
MySQL数据库学习笔记(一):概述与基本SELECT语句
数据库相关概念
数据库(Database,DB):本质是一个文件系统,保存了一系列有组织的数据。
数据库管理系统(Database Management System,DBMS):操作和管理数据库的大型软件,用户通过此访问和管理数据库数据。
结构化查询语言(Structure Query Language,SQL):数据库交互语言。
关系型与非关系型数据库
RDBMS
RDBMS(RDBMS,Relational~):最古老的数据存储形式,使用二维表格的形式(行、列)来存储数据。
优点:支持复杂查询和事务处理(加锁等)、数据以表格形式存储,表间可以建立关系(多表查询)。
缺点:扩展性较差、大数据处理性能较弱,难以存储非结构化数据。
常用关系型数据库:MySQL、Oracle、SQLites等
非关系型数据库
键值型数据库:按Key-Value形式存储,Key是唯一标识符,查找速度极快。但是不支持条件过滤,如果不清楚具体数据位置,就要遍历所有的键,消耗性能,经典的使用场景是作内存缓存。最流行的键值型数据库——Redis。
其他:文档数据库、搜索引擎数据库(倒排索引)、列式数据库(降IO复杂度)、图形数据库等。
表/实体集、记录/实体、字段/属性
表(table)/实体集(class):数据库有多张表,不同的表有唯一标识自己的名称;
记录(record)/实体(instance):表中的一行数据(也即一个对象的所有特征)。
字段(field)/属性(attribute):表中一列数据(某个特征)。
表的关联
四种关系:一对一关系、一对多关系、多对多关系、自我引用关系;
Start MySQL
msi安装略。
cmd登录: 1
2mysql -u root -p #默认端口号、Ip(-P 3306 -h localhost)
#输入密码xxx
原始数据库
1 | show databases; |
| 原始四个数据库 | 作用 |
|---|---|
| information_schema | 保存 MySQL 数据库服务器的系统信息(数据库的名称、数据表的名称、字段名称、存取权限、数据文件 所在的文件夹和系统使用的文件夹 |
| mysql | 运行时的相关系统信息,如数据文件夹、当前使用的字符集等 |
| performance_schema | 用于监控 MySQL 的各类性能指标 |
| sys | 以通俗方式展示性能指标,帮助监控技术性能 |
更改编码方式(仅5.7以下版本
MySQL经历了5.7——8.0的版本跳跃,仅5.7及以下版本需要额外进行编码设置以适应插入中文需求。
查看编码: 1
2show variables like 'character_%'; --字符集
show variables like 'collation_%'; --排序字符规则
修改 1
2
3
4
5
6[mysql] # 约63行
default-character-set=utf8 #默认字符集
[mysqld] #约75行
character-set-server=utf8
collation-server=utf8_general_ci
Hello World
1 | create database hello_world_db; --数据库 |
目前存在数据库,且为空表,插入记录: 1
2
3
4insert into student values(1,'Eden');
insert into student values(2,'小爱同学')
select * from student; --查看student表的所有项
查看表的创建信息: 1
2
3
4
5
6
7
8
9
10
11
12
13
14show create table student\G;
/*
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`id` int DEFAULT NULL,
`name` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci //存储引擎、字符集
1 row in set (0.00 sec)
ERROR:
No query specified
*/
删除表、删除数据库: 1
2drop table student;
drop database hello_world_db;
SQL基本概述
美国国家标准局(ANSI)发布了SQL多种标准,如SQL-92、SQL-99等,不同的数据库(MySQL、Oracle等)规则大都遵循这些标准,仅存在部分细节上的差异。
SQL分类
SQL语言在功能上分成三大类:
DDL(Data Definition Languages,数据定义语言):定义数据库、表、视图、索引等,创建、删除、修改数据库和表的结构;例如Create、Drop、Alter、Rename等;
DML(Data Manipulation Language,数据操作语言):也即最常用的增删改查。如Insert、Delete、Update、Select等;
DCL(Data Control Language,数据控制语言):于定义数据库、表、字段、用户的访问权限和安全级别;如Grant、Revoke、Commit、Rollback、Savepoint等。
另外,查询语句被单拎出来称DQL(Data Query Language,数据查询语言);Commit、Rollback等称TCL(Transaction Control Language,事务控制语言)。
SQL规范
Windows环境大小写不敏感,Linux环境下大小写敏感,建议: - 数据库名、表名、字段名、字段别名等小写;
关键字、函数名、变量名大写
字符串、日期等使用单引号;
数据导入
命令行导入
1
source F:\MySQL_Data\xxx.sql
Navicat导入: 左侧组——运行SQL文件———选择文件导入。
基本Select语句
SELECT ... 变量、表达式、常量
1
2SELECT 2;
SELECT 100*12;SELECT 字段名 FROM 表名
1
2
3
4
5
6
7
8SELECT *
FROM student; --全部字段
SELECT 12*100
FROM DUAL; -- 伪表DUAL
SELECT student_id,student_age
FROM student;字段别名 给student_id起别名sdid,其中AS关键字可省略,只需要空格隔开即可.
1
2SELECT student_id (AS) sdid
FROM student;如果别名本身含空格,应该使用双引号引起
1
2SELECT student_id (AS) "sd id"
FROM student;去除重复行 使用关键字DISTINCT:
1
2SELECT DISTINCT class_id
FROM student;误用:
1
2
3
4
5SELECT student_id,DISTINCT class_id --行数不匹配,报错
FROM student;
SELECT DISTINCT student_id,class_id --只有同时重复,才会被去除
FROM student;空值参与运算 如果select到的值包含null(不等同0、空字符),运算结果为null。
着重号解保留字 数据库名、表名、字段名与保留字重复,名称必须使用着重号``引起来。
常量查询 从每个行中查询和匹配一个常量,或者将这个常量转为列字段;
查找David,并且命名新的字段为god。 1
2SELECT 'David' AS god,salary
FROM employees;
显示表结构
1
DESCRIBE employees;
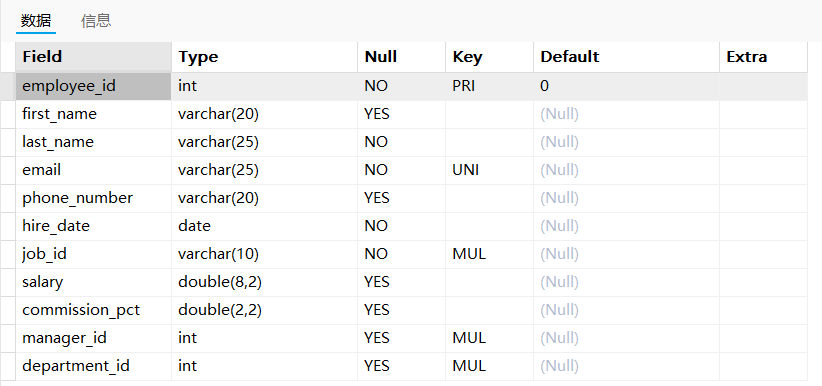 包含字段、数据类型、是否允许Null、约束关系、默认值、额外描述等。
包含字段、数据类型、是否允许Null、约束关系、默认值、额外描述等。WHERE过滤语句 只选择department_id = 90的人员信息、King字符信息:注意查询字符应该遵循数据库大小写,Windows下MySQL允许不严谨的大小写查询,而其他环境、或者其他数据库Oracle等不会提供这样的兼容性。
1
2
3
4SELECT *
FROM employees
WHERE department_id = 90;
-- WHERE last_name = 'King'; #字符查询
注意:WHERE过滤时不能使用别名,因为是先过滤再SELECT,使用别名会报错:
1
2
3
4-- fault test
SELECT last_name,salary*12 anual_money --anual是salary*12别名
FROM employees
WHERE anual_money BETWEEN 20000 and 40000; --fault
运算符
1. 加减+-
如果出现数字+字符,字符本身是数字串,可以隐式转换成数字再参与运算,如果是其他字符无法转换,按结果0进行计算。如果参与运算出现浮点数,结果也是浮点数。
1
2
3
4
5SELECT 100+'101' --结果201
FROM DUAL;
SELECT 100+'a' --结果100
FROM DUAL;
2. 乘除*/
乘法出现浮点数,结果就是浮点数;
除法无论除整数还是浮点数,结果都是浮点数。除不尽自动保留4位小数;除以0结果位Null;
3. 取模(余)MOD/%
求偶数employee_id的所有记录。 1
2SELECT * FROM employees
WHERE employee_id%2 = 0;
4. 比较(</>/=/!=/<=/>=/<=>)
字符串之间的比较,从前到后按ASCII码值。
数字、数字字符串等效比较
数字、数字字符和ASCII字符比较,ASCII字符转位0而不是ASCII码值!
只要其中一个值为Null,结果一定为Null,无论另一个是否Null,因此student_id=null作为WHERE条件不能过滤出任何student_id为null的结果。
1
2
3
4
5
6
7
8
9
10
11SELECT 'abc'>'aba' --返回1
FROM DUAL;
SELECT '100'=100 --返回1
FROM DUAL;
SELECT 'a'= 97 --或='97' ###返回0,这种比较不能转换ASCII码
FROM DUAL;
SELECT 'a'= 0 --或='0' ###返回1
FROM DUAL;安全等与<=>:额外增加功能,使NULL值能够进行判断和过滤,其他作用同“=”。
1
2
3
4
5
6SELECT NULL<=>NULL --返回1 ,如果是“=”则返回NULL或无返回。
FROM DUAL;
SELECT * FROM departments --正常返回manager_id为NULL值的记录
WHERE manager_id<=>NULL;
5. 常用运算符
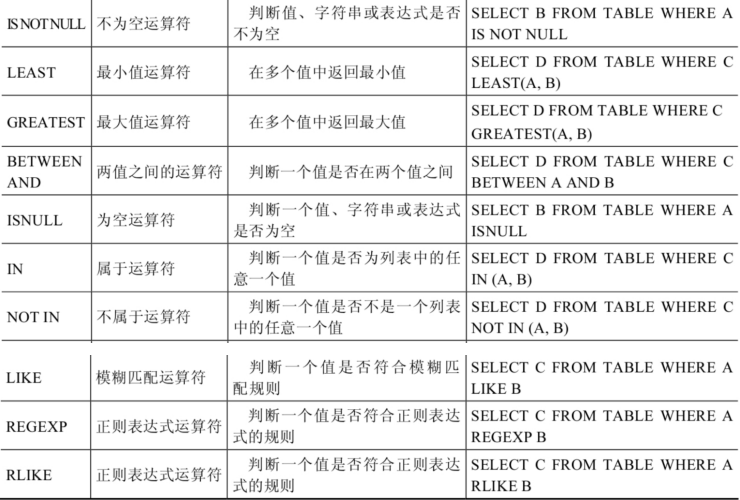 其中:
其中:
LEAST/GREATEST:括号对象可以是两个以上。
BETWEEN AND讨论的是闭区间;
ISNULL/IS NULL/<=>NULL,三者等效。
IN用于离散数据筛选,例如:
1
2
3
4
5
6SELECT * FROM employees
WHERE department_id in (10,20,30);
-- 相当于WHERE department_id=10 OR department_id=20 OR department_id=30;
-- 注意一定不能写成WHERE department_id=10 OR 20 OR 30; #or运算符不能默认拼接前面字符模糊匹配:LIKE配合通配符"%"和"_"使用:其中“%”代表多个字符或0个字符;"_"代表一个字符,如果查找内容含“%”或者"_"字符,对应位置加转义字符'\'即可。
1
2
3
4
5
6
7
8
9
10
11-- last_name含a且含有e的:去除前面%,代表a开头或者e开头,去除后面%,代表a结尾或者b结尾。
SELECT * FROM employees
WHERE last_name LIKE '%a%' AND last_name LIKE '%e%';
-- last_name第二位为e、第五位为a的:
SELECT * FROM employees
WHERE last_name LIKE '____a%' AND last_name LIKE '_e%';
--查找last_name第四、五位为"_a"的记录。
SELECT * FROM employees
WHERE last_name LIKE '___\_a%';
其余运算符
赋值运算符(:=)、逻辑运算符(NOT!、OR||、AND&&、XOR)、位运算符(&、|、^(异或XOR)、~、>>、<<)基本用法同其他编程语言。
数据排序
MySQL默认实现就是数据添加顺序,支持对数据进行单列排序、多列排序,排序本身分为升序和降序:
- 排列关键字:ORDER BY,升序ASC(默认),降序DESC;
1
2
3
4SELECT last_name,first_name,salary
FROM employees
(WHERE ...)
ORDER BY salary,last_name ASC(DESC);
WHERE过滤语句要在排序语句前;
多列排序时,第一个参数如果已经排好序(无重复元素),第二个排序参数无效,否则会对第一次排序的重复元素再排序
1
2
3SELECT last_name,salary
FROM employees
ORDER BY salary ASC,last_name DESC;
数据分页
分页存储,节省资源便于响应,也方便查看。
关键字:LIMIT off,page_size; 偏移量off(忽略默认为0),每页项数page_size。
LIMIT page_size OFFSET off; 第二种写法
1 | SELECT * FROM employees |
LIMIT作为分页语句,一般放在最后(过滤、排序语句之后)。
