
SQLite数据库基础与C++方法
SQLite是最常用的一种轻量级的数据库,占用资源极低,广泛用于嵌入式设备的数据存储,本文介绍了SQLite的编译安装和C++接口基本方法。
环境安装
以MinGW gcc编译为例:在SQLite官网下载合并版本的sqlite源码(如sqlite-amalgamation-3510000.zip),或者直接点击此处下载和解压。
编译C系动态库: 1
gcc -shared -O2 -DSQLITE_ENABLE_FTS4 -DSQLITE_ENABLE_JSON1 sqlite3.c -o sqlite3.dll
编译sqlite数据库命令行工具: 1
gcc sqlite3.c shell.c -o sqlite3 -ldl -lpthread
通过.exit和.quit命令退出该环境。
数据类型
SQLite大致支持五种存储类型,分别是:
| 存储类型 | 特点 |
|---|---|
| NULL | NULL值存储 |
| INTEGER | 带符号整数,根据大小分1、2、3、4、6或8字节存储 |
| REAL | 浮点值,存储为8字节浮点数 |
| TEXT | 文本字符串,使用数据库编码(UTF-8/UTF-16BE/UTF-16LE)存储 |
| BLOB | 意为Binary Large Object,按原始输入存储二进制数据,默认支持高达1GB的二进制数据存储 |
与MySQL和大多数数据库静态类型不同,SQLite使用的是一种动态类型系统,具体存储的类型和声明类型无关,而和要存入的类型相关,换言之尽管将某一列声明为INTEGER,存入Text文本类型还是会成功,因此这种列属性并不是严格的类型特性,只反映了列存储的类型偏好,这种特性被称为亲和类型(Affinity
Type),SQLite划分了五类亲和类型(注意和上述存储类型区分,亲和类型是创建对象时需声明的类型):
| 亲和类型 | 特点 |
|---|---|
| NONE | 不做任何转换,直接按原数据类型存储,如BLOB和NULL存储类型 |
| INTEGER | 会尝试将文本转换为整数,转换小数会丢失精度 |
| REAL | 会尝试将文本转换成小数存储,失败仍然按TEXT存储 |
| TEXT | 数据会被转换为文本格式存储 |
| NUMERIC | 智能版的数值存储,会自动转换整数和小数,不会自动截断小数 |
SQLite仍然支持其他数据库通用的类型声明,但是因为SQLite本身划分了五种亲和类型,实际上它们在存储上没有任何区别,例如尽管你声明了char(20),仍然可以超过额定长度插入数据,同属于一种亲和类型的通用类型,实际上是基本等效的,但是存在一些特殊场景需要加以区分,例如INT作主键和INTEGER作主键,其ROWID表现有所不同,见后文,亲和类型对应的各种通用类型具体如下:
NONE: BLOB;
INTEGER:INT、INTEGER、TINYINT、SMALLINT、MEDIUMINT、BIGINT、UNSIGNED BIG INT、INT2、INT8;
REAL:REAL、DOUBLE、FLOAT;
TEXT:CHARACTER(20)、VARCHAR(255)、VARYING CHARACTER(255)、NCHAR(55)、NATIVE CHARACTER(70)、NVARCHAR(100)、TEXT、CLOB;
NUMERIC:NUMERIC、DECIMAL(10,5)、BOOLEAN、DATE、DATETIME;
SQLite没有专门的布尔类和日期类,均默认按数值类型存储,其中:
布尔类:整数0存储false,整数1存储true;
日期类:Text类型,对应“YYYY-MM-DD HH:MM:SS.SSS”日期解析;REAL类型,对应公元前 4714 年 11 月 24 日格林尼治时间的正午至今算起的天数;INTEGER类型,对应1970-01-01 00:00:00 UTC至今算起的秒数。
数据库的DDL操作
记录了SQLite相关SQL语句。
数据库的创建
进入sqlite命令行,这两个命令都会打开数据库(不存在则新建):
1
2
3sqlite3 test.db
.open test.db
数据库的附加和分离
一个会话默认只打开一个数据库作为主数据库,ATTACH用于加载另一个数据库到当前会话,使得同一个会话能够操作多个数据库,detach用于取消attach,但主数据库不能被detach:
1
ATTACH DATABASE 'test.db' as Test_Origin;
1
2
3
4
5.database
-- 结果:
main: D:\sqlite\sqlite-amalgamation-3500400\test1.db r/w
Test_Origin: D:\sqlite\sqlite-amalgamation-3500400\test.db r/w -- 加载了新数据库
detach: 1
DETACH DATABASE Test_Origin;
数据库的dump导出和导入
通过dump可以将数据库数据导出到sql语句中并以文本存储,也可以基于sql语句恢复该数据库内容:
1
2
3
4
5-- 导出:
test.db .dump > test.sql
-- 导入:
test.db < test.sql
表的DDL与SQLite约束
命令行对自动补全支持一般,以下内容基于图形SQL软件DB Browser for SQLite进行。
表的创建和删除
创建表使用亲和类型声明即可,也可以延续其他数据库的类型习惯:
1
2
3
4
5
6
7
8CREATE TABLE IF NOT EXISTS company(
id INT PRIMARY KEY NOT NULL,
name TEXT NOT NULL UNIQUE,
age INT DEFAULT 18 CHECK (age BETWEEN 18 AND 100),
gender TEXT DEFAULT 'unknown' CHECK (gender IN('male','female','unknown')),
address TEXT ,
salary REAL
);
删除表: 1
DROP TABLE company;
SQLite约束
上述语句表征了几种约束关系,解释如下: - PRIMARY KEY:主键,唯一、可能非空(INTEGER类型遵循,INT、TEXT类型等可能不遵循)
UNIQUE:保证唯一性;
NOT NULL: 不能传入NULL值;
CHECK: 检查子句条件,但注意NULL值不会违反任何CHECK条件;
DEFAULT:设置默认值;
不满足约束的数据插入都会失败。
DML操作
数据插入
数据的基本插入: 1
2INSERT INTO company(id, name, age, gender, address, salary)
VALUES(1, 'Eden', 18, 'male', NULL, 300);
省略字段插入也是可行,但此时要严格控制插入字段顺序和数量:
1
INSERT INTO company VALUES(3,'Lucy', 28, 'female', NULL, 3000);
数据的替代插入:SQLite也支持对PRIMARY KEY和UNIQUE约束的记录进行替代插入,当出现唯一性冲突时不会报错,而是会删除原有的记录并插入新的记录,这不是单纯的更新,因为其ROWID会随之更新:
1
INSERT OR REPLACE INTO company VALUES('Lucy', 28, 'female', NULL, 3000);
ROWID与id INTEGER PRIMARY KEY
ROWID是数据插入表时SQLite自动分配的一个id号,每个ROWID对应一行,即一条记录,从1开始自动递增,数据删除该ROWID也不会回收使用。
当创建表时定义id号为id INTEGER PRIMARY KEY,此时的id会成为ROWID的别名,因此ROWID插入数据时会严格等同于id的赋值,而不是自动递增,这也要求id为UNIQUE且NOT
NULL: 1
2INSERT INTO company(id, name, age, gender, address, salary) -- 此时id = ROWID = 1
VALUES(1, 'Eden', 18, 'male', NULL, 300);
反之,如果id类型不是INTEGER,而是INT或者TEXT类型:即id INT/TEXT PRIMARY KEY,此时的ROWID与id是独立的,ROWID自动递增,而id由用户定义,而且虽然id被定义成主键,但传入NULL值也不会报错:
1
2
3
4
5INSERT INTO company(id, name, age, gender, address, salary) -- 此时id = NULL
VALUES(NULL, 'Eden', 18, 'male', NULL, 300);
SELECT ROWID FROM company -- ROWID = 插入时的rowid,若使用INSERT OR REPLACE替代,ROWID会逐次更新
WHERE name = 'Eden';
所以确认创建表的信息和主键对数据管理是重要的,sqlite3命令下通过点命令可以快捷查询:
.schema查询创建信息语句:
1
2
3
4
5
6
7
8
9
10
11sqlite> sqlite> .schema
-- 输出结果:
-- CREATE TABLE company(
-- id INT PRIMARY KEY,
-- name TEXT NOT NULL UNIQUE,
-- age INT DEFAULT 18 CHECK (age BETWEEN 18 AND 100),
-- gender TEXT DEFAULT 'unknown' CHECK (gender IN('male','female','unknown')),
-- address TEXT ,
-- salary REAL
-- );
或使用PRAGMA table_info(表名)查询: 1
2
3
4
5
6
7
8
9
10
11
12sqlite> sqlite> .mode column -- 结果以列信息给出
sqlite> sqlite> PRAGMA table_info(company);
-- 输出结果:
-- cid name type notnull dflt_value pk
-- --- ------- ---- ------- ---------- --
-- 0 id INT 1 1 -- pk==1,为主键
-- 1 name TEXT 1 0
-- 2 age INT 0 18 0
-- 3 gender TEXT 0 'unknown' 0
-- 4 address TEXT 0 0
-- 5 salary REAL 0 0
数据删除
使用DELETE FROM + 表名 + WHERE + 删除条件,如删除名字为‘Eden’的记录:
1
2DELETE FROM company
WHERE name = 'Eden';
DQL
SELECT语句比较复杂,而且SQLite大部分场景都用不上复杂查询,基本兼容MySQL方法,详情可参考MySQL方法:多表查询与子查询。
其中一些不同是SQLite不支持右外连接,但这完全可以用左外连接模拟,如:
1
2
3
4
5
6
7
8
9
10
11SELECT stuff.last_name,d.department_name
FROM employees stuff RIGHT JOIN departments d
ON stuff.department_id = d.department_id
WHERE stuff.department_id IS NULL;
-- 等效于:
SELECT stuff.last_name,d.department_name
FROM departments d LEFT JOIN employees stuff -- 交互主从表名即可
ON stuff.department_id = d.department_id
WHERE stuff.department_id IS NULL;
C++操作数据库实现
预处理语句
在用具体接口前,需要了解最后一个概念:SQL语句的预处理。数据库执行SQL语句往往经过分析器、优化器和执行器等:
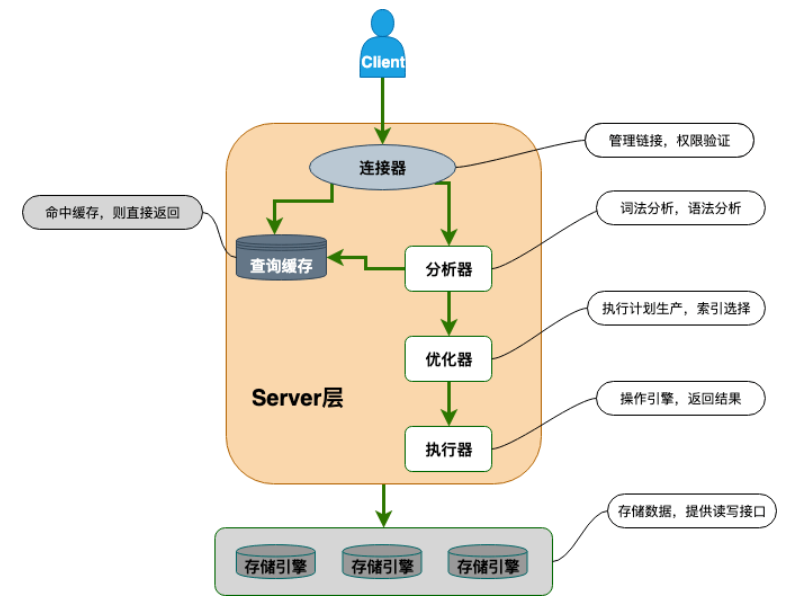
其中分析器做语法检查和命令解析,由优化器计算出较小代价的查找路径,生成执行计划,这个过程可被成为类似编译的过程。如果每条sql都需经过编译执行性能是较差的,因为sql往往有大量重复命令,只是插入的数值或者删除条件不同。所以这种情况下,高级设计语言的接口往往会支持占位符编写预处理的sql语句,这种sql预处理语句只需要在sqlite等数据库中被编译一次,然后绑定不同的参数,就可以完成多次的重复执行。
C++中需要使用prepare函数生成stmt statement对象:
1
2
3
4
5
6
7int sqlite3_prepare_v2(
sqlite3 *db, //打开的数据库对象
const char *zSql, //sql字符串,注意是C风格的
int nByte, //字符串长度,一般-1,代表以"\0"结尾截止;
sqlite3_stmt **ppStmt, //stmt对象的双重指针
const char **pzTail //未被解析的sql语句部分,一般不关注,NULL/nullptr
)
绑定参数时使用bind即可: 1
2
3int sqlite3_bind_int(sqlite3_stmt *, int, int)
int sqlite3_bind_double(sqlite3_stmt *, int, double)
int sqlite3_bind_text(sqlite3_stmt *, int, const char *, int, void (*)(void *))sqlite3_bind_text比其他类型多了int参数和函数指针参数,其中int参数为字符串长度,-1仍然代表以\0结束;对于函数指针参数是定义该字符串的内存释放方式,代表我们可以自定义其释放函数行为,而其默认提供了两种释放方式:
SQLITE_TRANSIENT:SQLite会拷贝该字符串的副本,较安全。
SQLITE_STATIC:SQLite会无拷贝并使用原字符串指针,用户需要保证SQLite调用时原内存不被析构,并且使用后手动释放。
接口
其余接口较为简单,关注sqlite3_exec即可: 1
2
3
4
5
6
7int sqlite3_exec(
sqlite3 *db, //数据库对象
const char *sql, //sql语句
int (*callback)(void *, int, char **, char **), //回调函数,如处理SELECT结果,NULL暂略
void *arg, //回调函数第一个参数
char **errmsg //可打印的错误信息输出
)
完整实现
约500行代码实现了SQLite数据库的数据插入、查询、删除、事务记录和回滚等,支持常见的整数、浮点数、字符串类型,完整实现和注解已经给出,使用CMake管理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24cmake_minimum_required(VERSION 3.10.0)
project(cmakeTest)
add_executable(${PROJECT_NAME})
target_sources(${PROJECT_NAME} PRIVATE
database.h
database.cpp
main.cpp
)
target_include_directories(${PROJECT_NAME}
PRIVATE
D:/sqlite/sqlite-amalgamation-3500400
)
target_link_directories(${PROJECT_NAME}
PRIVATE
D:/sqlite/sqlite-amalgamation-3500400
)
target_link_libraries(${PROJECT_NAME}
sqlite3
)
1 | //database.h |
1 | //database.cpp |
一个测试程序如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154//main.cpp
void initDB(const std::string& path, const std::string& tableName1, const std::string& tableName2, DataBase& database){
if(database.open(path) == false){
cerr << "Open or Create DB failed! " << endl;
return;
}
std::map<std::string, std::string> table{
{"id", "INTEGER PRIMARY KEY"},
{"time", "TEXT NOT NULL"},
{"name", "TEXT UNIQUE"},
{"value", "TEXT"}
};
if(database.createTable(tableName1, table) == false){
cerr << "createTable Text failed! " << endl;
return;
}
std::map<std::string, std::string> tableDouble{
{"id", "INTEGER PRIMARY KEY"},
{"time", "TEXT NOT NULL"},
{"name", "TEXT UNIQUE"},
{"value", "REAL"}
};
if(database.createTable(tableName2, tableDouble) == false){
cerr << "create Double Table failed! " << endl;
return;
}
}
bool insertRecord(const std::string& tableName, std::map<std::string, std::any>& keyValueData, DataBase& database){
DataBase::BaseTableInfo baseinfo;
baseinfo.tableName = tableName;
baseinfo.keyValue = keyValueData;
return database.insertUnique(baseinfo);
}
std::string getRecord_Text(const std::string& tableName, const std::string& keyName, DataBase& database){
DataBase::BaseTableInfo baseinfo;
baseinfo.tableName = tableName;
const char* unknown = "";
baseinfo.keyValue = {
{"id", 0},
{"time", unknown},
{"name",unknown},
{"value", std::string("")}
};
if(database.selectUnique(baseinfo, "name", keyName)){
auto it = baseinfo.keyValue.find("value");
if(it != baseinfo.keyValue.end()){
return std::any_cast<std::string>(it->second);
}
}
return "";
}
double getRecord_Double(const std::string& tableName, const std::string& keyName, DataBase& database){
DataBase::BaseTableInfo baseinfo;
baseinfo.tableName = tableName;
const char* unknown = "";
baseinfo.keyValue = {
{"id", 0},
{"time", unknown},
{"name",unknown},
{"value", 0.0}
};
if(database.selectUnique(baseinfo, "name", keyName)){
auto it = baseinfo.keyValue.find("value");
if(it != baseinfo.keyValue.end()){
return std::any_cast<double>(it->second);
}
}
return 0.0;
}
int main(){
std::string dbPath = "D:/sqlite/sqlite-amalgamation-3500400/myTest.db";
DataBase db;
/// ----------------------------------------------- 建表-----------------------------------------------
std::string tableName_txt = "Table_Txt";
std::string tableName_double = "Table_double";
initDB(dbPath, tableName_txt, tableName_double, db);
std::string keyName_txt = "txtObj";
std::string keyName_double ="doubleObj";
std::map<std::string, std::any> data_Txt{
{"id", 123},
{"time", "20251113"},
{"name", keyName_txt},
{"value", "With Great Power comes Great Responsibility!"}
};
/// ----------------------------------------------- 插入/替代测试 -----------------------------------------------
insertRecord(tableName_txt, data_Txt, db);
std::map<std::string, std::any> data_Double{
{"id", 12335},
{"time", "20251113"},
{"name", keyName_double},
{"value", 123.98751}
};
insertRecord(tableName_double, data_Double, db);
/// ----------------------------------------------- 查找测试 -----------------------------------------------
cout << "txtObj res: " << getRecord_Text(tableName_txt, keyName_txt, db) << endl;
cout << "doubleObj res: " << getRecord_Double(tableName_double, keyName_double, db) << endl;
/// ----------------------------------------------- 其余杂项测试 -----------------------------------------------
bool check = (db.tableExists(tableName_txt) == true) && (db.tableExists("sasada") == false);
cout << (check ? "tableExists pass" : "Not Pass") << endl;
check = (db.columnExists(tableName_txt, "name") == true) && (db.columnExists(tableName_txt, "abcd") == false);
cout << (check ? "columnExists pass" : "Not Pass") << endl;
//以下虽然实现insert了,但用法不被推荐,因为:1. 类型单一; 2. 反复execute,性能较差, 推荐使用上述Unique版本:
std::map<std::string, std::string> tmp{
{"name", "Eden"},
{"value", "God loves EveryOne!"}
};
std::string whereCondition = "name = '" + keyName_txt + "';";
check = (db.update(tableName_txt, tmp, whereCondition) == true);
cout << (check ? "update pass" : "Not Pass") << endl;
std::string sql = "SELECT name FROM " + tableName_double + " WHERE time = '20251113';";
std::vector<std::map<std::string, std::string>> results;
db.query(sql, results);
check = (results[0]["name"] == keyName_double);
cout << (check ? "query pass" : "Not Pass") << endl;
cout << getRecord_Double(tableName_double, keyName_double, db) << endl;
db.beginTransaction();
std::string rm_condition = "name ='"+ keyName_double + "';";
db.remove(tableName_double, rm_condition);
check = (getRecord_Double(tableName_double, keyName_double, db)==0.0f);
cout << (check ? "remove pass" : "Not Pass") << endl;
db.rollback();
cout << getRecord_Double(tableName_double, keyName_double, db) << endl;
check = (getRecord_Double(tableName_double, keyName_double, db) - 123.98751 < 0.01f);
cout << (check ? "rollback pass" : "Not Pass") << endl;
cout << "done" << endl;
return 0;
}
执行结果: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26insertUnique sql: INSERT OR REPLACE INTO Table_Txt(id,name,time,value) VALUES (?, ?, ?, ?);
insertUnique sql: INSERT OR REPLACE INTO Table_double(id,name,time,value) VALUES (?, ?, ?, ?);
txtObj res: queryUnique sql : SELECT * FROM Table_Txt WHERE name='txtObj';
Finished Selection
With Great Power comes Great Responsibility! #插入和查询测试ok
doubleObj res: queryUnique sql : SELECT * FROM Table_double WHERE name='doubleObj';
Finished Selection
123.988
tableExists pass
columnExists pass
update pass #字符插入ok
query pass #自定义SELECT执行ok
queryUnique sql : SELECT * FROM Table_double WHERE name='doubleObj';
Finished Selection
123.988
queryUnique sql : SELECT * FROM Table_double WHERE name='doubleObj';
Finished Selection
remove pass #删除ok
queryUnique sql : SELECT * FROM Table_double WHERE name='doubleObj';
Finished Selection
123.988
queryUnique sql : SELECT * FROM Table_double WHERE name='doubleObj';
Finished Selection
rollback pass #事务记录和回滚ok
done
参考链接:
