,只会查找值是否存在,如果不存在才创建内存,insertion性能反而更优;
之所以不要无脑用emplace代替insertion,有若干情况使用insertion更加合理:
insertion更优若干情形
- insertion的构造有时会使资源管理更鲁棒,如: 在push_back的异常处理中,如果从临时对象构造容器对象时发生OOM抛出异常,临时对象会被销毁,智能指针也会调用deleteWidget销毁Widget对象,没有发生异常泄漏;但是emplace的异常处理中,完美转发使得指针的控制权交给了emplace,推迟了资源管理对象的创建,且异常时丢失了,此时原来的指针对象也无法析构Widget,造成内存泄漏;std::unique_ptr也有同样的问题;
1
2
3
4
5std::vector<std::shared_ptr<Widget>> ptrs;
void deleteWidget(Widget* pWidget);
ptrs.push_back(std::shared_ptr<Widget>(new Widget, deleteWidget)); // good
ptrs.emplace_back(new Widget, deleteWidget); //not so safe
这种情况我们倾向使用insertion,当然更好的做法是习惯使用独立语句而不是临时对象来创建智能指针:
1
2
3
4std::shared_ptr<Widget> spw(new Widget, deleteWidget);
ptrs.push_back(std::move(spw));
ptrs.emplace_back(std::move(spw)); //both ok
- 部分insertion显示构造容易检出异常,如构造一个正则表达式std::regex:
此处,push_back使用了#1那样的初始化方式,称为复制初始化,通过字面常量初始化regex的方式是一种显式构造,但复制初始化禁用了从nullptr到regex的隐式转换;反之,emplace_back使用了和#2那样的初始化方式,称为直接初始化,直接初始化的nullptr能够直接匹配字面常量(而不触发隐式转换的禁忌),因此能够通过编译。
1
2
3
4
5
6std::regex r = nullptr; // #1 :error!
std::regex r(nullptr); // #2 : 编译通过,但UB
std::vector<std::regex> vp;
vp.push_back(nullptr); //#3:error!
vp.emplace_back(nullptr); //#4:编译通过,但UB
全书完
感谢阅读,若有勘误请联系2436444815@qq.com。
