
MySQL数据库学习笔记(二):多表查询与子查询
表间数据关系
一个数据库可以有很多表,表和表之间数据记录可能存在联系,MySQL定义了若干种关系,包括一对一、一对多、多对多和自我引用。
一对一(少用):两张表主键完全一对一,例如学生的成绩表、学生的身份证表,二者主键(学生)一一对应,没有额外的对象。
一对多(常见):一张表的对象作为另一张表的主键,或称另一张表多个外键指向当前表的主键。例如部门表和员工表,客户和订单表、分类和商品表。(心中默念:一个部门有多个员工,一个员工不能多个部门;一个客户多个订单,一个订单不可能多个客户......就是一对多)
多对多:默念不过关就是多对多。
自我引用:本表中创建一个外键,外键指向本表的主键。例如现在数据库记录了若干个回复评论的人,现在创建一个"回复对象"字段(外键),那么回复对象一定指向原来回复评论的人(主键),就是一种自我引用关系。
逐表查询与笛卡尔积错误
假设现在具有一对多关系的部门表和员工表,现在需要通过员工姓名,查找其部门名称;首先查询员工表通过姓名查询部门id,从部门表通过部门id查找部门name:
1 | SELECT department_id |
可见需要两条命令,说明请求发生两次,多表查询旨在优化这种查询方法,在语句中就应该描述关系信息。
笛卡尔积(交叉连接)错误
另一方面,多表信息能否直接融合成一个表?
- 答案虽然是肯定的,一对一关系的融合没有问题;但是如果是一对多,那么会出现大量的冗余空间,例如部门表与员工表融合,意味着每个部门表下都有一样的员工id/员工姓名作为主键,但是它们只在归属的部门查到信息,在不属于他们的部门,信息显示应该是null。但是MySQL并不清楚部门和员工关系,无法判断是否null,因此它只会将每个员工连接到每个部门,使得查询结果错误,称笛卡尔积错误/交叉连接。
下面的命令相当于将两个表融合查询:员工表具有107个员工信息,部门表含27个部门,那么它们将生成2889条信息项:大部分生成的记录项都是连接错误的:
1
2SELECT employee_id,department_name
FROM employees,departments;
多表查询
基本实现
避免交叉连接,只需要将主表(部门表)主键和从表(员工表)外键链接即可,加入连接条件:
1
2
3SELECT employee_id,department_name
FROM employees,departments
WHERE employees.department_id = departments.department_id;1
2
3SELECT employees.department_id --指明从哪个表查
FROM employees,departments
WHERE employees.department_id = departments.department_id;
n个表进行连接,至少需要n-1个连接条件,少于n-1个条件会出现笛卡尔积错误。
多表查询分类
1. 等值连接vs非等值连接
非等值连接指的是连接条件不是直接判断键是否相等,而是通过大小比较、between语句等判断键范围,例如员工表和工资评级表,需要判断员工工资落在哪个评级区间:
1
2
3SELECT e.employee_id,e.salary,jug.grade_level
FROM employees e,job_grades jug
WHERE e.salary BETWEEN jug.lowest_sal AND jug.highest_sal; --非等值
2. 自连接vs非自连接
自连接指的是连接关系主键和外键都来自同一张表,即出现了自我引用关系,例如员工表中,管理者字段一定也来自员工id字段,为了提高可读性,写法上还是命名了两张表对象,查询员工和管理者双方的id对应:
1
2
3SELECT stuff.employee_id,mt.employee_id --查员工、管理者id
FROM employees stuff,employees mt
WHERE stuff.manager_id = mt.employee_id; --员工管理者id=管理者id
3. 内连接vs外连接
内连接:上述所有多表查询例子都属于内连接,以部门表——员工表为例:内连接含义是——拿着员工表去查询对应部门的信息,或者拿着部门表查询员工的信息。
存在两种需求无法达到:
- 假设某个员工没有归属部门,那么该员工不会出现在查询结果。
- 假设某部门没有员工,该部门也不会出现在查询结果。
这两个需求就是左外连接和右外连接,左和右只是相对的,一般取决于select语句from表的顺序关系。
左外连接可以查询到所有员工(包含没有部门信息的),右外连接可以查询到所有部门(包括没有员工的),它们对应项在结果中以null形式给出,内连接只针对既分配了部门、也分配了员工信息的完全匹配项。
当需求出现所有部门信息、所有员工部门信息等,应该采取外连接。
SQL99语法的内连接、外连接
上述所有from 表一、表二......,where 连接条件1、连接条件2......语法都是SQL92约定的语法,MySQL不支持SQL92的外连接语法(在连接条件需要全匹配的表后加“+”号),只能使用SQL99的语法。
内连接语法:JOIN一个表,就要ON一个条件,重写薪资评级的内连接,严格规定了每一张表的查询条件。
1
2
3
4
5
6--SQL99 内连接
SELECT stuff.employee_id,stuff.salary,jug.grade_level
FROM employees stuff JOIN job_grades jug
ON stuff.salary BETWEEN jug.lowest_sal AND jug.highest_sal;
--JOIN ...
--ON ...
外连接语法:指定LEFT (OUTER) JOIN或者RIGHT (OUTER) JOIN
找出所有员工对应的部门:(含未分配部门的员工)左外连接 1
2
3SELECT stuff.first_name,department_name
FROM employees stuff LEFT JOIN departments d
ON stuff.department_id = d.department_id; --ON 连接条件RIGHT JOIN(右外连接),问题就变成了:找出所有部门对应的员工名单(包含无员工的部门)。
7种Join实现
至此实现了三种多级查找模式,分别是左外连接、右外连接、内连接: 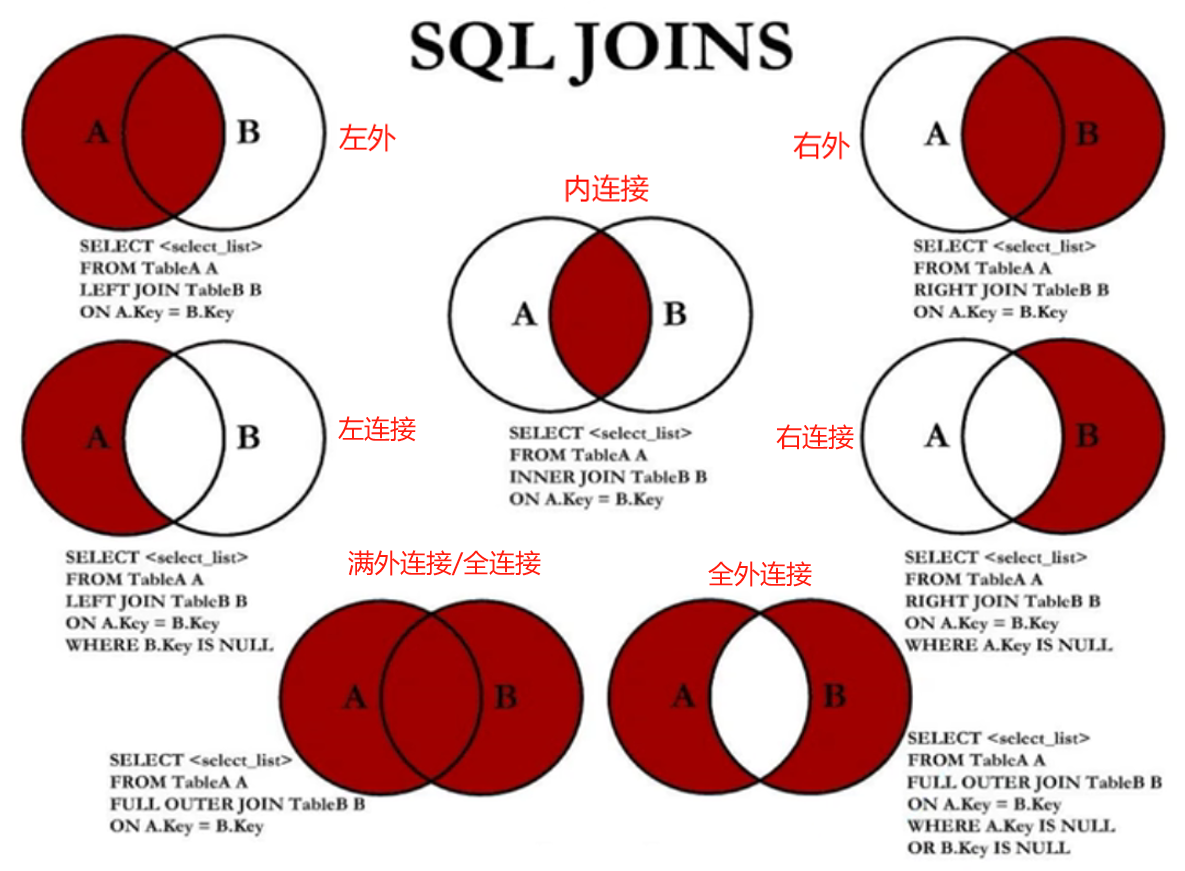 集合的关系还存在另外四种关系,暂称左连接、右连接、全外连接、满外连接。(名称说明:英文里通常把这其中三种关系当成exclusion,因此如果是Left
Join,一般指左外连接,如果是Left Join with Exclusion/Left Join exclude
Inner
Join,就是指这里的左连接了,右同理,全外连接是满外连接的exclusion,称Full
Outer Join with Exclusion)。
集合的关系还存在另外四种关系,暂称左连接、右连接、全外连接、满外连接。(名称说明:英文里通常把这其中三种关系当成exclusion,因此如果是Left
Join,一般指左外连接,如果是Left Join with Exclusion/Left Join exclude
Inner
Join,就是指这里的左连接了,右同理,全外连接是满外连接的exclusion,称Full
Outer Join with Exclusion)。
Left/Right Join with Exclusion
只需要在左外连接、右外连接的基础上排除中间部分即可,注意不要使用"=",使用“<=>”或者ISNULL()/IS NULL;
Left Join with Exclusion: 未分配部门的员工 1
2
3
4SELECT stuff.last_name,d.department_name
FROM employees stuff LEFT JOIN departments d
ON stuff.department_id = d.department_id
WHERE d.department_id IS NULL; --排除条件,排除右表
Right Join with Exclusion: 没有员工的部门 1
2
3
4SELECT stuff.last_name,d.department_name
FROM employees stuff RIGHT JOIN departments d
ON stuff.department_id = d.department_id
WHERE stuff.department_id IS NULL; --排除条件,注意是排除左表
Full OUTER JOIN and Full OUTER JOIN with Exclusion
在Oracle中,直接将上述的LEFT JOIN修改成FULL OUTER JOIN就能实现满外连接,然而MySQL仍然不支持这种SQL语法,因此满外连接、全外连接等只能通过并集实现,使用Union关键字;
Union有两种模式:Union和Union ALL,其中Union会对两个集合重复的部分去重,使得整个并集没有重复的元素,而Union ALL不会。因为去重存在,UNION的资源和开销大于后者,因此习惯上优先使用Union ALL,只要选择合适的并集对象,就无需进行去重。
Full OUTER JOIN with Exclusion:
将两个左右连接拼接,就是全外连接:要么员工没部门、要么部门没员工
1
2
3
4
5
6
7
8
9SELECT stuff.last_name,d.department_name
FROM employees stuff LEFT JOIN departments d
ON stuff.department_id = d.department_id
WHERE d.department_id IS NULL --左连接
UNION ALL
SELECT stuff.last_name,d.department_name
FROM employees stuff RIGHT JOIN departments d
ON stuff.department_id = d.department_id
WHERE stuff.department_id IS NULL; --右连接
FULL OUTER JOIN:
并集可选:左外连接+右连接、左连接+右外连接、左+内+中,选择第一种:显示所有员工、部门信息,员工没有对应部门、或者部门没有员工的,以NULL表示。
1
2
3
4
5
6
7
8SELECT stuff.last_name,d.department_name
FROM employees stuff LEFT JOIN departments d
ON stuff.department_id = d.department_id --左外连接
UNION ALL
SELECT stuff.last_name,d.department_name
FROM employees stuff RIGHT JOIN departments d
ON stuff.department_id = d.department_id
WHERE stuff.department_id IS NULL; --右连接
SQL99的Natural JOIN 和 USING
也许不怎么常用:Natural JOIN代替JOIN时,会自动将两个表的相同字段作为条件,即无需人为填写ON...条件,注意所有重复的字段都会被连接。
USING(department_id)代替ON stuff.department_id = d.department_id,连接两张表指定的相同的字段名,但只能表示等值连接,和where、on等语句等效,后两者作用更大,当查表数目大于3张时,FROM..WHERE语句优于JOIN语句。
子查询
子查询实际上就是一种嵌套查询,往往有需求需要从数据库查出某个结果,再从结果中滤出我们进一步的需求,就需要嵌套一层查询,即子查询,或称内查询,对应的外层查询称外查询/主查询。
嵌套查询的三种方法
- 需求:找出工资高于Abel员工的员工姓名:
多次逐表查询:
1
2
3
4
5
6
7SELECT last_name,salary
FROM employees
WHERE last_name = 'Abel'; --Abel工资11000
SELECT last_name,salary
FROM employees
WHERE salary>11000; --二次请求多表查询之自我引用:
1
2
3
4SELECT e2.last_name,e2.salary
FROM employees e1,employees e2
WHERE e1.last_name = 'Abel'
AND e2.salary>e1.salary;子查询:
1
2
3
4
5
6
7SELECT last_name,salary
FROM employees
WHERE salary>(
SELECT salary
FROM employees
WHERE last_name = 'Abel'
);
子查询的分类
- 按照返回结果条目数:单行子查询和多行子查询;
- 子查询的结果是一项,则是单行子查询;如果是多项结果,就是多行子查询。
- 按照外查询对象和内查询对象的相关性:相关子查询和不相关子查询;
- 上面需求找出比Abel工资高的,无论外层谁来都是和Abel比较,因此是不相关子查询;如果需求修改成“比本部门平均工资高的”,就是相关子查询,因为不同的人,需要和自己对应部门平均工资相比,内查询的对象本身并不固定。
1. 单行子查询
单行子查询一般使用比较符进行比较,其中'<>'也可以表示'!='不等于。
子查询不仅用于WHERE语句中,也可以用于CASE语句中:
- 需求:和location_id=1800的员工相同部门的员工location为Canada,否则为USA;
注意两个细节:
- case前应该逗号!!!
- 当case用了别名,可以不用select也会显示,不应该重复指明。
1 | SELECT employee_id,last_name, --这题用到了多表信息,多表是否连接都允许 |
2. 多行子查询
- 多行子查询关键字
当子查询返回多于一项结果,我们仍然使用普通比较符时就会出现
error:Subquery returns more than 1 row,需要了解多行比较逻辑:
IN(多行子查询):结果在内查询中包含。
ANY/SOME(多行子查询):和单行比较符一起用,代表任意一个;例如salary<ANY(...),只需要低于最高的就会有结果。
ALL(多行子查询):和单行比较符一起用,代表所有,例如salary<ALL(...),需要低于全部,才会有结果。
- 嵌套聚合函数实现 其次,多行子查询的结果可以被当成是一张新表,通过这个特性可以实现MySQL的嵌套聚合函数功能:
- 需求:查找最低平均工资的部门,如下四种方法:
1 | --Oracle支持,MySQL报错写法: |
- 空值问题 单行子查询的空值容易察觉,多行子查询包含空值时,任何比较结果都会返回空结果,应该留意子查询是否包含空情况。
3. 相关子查询
相关子查询的特点是,将主查询的某个字段传入子查询,子查询自己的表字段和主查询字段比较使用,两者对象具有相关性。
- 需求:查询每个部门中大于部门平均工资的last_name、salary、部门id信息。
1 | SELECT last_name,salary,department_id |
从嵌套聚合函数实现分表的思想知道,子查询语句可以作为FROM新表查询,因此也可以这样解决:
1
2
3
4
5
6
7
8SELECT e1.last_name,e1.salary,e1.department_id
FROM employees e1,(
SELECT department_id,AVG(salary) avg_salary --计算每个部门平均工资
FROM employees
GROUP BY department_id
)e2
WHERE e1.department_id = e2.department_id --WHERE条件字段必须在主查询或者子查询中包含
AND e1.salary > avg_salary;
实际上,子查询的位置是灵活的,除了常见的WHERE,除了GROUP BY和LIMIT不用子查询语句,可以放在HAVING、FROM、ORDER BY、SELECT、CASE等语句上。
关键字:EXISTS与NOT EXISTS
这两个关键字用于查看子查询是否返回至少一行数据,如果子查询返回一行数据,那么EXISTS立马返回真并且停止搜索;如果使用NOT EXISTS,只有子查询没有返回任何行,那么才会返回真,而且这个关键字在大型表查询性能优于IN和NOT IN。
子查询在一些情况下,能够实现多表查询的任务,例如EXISTS可以表示内连接,NOT EXISTS能够表示左右连接等。
查找有归属部门的员工信息:使用员工的department_id去匹配部门,如果匹配成功就返回真,该记录加入结果,继续使用下一位员工匹配,实现了内连接等效功能。
1
2
3
4
5
6SELECT e.last_name
FROM employees e
WHERE EXISTS (
SELECT * FROM departments d
WHERE e.department_id = d.department_id
);
查找没有归属部门(部门为NULL)的员工信息:只有匹配失败才返回真。
1
2
3
4
5
6SELECT e.last_name
FROM employees e
WHERE NOT EXISTS (
SELECT * FROM departments d
WHERE e.department_id = d.department_id
);
如果SELECT字段包含两个表,那还是JOIN更为方便,且多表查询效率通常更高效(子查询也可能被DBMS优化成多表查询),否则需要在SELECT嵌套子查询。
