
操作系统MIT 6.S081 xv6内核(十一):Memmory Map实验
mmap实验
这个实验算是我花时间最长的实验了,定位问题和解决问题的时间大概是4:1,除了信手沾来的大佬,我认为很难按照hints从头写到尾写完解决完所有报错就顺利过关,因为有时候甚至很难确定问题的具体位置。这个实验很有必要听从Robert教授的之前教导,不要想着一次实现所有功能,尝试先实现一点,调试成功再去继续;因此本次实验概述既参考了hints本身固有逻辑,更多是从调试步骤解决,我相信这样的思路会为读者省下很大一部分定位问题的时间。另外,这个实验设计应该是有bug的,这部分疑惑连同debug问题被记录在Q&A;
实验目的
这个实验意在为xv6加入文件映射内存特性,所谓文件映射内存,就是将文件直接map到某个内存,直接对文件进行读写,绕过了read/write文件调用系统调用、将数据读到内核缓冲区再拷贝用户空间的过程,实现高效率的文件修改;文件映射内存涉及的内容还是比较综合的,要求有文件操作、内存映射,此外文件不可能常驻内存,因此必然采用了Page
Fault机制来进行懒分配、就需要处理系统陷入,可见它几乎综合了前面的所有实验特性,设计不能不说别出心裁;
此外,本实验的mmap设计参考函数如下;其中xv6中简化成addr==0,offset==0,即每个进程的文件映射必须从默认位置开始,不支持自定义位置,offset为0代表不支持自定义偏移量;实际上在Linux中,offset也定义成页帧的倍数,几乎没有操作系统愿意处理一个奇怪的偏移量来引入额外的对齐处理,一种简单的方式就是将不对齐的部分数据填充成无意义数据,并且加以标记以便读取时区分即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)
//参数:
addr:请求映射的起始地址;
length:文件映射的总长度(字节)
prot:定义了映射内存区的访问权限
- PROT_READ:允许读取。
- PROT_WRITE:允许写入。
- PROT_EXEC:允许执行代码。
- PROT_NONE:不允许访问。
flags:定义了映射的行为和类型,xv6只定义了两个
- MAP_SHARED:共享内存映射,所有映射该文件的进程共享(若修改会更新到磁盘文件)
- MAP_PRIVATE:私有映射;
//Linux支持但未被xv6采用的:
//- MAP_ANONYMOUS:匿名映射,不与任何文件关联;
//- MAP_FIXED:要求必须精确映射到addr下,不能做到返回失败;
fd:文件描述符
offset:映射的起始偏移量
取消文件映射对应的函数是: 1
2
3int munmap(void *addr, size_t length);
- addr:映射位置的虚拟地址
- length:映射文件大小
具体实现
Makefile加入mmaptest,注册mmap和munmap的系统调用,sys_mmap和sys_munmmap返回空调用,步骤参考Commit即可,不赘述,编译通过继续以下步骤;在一些文件中我定义了报错宏:
后面发现这不是必须的,可以直接使用panic,不同的是errlog定义返回-1,而这个分支的panic不是结束进程,而是进入循环阻塞,但是有个位置的panic会导致异常出错,见Q&A1
mmap思路:mmap将用户文件直接映射到用户空间内存,由于xv6没有内存分配器的机制,我们只能手动地在每个进程维护一个vma结构体数组,大小为16(来自hints),vma结构体内部含有参数信息,如
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset),相应记录了文件在内存的起始地址、大小、内存访问权限、私有/共用内存、文件数据等,offset约定为0,因此这个字段无需考虑,只需要将文件映射到内存即可,addr为0,不代表起始地址为0,而是按照我们的分配策略默认分配内存地址,请注意这个区别。因此在kernel/proc.h定义:顺便在1
2
3
4
5
6
7
8
9
10
11
12
13
14
struct vma{
uint64 vma_start; //映射起始虚拟地址
uint64 vma_length; //映射大小
int vma_prot; //内存权限,即PTE标志位
int vma_flags; //内存私有/共有,影响行为判断;
struct file* vma_file; //fd found struct file;
int vma_used; //是否被使用了;
};
struct proc{
......
struct vma vma[VMA_MAXNUM];
};kernel/proc.c分配初始进程allocproc函数和freeproc回收进程,加入初始化代码:1
memset(p->vma,0,sizeof(p->vma));
然后我们的coding思路是从三个部分进行,分别为
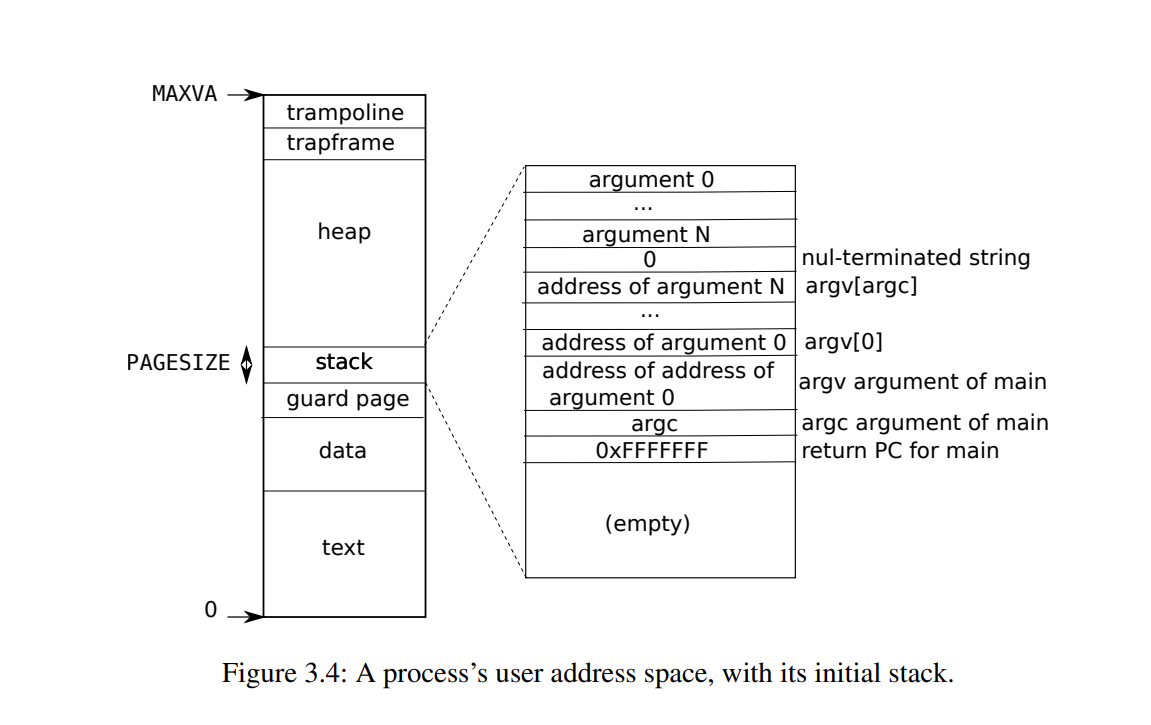
sys_map+trap、vma_unmap+exit+fork、sys_unmap;考虑虚拟内存分配的问题,在xv6中,用户虚拟内存空间示意图如下;很大的特点是
stack向下延申,heap向上延申,heap的空间会通过umalloc等机制分配出去,因此为了防止冲突我们选择从TRAPFRAME以下;TRAPFRAME是跳板页以下PGSIZE大小的空间,请注意,只有用户空间的虚拟内存能够分配这块空间。如果是内核的虚拟内存空间,TRAPFRAME以下对应的是若干个内核栈空间,不能被分配使用。所以只有用户虚拟内存能够这样做(内核文件不能也没必要也不安全);sys_mmap就是定义end=TRAPFRAME开始,寻找未使用的vma[i],找到了,就将其vma_start定义为end-文件大小length,这块内存就被vma[i]使用,然后更新下一个的end为vma_start,这样紧凑地完成第一次16组分配后,end会更新到被占用内存的下方;一个很明显的缺点是,尽管上方某个vma[i]被释放了内存,end永远也是最下方占用内存的下方开始分配,这种方法使得逻辑处理足够稳健,但是内存开销很大;尽管如此,VMA_MAXNUM=16意味着最多能映射16个文件,每个文件最大是268块(268*1024字节)(见File System),xv6堆区空间至少近百MB,因此无需考虑end-length的越界问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49uint64 sys_mmap(void){
uint64 va,length,offset;
int prot,flags,fd;
struct file* file;
if(argaddr(0,&va)<0||argaddr(1,&length)<0||argint(2,&prot)<0 \
||argint(3,&flags)<0||argfd(4,&fd,&file)<0||argaddr(5,&offset)<0)
errlog("parameter fault\n");
//va and offset should be 0
if(va!=0||offset!=0)
errlog("va/offset non-zero\n");
struct proc *p = myproc(); //current process
//报错://文件无效、不可读文件设置读、不可写文件设置写且设置了写回(为什么不是或后面会知道)
if(file->ref<1||(!file->readable&&(prot&PROT_READ))|| \
(!file->writable&&((prot&PROT_WRITE)&&(flags&MAP_SHARED))))
errlog("mmap file flags wrong\n");
length = PGROUNDUP(length); //mmap length aligned
struct vma *free_vm;
int found = 0;
uint64 end = TRAPFRAME; //从TRAPFRAME开始向下分配
for(int i = 0;i<VMA_MAXNUM;i++){
if(p->vma[i].vma_used){ //为了更新end
end = PGROUNDDOWN(p->vma[i].vma_start); //end aligned
}
else if(p->vma[i].vma_used==0&&!found){ //找到第一个未被使用的vma记录成free_vm
free_vm = &p->vma[i];
free_vm->vma_used = 1;
found = 1;
}
}
end=end < TRAPFRAME? end : TRAPFRAME; //end是否被更新到TRAPFRAME下方
if(!found)
errlog("Full vma\n");
//记录使用free_vm的内存和文件信息;
free_vm->vma_start = end - length; //start aligned
free_vm->vma_length = length;
free_vm->vma_prot = prot;
free_vm->vma_flags = flags;
free_vm->vma_file = file;
filedup(free_vm->vma_file); //文件映射需要引用文件,确保不要映射着就被删了
return free_vm->vma_start; //返回内存起始地址
}
sys_mmap返回了一个起始内存地址,意味着vma_start到vma_start+vma_length都是vma使用的虚拟空间,但是此时使用sys_mmap映射文件是有问题的,因为物理内存没有分配,会触发page fault,因此在陷入处理要进行物理页的分配,也即页懒分配,注意每次分配只会分配一个页帧,不会一次性分配整个vma的页帧;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41else if(r_scause()==13||r_scause()==15){
uint64 va = r_stval();
struct proc*p = myproc();
struct vma*vma=0;
for(int i = 0; i<VMA_MAXNUM; i++){ //最大16个vma,找出目前pagefault的是哪一个
struct vma*vmai = &p->vma[i];
//va在这个范围说明找到对应的vmi
if(vmai->vma_used && va>=vmai->vma_start && va < vmai->vma_start+vmai->vma_length){
vma = vmai;
break;
}
}
if(vma==0)
exit(-1); //have to exit -1,见Q&A
//panic("Page Fault No Vma");
uint64 pa = (uint64)kalloc(); //申请物理页
if(!pa)
panic("Page Fault No pa");
memset((void*)pa,0,PGSIZE);//necessary,cause if non-zero can't pass the test
ilock(vma->vma_file->ip);//data from dip to ip
if(readi(vma->vma_file->ip,0,pa,va - vma->vma_start,PGSIZE)<=0)
panic("trap readi failed"); //data from ip to pa
iunlock(vma->vma_file->ip);
int perm=PTE_U|PTE_V;
if(vma->vma_prot&PROT_READ)
perm|=PTE_R;
if(vma->vma_prot&PROT_WRITE){
perm|=PTE_W;
perm|=PTE_Dirty; //necessary or unnecessary,见下文及Q&A
}
if(vma->vma_prot&PROT_EXEC)
perm|=PTE_X;
if(mappages(p->pagetable,PGROUNDDOWN(va),PGSIZE,pa,perm)!=0){ //map va to pa
kfree((void*)pa);
panic("mappages fault");
}
}其中在
kernel/riscv.h定义脏位,用于标识某个页被修改而未被写回磁盘,这里没有额外的机制判断是否被修改,只能笼统地认为假设内存开放了写权限,就需要重新写回,因此将脏位置位;其中在pte结构中,系统定义了flag的第7位为脏位(见基础理论一文的页表内容),如果我们在该分支定义了脏位为第7位,xv6应该在某处(我没找到)实现了置位,因此上面的perm|=PTE_Dirty可以被忽略,但是如果我们自定义使用预留位,例如第9位,上面的置位操作必须保留;1
2
3
4//kernel/riscv.h
//or同时,页懒分配访问虚拟内存不应该提示
unmap,因此kernel/vm.c也需要修改:1
2
3if(PTE_FLAGS(*pte) == PTE_V)
//panic("uvmunmap: not mapped");
continue;至此,我们解决了虚拟内存的映射、页懒分配的问题,可以进行运行尝试,此时输入
mmaptest会出现panic: freewalk: leaf,因为我们映射的内存没有被释放,因此下一步我们把最后实现的exit部分提前到这里,确保进程退出时页面被成功释放;这里我在
kernel/sysfile.c封装了一个vma_unmap函数,因为后面sys_munmap系统调用也会使用这个函数,这个函数算是整个实验最为关键且比较有难度的函数了;vma_unmap会将虚拟内存va到va_end和物理内存映射关系取消掉,并且释放这些物理内存(效果就和uvmunmap一致);这里其实无需过多担心内存对齐问题,因为mmaptest的参数基本都是对齐的,当然基于通过测试的前提下思考这些问题是有益的,我这里也是按照理解来写,并假设了va是非对齐情况。首先
va1将va对齐到页头,并且va1逐页递增,直到包含va_end的页尾,解析出每个页帧的pte,解析到pa,就是每页页帧的起始物理地址;在取消映射前,我们需要判断该页帧的脏位PTE_Dirty以及内存是否共享即MAP_SHARED(这也是为什么我们开始mmap检查写权限时同时检查这两个位原因),如是则需要将文件写回磁盘,具体是通过writei函数将物理内存pa内容(这里也可以是用户虚拟空间va,即使用write(,1,va1,...),1对应src用户空间,va1对应页帧起始虚址)写回文件inode;这里分成三个条件;注意对于测试而言,仅第三个else是生效的,因为根本不会出现前两种不对齐的情况,但是这里为了逻辑完整性,也是没有删改,这里的写回实际上和我们刚刚描述的脏位问题有一点关联,详见
Q&A 4;假设
va是不对齐的,offset = va1 - va会计算每次va1和va相差的字节:1) 当第一次循环时,
va1对齐到页头,va在页帧中间,因此offset代表了va到页头的大小,此时pa对应的是页头起始地址(va1)的物理地址,页帧内偏移量为-offset;2)第二个意味着如果
va是最后一个页帧的中间,则需要计算剩下的字节数,同上;3)其他情况就是
va本身就是对齐的情况,直接逐页释放即可;
1 | int vma_unmap(pagetable_t pagetable,uint64 va,uint64 va_end,struct vma*vma){ |
然后在kernel/proc.c其中exit函数进程退出时调用,即可清除进程vma占用的所有物理内存,每个vma清除完毕需要将其文件引用数、使用标志位置为初始状态;
1 | for(int i = 0;i<VMA_MAXNUM; i++){ |
为了测试,我们把
kernel/proc.c的fork的步骤也一并完成,加入以下代码,原理是执行fork产生子进程时,将父进程vma复制到子进程中,同时将其对应文件引用数也++,这样子进程就持有和父进程一样的vma映射对象了,这部分可以结合测试文件一起看看,具体的Debug原理可以见Q&A 4;1
2
3
4
5
6
7for(int i=0; i<VMA_MAXNUM; i++){
struct vma *vma = &p->vma[i];
if(vma->vma_used){
np->vma[i]=*vma;
filedup(np->vma[i].vma_file);
}
}至此,尝试运行
mmaptest,如果功能正常的话,我们此时应该可以遇到:这是因为我们还没有实现1
mmaptest: mmap_test failed: file does not contain modifications, pid=5
sys_munmap的系统调用,为了跳过这个问题,我们在测试文件user/mmaptest.c将mmap_test函数以下两行代码注释掉;该两行会检查文件munmap时是否写回原文件;1
2//if (b != 'Z')
// err("file does not contain modifications");如果你的功能暂时是正常的,你会看到你通过了
mmaptest所有测试,否则你需要花费时间出现review你的代码;假设你已经实现既定目标,
sys_munmap的实现不会太复杂,因为纠结一个函数和纠结整个系统的函数复杂度不是一个量级的,也绝对不构成1+1+1=3的关系。sys_munmap接收参数虚拟地址va和大小length,取消这部分的文件映射;具体是调用了刚刚的vma_unmap释放对应的物理空间,并且调整vma_start和大小vma_length(部分取消映射仅允许在vma内存的头部或者尾部进行,头部需要额外更新vma_start),当vma_length归0意味着该vma可被回收;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38uint64 sys_munmap(void){ // int munmap(void *addr, uint64 length);
uint64 va,length;
if(argaddr(0,&va)<0||argaddr(1,&length)<0)
errlog("munmap parameter fault\n");
struct proc *p=myproc();
struct vma *vma = 0;
for(int i = 0; i<VMA_MAXNUM; i++){
struct vma*vmai = &p->vma[i];
if(vmai->vma_used&& va >= vmai->vma_start&& va < (vmai->vma_start+vmai->vma_length)){
vma = vmai; //查找va所在的vma
break;
}
}
if(!vma) //没找到,寄掉
errlog("munmap No VMA\n");
//从大于vma起始、小于vma尾部,属于挖洞取消映射,是不允许的(文件的映射变得复杂)
if(va>vma->vma_start&& va+length < vma->vma_start+vma->vma_length)
errlog("Hole unmap");
//释放这个va到va+length的物理内存,并写回
if(vma_unmap(p->pagetable, va, va+length, vma)!=0)
errlog("unmap fault\n");
//从头开始释放的,除了调整vma_length,还要调整vma_start
if(PGROUNDDOWN(va)==vma->vma_start){
vma->vma_start += length;
}
vma->vma_length -= length;
//没了,关闭文件引用,vma置0
if(vma->vma_length <= 0){
fileclose(vma->vma_file);
vma->vma_used = 0;
}
return 0;
}
把注释的测试代码加回来,验证结果: 1
2mmaptest
usertests
头文件声明等未描述问题细节请参考Commit:mmap
Done,其中user/mmaptest.c仅作debug的必要log,没有修改任何测试结果。
Q&A
记录一些可能遇到的问题以及关于forktest额外的讨论;
mmaptest出现panic: uvmunmap: not mapped
- 页懒分配修改
uvmunmap的PTE_V无效情况:使用continue忽略;
mmaptest出现1
2mismatch at 6144, wanted zero, got 0x5
mmaptest: mmap_test failed: v1 mismatch (2), pid=9
- 申请的物理内存没有
memset清空,存在垃圾内存,mmaptest要求初始内存必须为0;
usertest报错test kernmem: panic: Page Fault No Vma,这是我定义的一个错误,trap.c使用panic导致内核意外退出,具体代码为:1
2
3
4
5
6
7
8
9
10struct vma*vma=0;
for(int i = 0; i<VMA_MAXNUM; i++){
struct vma*vmai = &p->vma[i];
if(vmai->vma_used && va>=vmai->vma_start && va < vmai->vma_start+vmai->vma_length){
vma = vmai;
break;
}
}
if(vma==0)
panic("Page Fault No Vma");
trap.c没有使用封装函数就容易出现这种问题,实际上判断逻辑没有错误,不能使用panic("Page Fault No Vma");、return、p->killed =1(函数封装可以使用)、exit(0),这四种情况都会导致内核不能正常退出,我们参考因此这里必须将1
2if(p->killed =1)
exit(-1);panic改成exit(-1),使得一遇到错误马上返回状态-1,我定义的errlog使用return -1一开始就是为了避免xv6这种特性,没想到在trap.c还是栽掉了,防不胜防;
- mmaptest出现
mismatch at 2048, wanted 'A', got 0x0
- 这是本实验我遇到最大的问题了,也做了很多测试工作,水太深了。首先这是
forktest出现的问题,在我加入了sys_munmap后(在加入sys_munmap前是能够完全通过mmaptest的),使用脏位判断前,在2048个字符遇到了0,期望是A,说明没有通过父进程_v1函数字符检查;
以下内容都是这个问题的讨论,全部为个人总结观点,如有不当,酌情指出:
看代码是了解forktest流程最直观的方式,简化为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29char *p1 = mmap(0, PGSIZE*2, PROT_READ, MAP_SHARED, fd, 0);
char *p2 = mmap(0, PGSIZE*2, PROT_READ, MAP_SHARED, fd, 0);
//子进程
if (pid == 0) {
_v1(p1); //一个封装函数,检查p1内存的两个PGSIZE内是否1.5page为A,0.5page为0
printf("fork munmap begin");
munmap(p1, PGSIZE); // 取消一个PGSIZE映射
printf("forktest fork ok\n");
exit(0);
}
// 以下是父进程
int status = -1;
wait(&status);
if(status != 0){
printf("fork_test failed\n");
exit(1);
}
// check that the parent's mappings are still there.
printf("forktest parentp1 begin\n");
_v1(p1);
printf("forktest parentp1 ok\n");
_v1(p2);
printf("fork_test OK\n");
本文的关键解决方案是脏位,实际上影响的就是是否需要执行writei写回;如果设置了脏位判断,而这里的forktest权限没有进入writei的条件,因此writei无法进行,也即子进程不会影响物理内存,所以父进程的检查能够通过;反之子进程会写入磁盘,父进程重新读入就会出错;
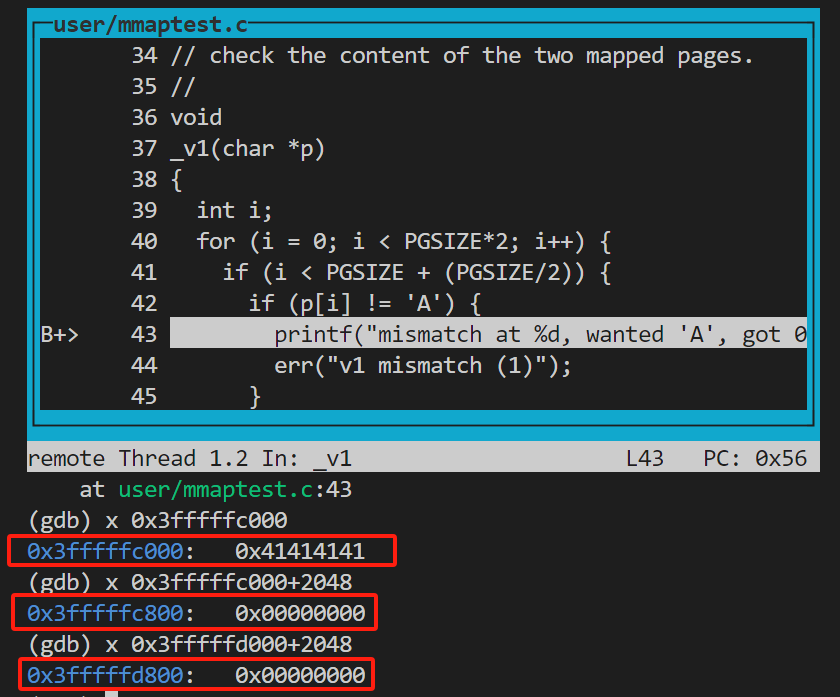
p1的c~e段应该分别存入1.5page的A和0.5page的0,cd被munmap掉1page的A后,父进程重新读入的是0.5page的A和0.5page的0,所以导致了这个报错;
然后,有意思的是,影响forktest的另一个重要问题是页懒分配,fork的特点是父子进程的虚拟空间是重叠的,但物理空间是相互独立的;你会发现脏位不是通过测试的必要条件,有若干种出乎意料的方式能够帮助程序正确运行,例如:
- 在父进程wait之前加入
printf("%d\t%d\n",p1[0],p2[0]);,这个读取操作是触发了trap.c的页懒分配,造成的效果是在子进程首先分配物理内存时,父进程不会阻塞地等待子进程结束再去获取自己的物理内存,导致内存字符出错,而是在子进程运行时父进程就已经拥有独立的物理内存,因此子进程的munmap不会影响父进程;
- 在父进程wait之前加入
- 相应的,注释子进程的
_v1(p1);也是一种可行方法;_v1函数读取了内存的值,同样会导致页懒分配的触发;注释掉子进程munmap时没有对应的物理内存,损失的只是一种映射关系,真正的物理内存会在执行父进程的_v1函数进行分配,因此内存检查是没有问题的。
- 相应的,注释子进程的
其中一个蛮重要的问题是我没有弄清楚的,就是脏位没有使用时子进程writei和父进程读入如何导致错位错误,我做了一些打印和调试的尝试,确定了writei的pa内存对应的是1个page的A写入文件偏移为0的位置,页懒分配的readi也是从文件偏移为0读出到cd,按照逻辑而言cd段应该得到1个page的A,但和事实不符,更奇怪的是如果将writei的偏移量定义为子进程munmap的大小,即4096字节,writei就能通过测试了。以下记录了三种情况log情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59fork_test starting
forktest mmap1 ok
forktest mmap2 ok #父进程分配虚拟内存
caller kalloccccccccccccc #de物理空间
fork
caller kalloccccccccccccc #子进程_v1函数触发的p1物理分配,对应ce虚拟内存
caller kalloccccccccccccc
fork munmap begin
0x0000003fffffc000 0x0000003fffffd000 #munmap触发,子进程释放cd空间
pa-780af000 #回盘inode,释放物理空间
0x0000003fffffd000 0x0000003fffffe000 #子进程退出,释放de
pa-780ae000
0x0000003fffffa000 0x0000003fffffc000 #子进程退出,释放ac,p2没有物理内存,无需释放
0x0000003fffffb000 0x0000003fffffc000
forktest parentp1 begin #父进程wait结束,进入父进程
caller kalloccccccccccccc #cd页懒触发,cd物理分配
/******************************1. 无脏位判断log******************************
mismatch at 2048, wanted 'A', got 0x0 #v1出错
mmaptest: fork_test failed: v1 mismatch (1), pid=5
0x0000003fffffc000 0x0000003fffffe000 #释放de
pa-7808d000
0x0000003fffffd000 0x0000003fffffe000 #释放cd
pa-780b6000
0x0000003fffffa000 0x0000003fffffc000 #释放p2,无对应物理内存
0x0000003fffffb000 0x0000003fffffc000
******************************1. 无脏位判断log******************************/
/**********************2. 脏位判断成功/无脏位偏移为4096log**********************
forktest parentp1 ok
caller kalloccccccccccccc #_v1触发p2分配内存a~c
caller kalloccccccccccccc
fork_test OK
mmaptest: all tests succeeded
0x0000003fffffc000 0x0000003fffffe000 #释放p1、p2及其对应内存
pa-780b5000
0x0000003fffffd000 0x0000003fffffe000
pa-780b6000
0x0000003fffffa000 0x0000003fffffc000
pa-7809b000
0x0000003fffffb000 0x0000003fffffc000
111111111111111111111111111111111pa-7808a000
**********************2. 脏位判断成功/无脏位偏移为4096log**********************/
更新:mmap的优化(Optional)
新代码引入快速排序解决了两个问题:
原代码只有全部vma回收才可能从头分配,现在允许重新利用分配过、但被回收的内存。
允许利用两个vma之间的碎片内存,提高内存紧凑度和利用率。
排序对性能影响不大。
基本思路: 排序算法,是什么排序无所谓,这里我写了一个快速排序,将vma根据地址高低进行排序,确保每个vma[i]都是相邻的内存。
从高到低遍历内存,如果出现被回收的空间大于需要空间,或者两个内存夹缝碎片大于需要空间,就将该碎片分配出去;下一次分配会使用快速排序重新排布vma。此外我引入了新的测试函数以验证快速排序、内存分配的正确性
细节问题:vma_used应该在找到空间后再置1,因为现在有多种分配策略,提前置位会导致略过回收空间的检查。如果映射空间有问题(例如分配夹缝碎片时,没有减去下方内存本身的固有长度),可能会导致forktest失败。
最终代码如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116//Quick Sort for vma start_addr
int getpivot(struct vma vma[], int low, int high){ //递归快速排序
struct vma pivot = vma[low];
while(low<high){
while(low<high&&vma[high].vma_start<=pivot.vma_start)
high--;
vma[low] = vma[high];
while(low<high&&vma[low].vma_start>=pivot.vma_start)
low++;
vma[high] = vma[low];
}
vma[low] = pivot;
return low;
}
void QuickSort(struct vma vma[], int low, int high){ //递归快速排序
if(low<high){
int pivot = getpivot(vma,low,high);
QuickSort(vma,low,pivot-1);
QuickSort(vma,pivot+1,high);
}
}
struct vma* get_gapstaddr(struct vma vma[],uint64 length){ //分配起始地址函数
QuickSort(vma,0,VMA_MAXNUM-1); //按起始地址大到小排序
uint64 end = TRAPFRAME;
uint64 endtemp = TRAPFRAME;
int found = 0;
struct vma *free_vm;
for(int i=0; i<VMA_MAXNUM; i++){
if(vma[i].vma_used==1){
endtemp = PGROUNDDOWN(vma[i].vma_start); //记录最低内存
}
else if(!found&&vma[i].vma_used==0){ //找到未分配的vma
found = 1;
free_vm = &vma[i];
}
}
if(!found)
return 0;
end = endtemp < end ? endtemp : end;
//printf("endtemp=%x end=%x\n",endtemp,end);
int gap_flag = 0; //是否存在空隙、或者已分配但回收的内存
if(vma[0].vma_used==0&&TRAPFRAME-(vma[1].vma_start+vma[1].vma_length)>=length){ //vma[0]回收了
free_vm->vma_start = TRAPFRAME-length; //如果空间允许应该分配
free_vm->vma_used = 1;
return free_vm;
}
for (int i = 1; i < VMA_MAXNUM; i++) {
if (vma[i].vma_used==0) { //vma1到15回收了,应该重新分配
uint64 gap = vma[i-1].vma_start - vma[i].vma_start;
if (gap >= length) {
free_vm->vma_start = PGROUNDDOWN(vma[i-1].vma_start) - length;
free_vm->vma_used = 1;
gap_flag = 1;
break;
}
}
if(vma[i].vma_used==1&&vma[i-1].vma_used==1){ //两个vma之间,存在碎片化空间
uint64 gap = vma[i-1].vma_start - (vma[i].vma_start + vma[i].vma_length);
if(gap>=length){ //空间允许,应该分配
free_vm->vma_start = PGROUNDDOWN(vma[i-1].vma_start) - length;
free_vm->vma_used = 1;
gap_flag = 1;
break;
}
}
}
if(gap_flag==0){ //没有足够大小的碎片空间或者已分配但回收空间
free_vm ->vma_start = end - length; //只能按记录最低内存分配
free_vm->vma_used = 1;
}
return free_vm;
}
//for mmap: void *mmap(void *addr, uint64 length, int prot,int flags,int fd, uint64 offset);
uint64 sys_mmap(void){
uint64 va,length,offset;
int prot,flags,fd;
struct file* file;
if(argaddr(0,&va)<0||argaddr(1,&length)<0||argint(2,&prot)<0 \
||argint(3,&flags)<0||argfd(4,&fd,&file)<0||argaddr(5,&offset)<0)
errlog("parameter fault\n");
//va and offset should be 0
if(va!=0||offset!=0)
errlog("va/offset non-zero\n");
struct proc *p = myproc(); //current process
if(file->ref<1||(!file->readable&&(prot&PROT_READ))|| \
(!file->writable&&((prot&PROT_WRITE)&&(flags&MAP_SHARED))))
errlog("mmap file flags wrong\n");
length = PGROUNDUP(length); //mmap length aligned
struct vma* free_vm = get_gapstaddr(p->vma,length); //已分配好起始地址的空闲vma
if(free_vm==0) //没有空闲vma
return -1;
free_vm->vma_length = length;
free_vm->vma_prot = prot;
free_vm->vma_flags = flags;
free_vm->vma_file = file;
filedup(free_vm->vma_file);
//For MY Sort Test
for(int i=0; i<5; i++){
printf("vma%d: start:%x , size:%x, flag:%d\n",i,p->vma[i].vma_start,p->vma[i].vma_length,p->vma[i].vma_used);
}
return free_vm->vma_start;
}
原来的代码评估一样能够通过,再加入一个简单测试程序:映射了四个文件,大小为2000、2000、1000、1000,在映射文件3、4前取消文件1映射,文件1空间被分配给3、4,其中分配给3属于重利用空间,分配给4属于碎片化利用空间,均成功验证,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41//just for my sort test,No necessary
void mmap_mysorttest(void){
int fd1,fd2,fd3,fd4;
printf("MY Sort test====================\n");
const char * const f1 = "sort1.dur";
makefile(f1);
if ((fd1 = open(f1, O_RDONLY)) == -1)
err("open");
char *p1 = mmap(0, PGSIZE*2, PROT_READ, MAP_PRIVATE, fd1, 0);
printf("p1 map\n");
const char * const f2 = "sort2.dur";
makefile(f2);
if ((fd2 = open(f2, O_RDONLY)) == -1)
err("open");
mmap(0, PGSIZE*2, PROT_READ, MAP_PRIVATE, fd2, 0);
munmap(p1,PGSIZE*2);
printf("p1 unmap\n");
if(close(fd1)<0)
err("my sort close err");
const char * const f3 = "sort3.dur";
makefile(f3);
if ((fd3 = open(f3, O_RDONLY)) == -1)
err("open");
mmap(0, PGSIZE, PROT_READ, MAP_PRIVATE, fd3, 0);
printf("p3 map\n");
const char * const f4 = "sort4.dur";
makefile(f4);
if ((fd4 = open(f4, O_RDONLY)) == -1)
err("open");
mmap(0, PGSIZE, PROT_READ, MAP_PRIVATE, fd4, 0);
if(close(fd2)<0||close(fd3)<0||close(fd4)<0)
err("my sort close err");
exit(0); //取消所有映射和页表
}
TRAPFRAME的起始地址为-2000,其中-2000——-3000分配给文件3,-3000——-4000分配给文件4,达到预期效果。
优化commit:Add QuickSort for mmap
