
不积代数,无以至千里:线性代数基础
在图像处理/数据优化/机器学习方法方面,看了一些需要代数背景的代码比较糊涂,决定以个人视角记录一些线性代数基础,也是想做很久的一件事。参考了多方资料,包括宋浩线性代数(理解细节参考)、张宇线性代数(排版、总结、详略、公式非常好)以及来自MIT的线性代数课程(思想、与工程结合性出众),可能比较综合(杂乱)。
逐渐更新。
矩阵基础
矩阵的定义不值一提,但从不同视角看待更容易理解矩阵的本质。
行图像(Row Picture)与列图像(Column Picture)
平时习惯以行图像的时间看待矩阵,例如上述矩阵可以看成线性方程组的求解,对于二维矩阵求的是两直线的交点,三维则求三个面的交点:
列图像将矩阵看成是列向量的线性组合:
解的存在性和个数取决于两个向量的线性组合是否可达至目标向量。
如果目标向量B是任意的,从行向量看代表两条直线关系是随机的,如果是三维,则代表了空间中三个平面的关系是随机的;而从列图像理解更容易得多,因为其系数矩阵是不变的,无论是二维还是n维空间,关键在于系数向量的线性组合是否能够表示n维空间中任意的向量,其答案也显然的,如果n维系数均是线性无关的,那么一定能表示空间中任意向量。
提醒
反对称矩阵
对称矩阵容易理解,满足
矩阵多项式
那么矩阵多项式有:
运算
矩阵运算中不能以代数视角计算,例如:
同理:
此外AB=0不能推断A=0或者B=0,故:
矩阵转置规律
正交矩阵
对于方阵,满足
A为正交矩阵,其特征很明显:
- 首先求逆极其简单:两边右乘
有:
- 意味着A的行向量组成的向量组以及列向量组成的向量组,均是标准正交基(见下文向量基础),由于
可见a向量自身模长为1,与b、c均正交,b、c同理,故a、b、c行向量组成的向量组均是标准正交基,列向量同理。
矩阵的逆
对于方阵A,若 |A|不为0。
一些计算规律:
对角分块矩阵的逆
如果是副对角线,分块矩阵顺序要相反写:
三角分块矩阵的逆
存在四种情况:
主对角线的三角分块阵:对角线元素位置不变直接求逆,上三角/下三角元素左乘同行元素、右乘同列元素,然后加负号:
有: 副对角线的三角分块阵:两个对角线上的元素都要交换顺序,然后执行规律:副对角线元素直接求逆,上/下三角元素左乘同行、右乘同列,然后加负号:
有:
余子式与代数余子式
伴随矩阵前要了解一些行列式基本计算,对于一个矩阵中某个元素,去除该元素所在行、列的所有元素,顺序不变组成的子式就是余子式,例如对于矩阵:
同理对于元素5,其余子式为:
代数余子式是值在余子式的基础上,考虑行列和的奇偶性决定符号:
例如元素2的代数余子式
对于n阶方阵,其行列式值等于某行或者某列元素乘上其代数余子式:
j取值可以是1到n任一列(注意是一列,不是全部列都要)。
伴随矩阵
有了代数余子式的概念,就知道A的伴随矩阵由每个位置对应的代数余子式组成,但是注意对应关系的行列位置是相反的(
一些计算性质:
矩阵和的伴随同样没有固定规律。
这里最重要的是通过伴随矩阵求逆的公式,因此也推导出了二阶矩阵的逆快捷计算:主对角线元素对换、副对角线元素取反,再除以原行列式值:
初等矩阵
矩阵初等变换有三种:交换两行/两列、数乘某行/某列、倍乘某行/某列后加到另一行/列。
单位矩阵经过一次初等变换得到的矩阵,称初等矩阵,以三阶矩阵,其表示和记号如下:
- E的第二行(或第二列)乘k倍:
E的1、2行(或1、2列)互换:
E的第1行的k倍加到第3行(或者第3列的k倍加到第1列):
初等矩阵运算性质
行列式:
转置:
逆:
重要定理:若矩阵A可逆,A可以经过有限次初等行变换化成单位矩阵:
也等同于A是一系列初等行变换的乘积结果。
- 左乘行变换、右乘列变换。
等价矩阵
如果A、B都是m×n矩阵(同型矩阵),且存在可逆矩阵
等价矩阵的一个充分必要条件是秩相等: rank(A) = rank(B);
等价标准形:对于可逆方阵A,其可以分解到初等矩阵+单位阵,如果是m×n的矩阵A,则不可以直接分解到单位阵,但是可以分解到类似的形式,这种形式称为等价标准形,每个矩阵都有唯一的等价标准形:
LU分解
线性方程组最常用的求解方法是通过增广矩阵+高斯消元法,所谓高斯消元法,实际上就是行与行间消元化出一个得到上三角矩阵,而且知道,这种消元实际上是行变换,行变换的本质是左乘了初等变换矩阵,从原始矩阵A开始:
上三角矩阵对应的是U符号,其变成上三角矩阵的过程是第一行的-2倍加到第二行、第一行的-2倍加到第三行、第二行的-3倍加到第三行,即左乘了三个初等矩阵:
此处上三角矩阵,将每行的第一个非0元素称为主元(pivot),这里我们仅讨论方程满秩的情况,消元后一个方程组的主元分布可能不是完全按一条斜线分布,这种情况先调换一下行顺序(线性方程顺序)即可。
所以:
至此得到了
其原理也是分块矩阵+基本变换,当相当于两个分块都左乘了
因此下三角矩阵求逆时,仍然是前面的行对后面的行消元,所以其逆仍然是一个下三角矩阵,于是乎
一点题外话是既然IA = U已经有两个上下三角矩阵了,为什么还要写成A = LU,这里还有一个特点是通过L能清楚看到所有的初等变换步骤,而I做不到,上述I和
可以看出,
LU分解的线性方程组求解
线性代数的根本目的是解线性方程组,只讨论分解不讨论求解无异于虎头蛇尾。
使用A构造一组方程组,Ax=b为:
从增广矩阵的角度可以说很简单,这里走一次LU分解的流程,从上述已知:
所以Ax = b可以写成LUx = b,令y = Ux,所以有方程Ly = b:
再列出Ux = y有:
上三角矩阵也容易看出结果:
这就是Ax = b方程组的解。
LU分解特点
从求解过程可以看出,LU分解的本质实际上类似增广矩阵求解,都是通过高斯消元法来得到上三角/下三角矩阵再回代来获取结果。对于一个n阶方阵,第一行需要对n-1行乘上(n-1)个不同倍数进行消元,可见一行的消元开销是平方级别,一共有n行元素,所以LU分解的总体复杂度为
LU分解的数值稳定性取决于主元的选择,常用的主要是对行主元的选择,LU分解会引入行置换矩阵P,例如表示第一行和第二行交换
LU分解写成PA = LU,这也是大多数算法的实现原理。假如不引入这样的P,对于矩阵:
有一类矩阵被称为严格对角占优矩阵(strictly diagonally dominant
matrix),其每个对角线元素绝对值,都大于元素所在行其他元素绝对值之和,即:
这类矩阵的LU分解稳定性较高,而且无需置换矩阵。
最后,对于LU分解,其目的性很单一,就是为了求解线性方程组,所以对于奇异矩阵,讨论LU分解的意义并不大,LU分解并不限定矩阵是否奇异,奇异矩阵无非通过高斯消元后得到的U有全0行,通过P保证全0行均在后面几行,仍然能表示出对应的LU,但这种LU方程既不能求精确解,也不能保证数值稳定性,因此算法实现一般不去处理奇异矩阵。
向量基础
内积与正交
设
其内积表示为
若满足:
标准正交基
亦称规范正交基、标准正交向量组。对于一个单位向量组成的列向量组[α_{1}, α_{2}, ...α_{n}],如果满足任意两个向量均正交,即:
那么该向量组被称为标准/单位正交向量组。
施密特正交化
正交关系除了表征向量关系是线性无关的,还有的好处是容易看出基向量,对线性方程组求解、变换关系处理等都比较方便。
线性无关的向量均可以被正交化,常用的施密特二维/三维公式:
两个线性无关向量组成的向量组
进行标准正交化:
得到的
向量组
对于三维的情况,正交化公式为:
单位化同理。
QR分解
LU分解进行线性方程组求解时,总需要求解
QR分解的对象要求必须是列满秩矩阵
这里给出了两种QR分解方法,分别是基于上节拓展的施密特正交以及基于镜像变换的正交分解方法。
格莱姆-施密特(Gram-Schmidt)正交化
列满秩矩阵都可以表示成n个线性无关列向量形式:
当
其中
令单位化分母模长为
至此,QR分解的表达式就可以表出了,其中
QR分解本质
从QR分解容易看出,Q是一个标准正交基矩阵,表示了A列向量组成空间的基,这种计算特质决定了R必然是一个上三角矩阵,具体而言,看这样的一组矩阵内积:
这就是QR分解的本质——以矩阵A的一个列向量为基,其他线性无关的列向量总可以通过有限次正交分解,找到对该基有贡献的分量,这些分量的线性组合一定能表出该基,而且,列秩为n的矩阵,最多只需要n个向量的线性组合(因为只有n个基),每去除一列,列秩减1,组合数也减1,这就是R呈现上三角的根本原因。
注意,不是说列向量的线性组合,这对线性无关向量是不可能的,而是在能进行正交分解的前提下,这样的分解,实际上是改变了向量本身方向,这在复平面上实际上是乘上了一个(1,0)和(0,1)向量不能互相线性表出,但是其是可以互相“非线性”表出的,只需要旋转90°。
施密特QR分解示例
对矩阵
将矩阵表示成列向量形式:
根据上述公式,有:
根据系数对应关系(k系数对应上述分子括号结果,未详细列出),列出QR矩阵为:
可以使用python验证答案: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import numpy as np
A = np.array([[1, 1, 1],
[-1, 0, 2],
[0, 1, 2]], dtype=float)
Q, R = np.linalg.qr(A)
print("Q:")
print(Q)
print("\nR:")
print(R)
% Q:
% [[-0.70710678 -0.40824829 -0.57735027]
% [ 0.70710678 -0.40824829 -0.57735027]
% [-0. -0.81649658 0.57735027]]
% R:
% [[-1.41421356 -0.70710678 0.70710678]
% [ 0. -1.22474487 -2.85773803]
% [ 0. 0. -0.57735027]]
QR分解求解线性方程组
还是在LU那句话,只讲分解不讲求解无异于虎头蛇尾,也很简单。
利用上述矩阵构造一个Ax = b方程,例如求解:
即:
得:
豪斯霍尔德(Householder)变换
施密特QR分解的一个缺陷是其根据公式计算,涉及模长计算、作差、分式计算等,当引入浮点数计算时,得到的正交向量并不与其他向量严格正交,而且其他正交向量会基于该向量进行计算,导致误差传递和累积,导致分解的QR数值稳定性下降。基于镜像变换的豪斯霍尔德算法做QR分解则没有累积误差问题,其每个正交向量独立计算,不会产生累积情况,基本原理如下。
假设二维空间一对基向量为
容易看出其变换关系是:
这里不加证明地推广到一般情况,任意向量
而且容易证明
也可以进一步写为
基于豪斯霍尔德变换的QR分解
任意向量都能通过豪斯霍尔德变换转到x轴方向,换言之满足:
因为H矩阵本身是对称、正交、可逆的,所以可以进一步写成QR分解形式:
与施密特正交分解不同,对于
豪斯霍尔德QR分解示例
示例:对矩阵
令
转到x的目标向量为:
这两个向量镜像对称,得到与对称轴正交的单位向量为:
所以计算反射矩阵:
可知
现在只需要对第二个列向量降维,采取和上面一样的步骤即可: 令
目标向量为
故
有
同理
此时已经得到上三角矩阵了,综合两步的结果,为:
Q矩阵还需要计算乘积:首先将
故:
从该计算矩阵而言,这个例子很明显是参数设计过的,否则计算列向量-模倍的基向量时,很容易产生无理数和有理数的结合,导致手写计算很麻烦,这大概也是课本和考试不引入该正交方法的原因.而实际上除了没有误差累积问题,Householder算法的执行效率高于格莱姆-施密特的方法(参数低耦合,容易并行计算),也高于基于旋转变换的Givens的方法(一次性完成了列向量的正交,无需逐次旋转),所以OpenCV的QR分解算法默认采取了这种方式进行求解。
吉文斯旋转(Givens)变换
除了镜像变换,旋转变换也能够将
吉文斯旋转矩阵
吉文斯旋转变换表示为:
其中有:
对比此前OpenCV提到的旋转矩阵,负号在第二列,即:
变换c和s的位置仍然符合旋转特性,
这额外的三种形式对QR分解没什么大用,但是对SVD却很有用,在SVD那节将体会到。
吉文斯旋转QR分解示例
对矩阵
解:首先尝试用第一列的1将第一列的-1化为0,计算Givens矩阵:
那么有:
同理,令
使用第二列的
所以R矩阵为:
将
所以计算Q矩阵:
至此QR分解完成。
线性方程组
子空间(Subspaces)
在向量空间
子空间向量都属于
子空间本身是一个对线性运算封闭的空间,包括数乘、线性组合,意味着子空间中向量乘上任意倍数,或者组合都仍然属于子空间向量,也意味着子空间必须包括零向量。
对于二维向量空间
注意,子空间与子空间的交集常常是一个子空间,但子空间与子空间的并集,未必是一个子空间,例如
理解线性方程组矩阵,有很多视角可以做到,这里介绍一下MIT的方法(避免看不懂别人的文章),需要了解矩阵两个重要的子空间,即列空间和零空间。
列空间(Column Space)
矩阵的列空间是矩阵列向量张成的子空间,矩阵空间的维度决定了矩阵自身的向量空间,例如一个5×3矩阵,其自身维度空间最大可能是行数5,即
这里一点细节容易使人混淆:为什么秩最大为3,却可以有5个独立方程呢,秩等于3不是意味着有两行全0行吗,所以只有3个独立方程?
事实上列空间讨论的是Ax = b问题,假设这里秩等于3,指的是矩阵A可以化出2个全0行,但是这种化法可能无法将[A|b]增广矩阵也化出两个全0行,意味着5个方程是独立的。
零空间(Nullspace)
零空间是指使齐次方程Ax = 0满足的所有x向量张成的空间,即A矩阵方程通解。零空间衡量了一个线性方程组解的自由度,假设零空间只包含了一个原点,意味着任意系数的列向量线性组合,都不能互相抵消,意味着不能互相表示,那么就意味着线性方程组系数矩阵满秩,列向量均是线性无关的。
秩-零化度定理(Rank-Nullity Theorem)
对于矩阵: x = (0,0,1)、(0,0,2)等都是其齐次方程解,可见其零空间是一条直线
如果第二行也是全0,那么只有1个线性无关向量,可见零空间和秩是互相约束的。这就是秩-零化度定理:对于m×n矩阵:
矩阵的列数代表了列线性无关的最大潜力(最大可张成的维度),秩代表了实际上线性无关的个数(实际张成的维度),零空间的维度代表了线性相关(可自由组合)的维度个数。
线性方程组的求解
非齐次线性方程组的解可分成齐次方程通解和非齐次方程特解,也分别对应零空间解和列空间解。
零空间解/齐次方程通解
零空间的解也是国内教程中齐次方程的通解,其求解通过系数矩阵的消元来进行,例如矩阵A:
消元得到:
这里每行只有1、3列含主元,可见这里的主元列(pivot columns)是第一列和第三列,第二列和第四列都被称为自由列(free columns)。
分别令自由列为任意数,如:
以及
分别得到:
和
这两个通解向量张成的空间,就是零空间。
列空间解/非齐次方程特解
线性方程组有解是有条件的,即b必须来自列空间,从上述消元知道列秩为2,因此这里[A|b]增广矩阵最后一行应该全0,这里直接给出一个满足条件的方程:
非齐次方程的特解指的满足非齐次方程的一个解,无论什么手段,只要得知其一个解即可,一般采取最简单的回代,就是将自由列的x系数置0,即
非齐次方程通解 = 齐次方程通解 + 非齐次方程特解,即为:
特征值与特征向量
凡是讨论特征值和特征向量,讨论的矩形一定是方阵。
A是n阶矩阵,
特征方程
将定义式移位得到:
如果矩阵
求解特征值、特征向量示例
例: 求解方程
解:可知特征方程为:
即:
得到特征值:
- 当
时,经初等行变换: 可见自由列是第一列,令 ,得:
- 当
时,经初等行变换: 可见自由列是第二列,令 ,得:
- 当
时,经初等行变换: 可见自由列是第三列,令 ,得:
综上所述:矩阵A的特征值为1,2,3,对应的特征向量依次为
注意,如果存在特征值重复情况下,仍然称矩阵含有三个特征值、对应三个特征向量,而不是两个。
A相关矩阵的特征值、特征向量
 对于转置矩阵
对于转置矩阵
若矩阵方程满足f(A) = O,那么A任一特征值
特征值相关性质
特征值之和等于矩阵的迹(主对角线元素之和):
特征值的连乘等于矩阵的行列式值:
特征向量性质
对于k重特征值
,其对应的线性无关特征向量,最多只有k个(难证); 若
、 分别是两个不同特征值的特征向量,那么一定有 、 线性无关; 若
、 是矩阵A同一个特征值 的两个特征向量,那么 ( 不同时为0)仍然是 的特征向量;
特征向量缺失
在特征值重复情况下,代入特征值导致全零行出现,可能会导致特征向量缺失,如:
可见两个特征值都是3,代入得:
可见这个矩阵有两个相同特征值,但只能解出一个特征向量
当然这种情况要区别于:
复数特征值
三个结论:
实数特征值让特征向量伸缩,虚数特征值让特征向量旋转;
对称矩阵(
)的特征值为实数,反对称矩阵(A^{T} = -A)的特征值为纯虚数。(满足主对角线为零、上三角和下三角元素恰为反号); 矩阵具有特征值a+bi,其共轭a-bi也是特征值。
例如矩阵
矩阵相似
两个n阶方阵A、B,若满足
矩阵相似具有反身性(与自身相似)、对称性(互为相似)和传递性;
矩阵的相似引出了很多重要的特征:
但注意,以上条件均成立也不能反推矩阵相似;
其他特征:若有
矩阵相似对角化
n阶方阵A,若存在n阶可逆矩阵P,使得
A矩阵可相似对角化的充要条件是A存在n个线性无关的特征向量,这些特征向量组成的矩阵就是P矩阵,对应着A特征值组成的
所以有:
进一步的,如果将P矩阵的列向量进行正交化(常常用施密特正交方法),你会得到:
相似对角化判定
n阶方阵可相似对角化条件:
充要条件是有n个线性无关特征向量;注意,这并不要求矩阵必须可逆。
充分不必要条件:有n个不同的特征值;
综合1,2,另一个充分必要条件是当有重复的特征值时,重复特征值线性无关的特征向量数(几何重数)必须等于特征值重数(代数重数)。
实对称矩阵必可相似对角化。
对角矩阵
讨论对角化,主要是因为对角化的计算太好做了,假设
实对称矩阵
满足
实对称矩阵性质
A是实对称矩阵,有以下结论:
特征值是实数、特征向量是实向量;
不同特征值的特征向量正交。
不仅可以必然相似对角化成
,还存在正交矩阵Q满足 。 实对称矩阵相同特征值的特征向量,可能是正交,至少是线性无关。(对应到:普通矩阵的不同特征值特征向量一定线性无关,但相同特征值特征向量有可能线性相关。)
结论2的推导如下:
假设有
故:
因为
这个结论应用在正交化非常方便,意味着我们只需要对有相同特征值的特征向量进行施密特正交化,简化了部分计算。由此也看出实对称矩阵有很好的计算特性,所以尤其重要。
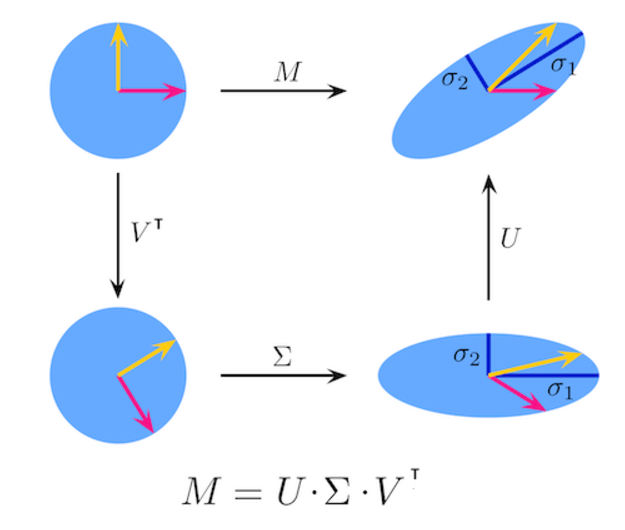
SVD奇异值分解
SVD奇异值分解广泛被认为是数值求解最稳定的算法之一,很多地方将奇异值和特征值混为一谈,其实确实差不多,严谨来说,特征值是针对方阵的定义,奇异值是
A是一个m×n矩阵,U为m×m正交矩阵、
左乘和右乘正交矩阵实际上只是对矩阵做了旋转,而特征值对角矩阵是一种放缩,如图:
 奇异值分解有一句传播甚广的话是:矩阵前百分之一的奇异值可能就占据了整个矩阵百分之九十以上的能量(信息量):
奇异值分解有一句传播甚广的话是:矩阵前百分之一的奇异值可能就占据了整个矩阵百分之九十以上的能量(信息量):
其中:
k代表矩阵的前k个(较大的几个)奇异值,因此使用低秩近似,都很好地概括了原矩阵的信息,所以SVD分解绝不限制于线性方程组求解的目的,在机器学习、深度学习、搜广推都有重要的应用地位,尽管这里我们仅讨论前者。
有趣的是我们为了数值稳定性来学习SVD分解,但是大多数博客(包括印度阿三的博客)都使用了一种不稳定的方法介绍SVD计算,这就是前面LU分解所述计算
SVD分解:数值不稳定方法(手推法)
这种方法在矩阵条件数很小时适用,而且计算比较简单。根据SVD分解:
如果A是正定矩阵,不难看出SVD分解等同于正交分解:
要进行SVD分解,只能单独算出U或者V,这里选择单独算V,因为U、V都是正交矩阵,所以有,令
如何求V,可见问题变成了求B矩阵的正交分解,根据特征值和特征向量能得到V和特征值矩阵
因为对角矩阵的逆是很容易算的,所以可以直接推出U:
至此得到了SVD三个矩阵。
这里的一个坑是通过
手推法的SVD示例
对矩阵:
解: 令
可知特征方程为:
解得:
实对称矩阵不同特征值特征向量必然正交,不用正交化,直接单位化后为:
得到V矩阵为:
对应的奇异值矩阵为特征值矩阵直接开方,但注意这应该是一个3×2矩阵:
这里不严谨地记其逆(严格来说只有方阵这样写,但意思意思):
所以剩下的U矩阵就出来了:
Golub-Kahan算法
SVD分解常见的特点是数值稳定性高,但计算效率慢,但上述过程似乎比QR分解都要来的快,原因已经叙述,我们计算了
主要分为三个步骤:
使用豪斯霍尔德或吉文斯变换将矩阵化成QR形式:
QR分解见见前文。 继续使用豪斯霍尔德变换或吉文斯变换将矩阵化成上双对角阵,所谓上双对角阵(upper bidiagonal matrix),即在主对角线上还有一条非零元素的对角线,例如:
双对角矩阵的优点是其是稀疏的,如果B是一个双对角矩阵,
乘积仍然是稀疏的,为三对角矩阵(tridiagonal matrix),即主对角线上下都还有一条对角线。 可见对于上三角矩阵,想要得到这样的矩阵:
豪斯霍尔德变换,将原来第一行的行向量
镜像变换到(1,2,0); 吉文斯旋转,可以选择使用
或者 将 变成0,根据前述的吉文斯旋转矩阵规律,如果选择用 计算c,那么应当右乘 ,如果使用 计算c,应该左乘
无论哪种方法,总而言之,总是可以找到若干的正交矩阵,使得R成为上双对角矩阵B:
当然严谨来说,1、2步可以合并,QR并不是一个必要过程(否则SVD稳定性不会超过QR分解)。
得到双对角矩阵后,下一步是整个算法的核心。对
进行吉文斯旋转优化,为求一个逼近的对角矩阵,这个过程称为“驱逐”(chasing); 假设有双对角阵为:
下一步就是在每个2×2方格中,不断地进行Givens变换,使得非对角元素不断地化成0,例如:对最左上角元素,使用右旋
(右乘吉文斯矩阵),能够将 置零,但是注意同时也会改变第一行和第二行的非零值,非2×2方格内的零值仍然能保持0,但方格内的零值(如元素(1,0)位置的0)有可能重新被引入非零值f',于是我们后面需要再对这个引入的f'再左旋 ,但又在刚刚归零的 引入了新的非零值。 但一个重要的特点是,随着迭代进行,非对角元素不断地被置零和引入非零的,其值会逐渐趋于很小的数,最后整个矩阵完成chasing而逼近一个对角矩阵。
最后
能够被表示成一个近似的对角矩阵,左旋和右旋一系列正交矩阵(吉文斯矩阵),此前整个过程左乘和右乘的Givens矩阵分别组成了B的U和V矩阵,再代回去继续乘上步骤1、2的吉文斯矩阵或豪斯霍尔德矩阵即是整个分解过程,可见如果手推是十分复杂的。
SVD的具体实现是多样的,例如吉文斯变换不同并行方法和计算顺序,而且精度截断也有各种的策略,其中一种Rust实现可以参考一篇很详尽的文章Implementing SVD algorithm in Rust。
实二次型
作为线性代数的终章,二次型在工程变换的研究中有重要作用。
定义
定义:n元变量组成的二次多项式称为n元二次型,即每项的幂数都是二次的,无论是考研还是工程应用,其系数一般是实数,有:
实二次型的特点是很容易写成矩阵的形式,其中二次项系数是主对角线元素,混合项系数除以二,分别放在关于主对角线对称的两侧元素,故实二次型总是对应一个实对称矩阵,如:
线性变换与合同
合同定义
若有:
即有
若变换矩阵C可逆,即f(x)、g(y)称合同二次型。
可见,合同二次型只是一个线性变换,例如同一个物体在不同坐标系下的量化,而正交是特殊的合同,代表量化结果只有旋转变换,没有拉伸变化。
合同关系和相似一样,具有反身性(与自身合同)和传递性。
标准形和规范形
研究线性坐标变换主要是希望得到一个没有混合项的坐标表示,如:
更严格的,如果此处的系数d仅可能是1、-1或0,这种二次型称为规范形。
相似正交化
至于二次型是如何化成标准型的,实际上就是把A写成正交化形式,所以其中一个方法还是将A先相似对角阵,写成
但是进一步的,这种方法既能计算变换矩阵Q,也计算了标准形矩阵(特征值组成的矩阵),也意味着我们无法将标准型进一步化成规范形,除非特征值本来就是-1、1和0。
这个方法主要工作量还是求解特征向量和特征值,然后进行施密特正交化,都是前文铺垫内容。
配方法
配方换元是另一种得到标准形的方法,这主要是中学的手段,不涉及特征值计算,也可以进一步得到规范形,直接看一个例子:
化二次型
为标准形: 解:原式 =
此第三项缺项,代表按旧的写,故:
注意,如果求x=Cy中的C矩阵,应该反过来求解: 故
特别的,如果一些初始式子只有混合项不含二次项,可以通过令
惯性定理
虽然配方法可以将任意的二次型化成标准形或规范形,但是得出来的矩阵C和特征值、特征向量是没有关系的,换言之如果需要计算特征值和特征向量,必须使用相似正交化的方法,两种方法的结果是互相独立的,但有一个共同点:即结果标准形正负系数的数量相同,其中正系数称正惯性指数,记为p,负系数称负惯性指数,记为q,选取任何可逆线性变换得到的标准形都满足这个条件,这就是二次型的惯性定理。
此外,可以证明二次型的秩等于正负惯性系数之和,r = p + q,而且两个二次型(实对称矩阵)合同的充要条件是正负惯性指数相同。
正定二次型与正定矩阵
正定二次型的定义是:对任意的
通俗而言就是不全为0的系数,该二次型总是恒大于0的,就是正定二次型,判别正定二次型和正定矩阵还有一些重要而方便的充要条件:
上述定义法;
二次型f的正惯性指数p = n元 = 秩;
存在可逆矩阵D,使得
; A与单位阵合同,即
A的特征值均大于0;
A的顺序主子式均大于0,例如三阶行列式
的顺序主子式有三个,从左上角开始取子式,为 、 和 ,A为正定时需满足此三行列式均大于0;
这里的规则2、3、4、5其实都是讲相似的事情,从5出发,假设特征值都大于0,即存在
从3或者4也可以推断出,实正定矩阵的必要条件是A必须是对称矩阵。
因此,判断矩阵是否正定,计算成本较低的方法是首先确认矩阵是否对称矩阵,若为对称阵则计算其顺序主子式是否均大于0即可。
正定矩阵也有一些重要性质:
A为正定阵,其逆矩阵、伴随矩阵、m次幂
、倍数 kA、与其合同的矩阵均正定;A、B正定,AB正定充要条件是AB = BA;
A正定且正交,A只可能是单位阵E,A = E;
全文完。
