
操作系统MIT 6.S081 xv6内核:基础理论
从常规操作系统原理和xv6系统原理两个方面入手,记录了一些重要的操作系统理论,有助于帮助加深lab的理解。
中断和异常
xv6的中断系统并不多,只有缺页中断、系统调用中断、设备中断以及其他故障中断,这里中断一节是针对操作系统的概述,而其余内容基本仅面对xv6及其源码。
中断的作用
CPU上的运行程序分为两种,一种是操作系统内核程序,另一种是应用程序,在合适情况下,操作系统会把CPU使用权交给应用程序,此时从内核态切换到用户态,通过执行一条特权指令:修改PSW标志位为用户态,意味着内核主动让出CPU使用权;而如果需要从用户态切换回内核态,唯一途径是通过中断实现,内核会重新夺回CPU使用权。
内中断和外中断
内中断(异常中断)
内中断:与当前执行的指令有关,中断信号来自CPU内部;
典型的内中断:
1.
用户态植入非法特权指令:特权指令是一种只允许内核态访问的指令(访问对应特权寄存器),如果在应用程序中出现特权指令,会触发中断,内核会重新获取CPU使用权,内核程序会继续处理这个中断。
- 非法参数:用户程序除数为0,触发中断,程序不会继续执行,内核重新获取控制权处理中断;
还有一种特别的情况是用户程序需要内核辅助完成某些任务,此时就需要使用陷入指令(trap);陷入指令并不是一种特权指令,CPU在用户态遇到陷入指令,意味着用户将控制权交给内核,内核去执行某些系统操作;
外中断(中断)
外中断:与当前执行的指令无关,中断信号来自CPU外部。
典型外部中断:
时钟中断实现进程并发:CPU中有时钟部件,每隔一段时间向CPU发生中断信号,CPU此时会从一个程序切换到内核态处理这个中断,切换到另一个程序执行,直到相同的间隔时间后CPU再次收到时钟中断,这样CPU就能够不断地切换任务执行,实现了“并发”。
I/O中断:输入输出设备任务完成时,向CPU发送中断,CPU切换到内核态进行处理。
系统调用
系统调用是操作系统提供给应用程序的接口,可以看成是一种特殊的函数,应用程序通过系统调用请求系统内核服务。系统调用和普通函数调用的区别在于:普通函数调用的某些库函数(不是全部),实际也涉及到了系统的调用,高级程序语言会把某些系统调用封装成库函数给应用程序使用,隐藏了部分系统实现细节,系统调用是操作系统向高级程序语言、应用程序提供的接口,因此更加接近底层。
为什么系统调用是必须的
方便操作系统同一管理资源,能够并发、有序地执行任务,而不是谁都可以访问。
系统调用的分类
设备管理(设备请求、启动、释放)、文件管理(读写增删等)、进程控制(进程创建阻塞销毁等)、进程通信(信息、信号传递)、内存管理(内存分配、回收);
共性:这些内容有可能是多个进程共享的,因此需要由系统调用分配。
应用程序实现系统调用的过程
应用程序会将需要的系统调用作为参数传递给寄存器,于是CPU执行到应用程序的陷入指令后,会进入内核态,内核会根据这些寄存器参数调用相应的系统服务,并且接收应用程序其他的参数,完成操作后会切换回用户态继续执行应用程序。
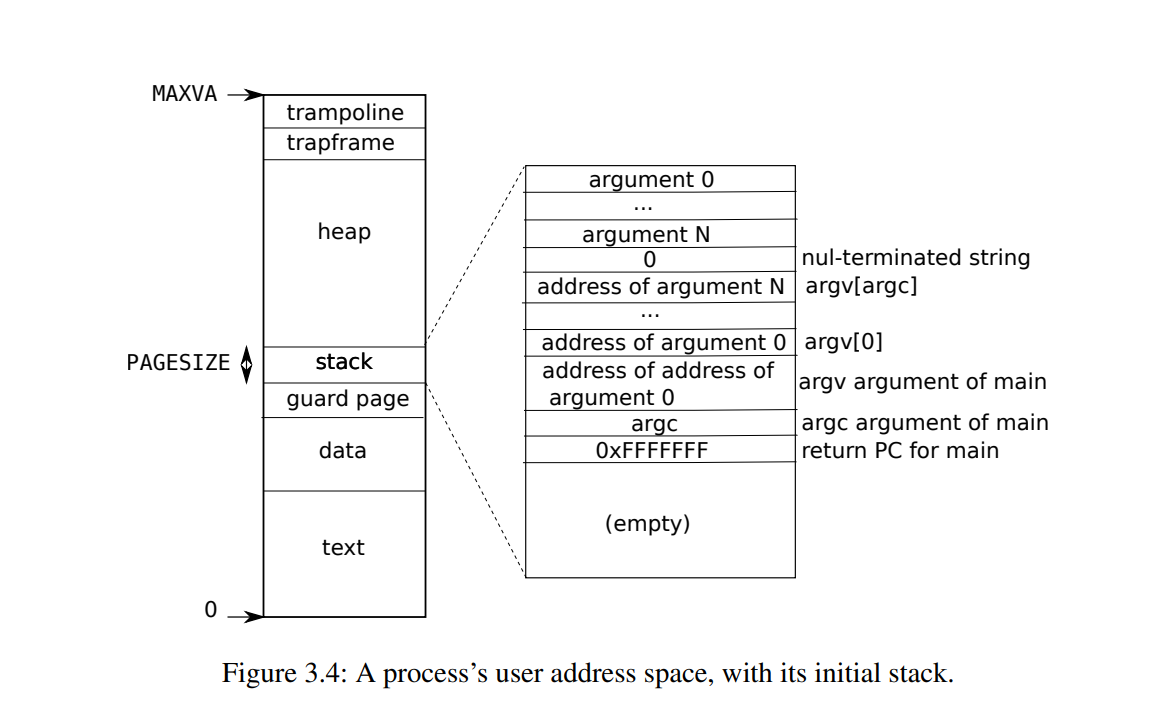
页表
阅读以下内容,我们假设你对页表、多级页表、虚拟内存等有基本的认识乃至一定程度的掌握,如果不是你可以参考操作系统内存管理这篇文章。
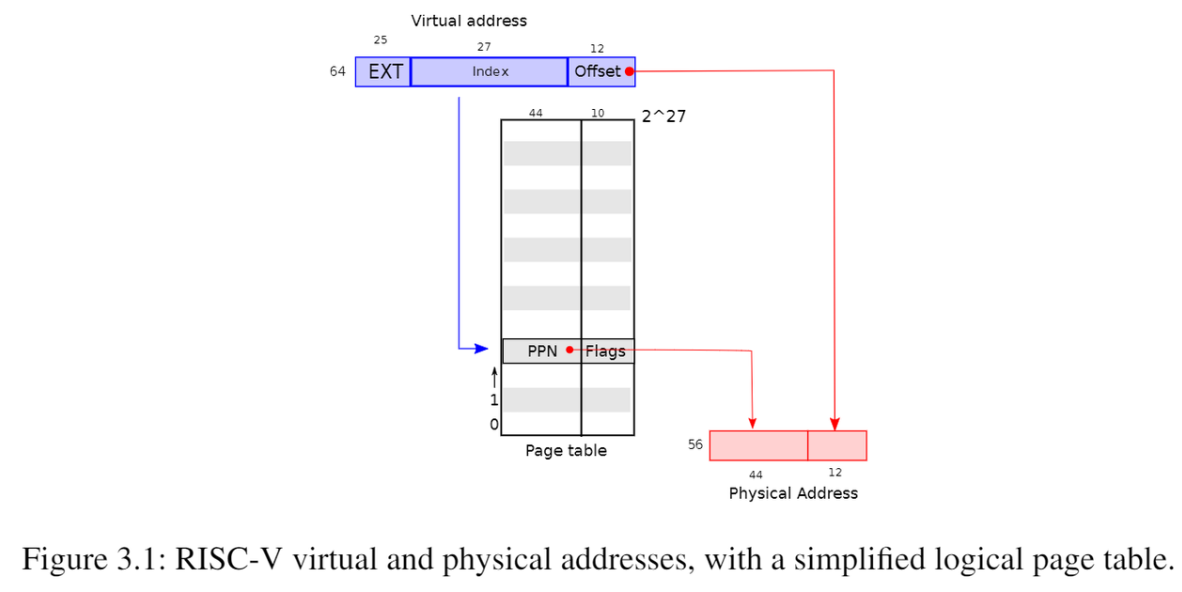
xv6逻辑地址、物理地址
页表做的工作是实现进程页面的离散存储,虚拟内存基于这样的机制实现从逻辑地址到物理地址的转换。XV6基于Sv39 RISC-V运行,意味着它只使用64位虚拟地址的低39位,另外25位是预留的。这39位是如此分配的,首先页帧大小为4KB,因此页偏移量为最后12位;页帧为4KB,每个页表项占据8个Bytes(因为除了内存块号4B,仍需要额外4B标识该页表项是否存入内存等额外标志字段),因此每个页帧最多表示有512页表项,占据逻辑地址9位;
同理在三级页表中,每级页表都是9位逻辑地址;除开页偏移量,其中27个逻辑地址都是为了将页表离散存储,因此页表项最多可以有
重申一下PPN索引机制,开局一个虚拟地址,当前进程的顶级页表基址存储在cpu的satp寄存器;现在任务是通过虚拟地址获得它对应的物理地址,要经过以下过程:将39位虚拟地址分成9+9+9+12,记为p1、p2、p3、页偏移量,从satp获取顶级页表基址addr1,以及从39位虚拟地址的高9位页号,读取虚拟地址addr1+p1*8(单个页表项大小),读取该页表项的PPN,就得到二级页表基址addr2,读取虚拟地址中间9位得到在一级页表项的偏移量,计算得到一级页表地址,如此类推,我们将得到对应物理页帧的虚拟基址,加上页偏移量,就是虚拟地址对应的物理地址。
再看一下物理地址,物理地址由56位组成,前44位来自页表项中的PPN,后12位为页偏移量。我们已经提过页内是顺序存储的,因此物理地址的页偏移量和逻辑地址的页偏移量是一致的。
地址转换
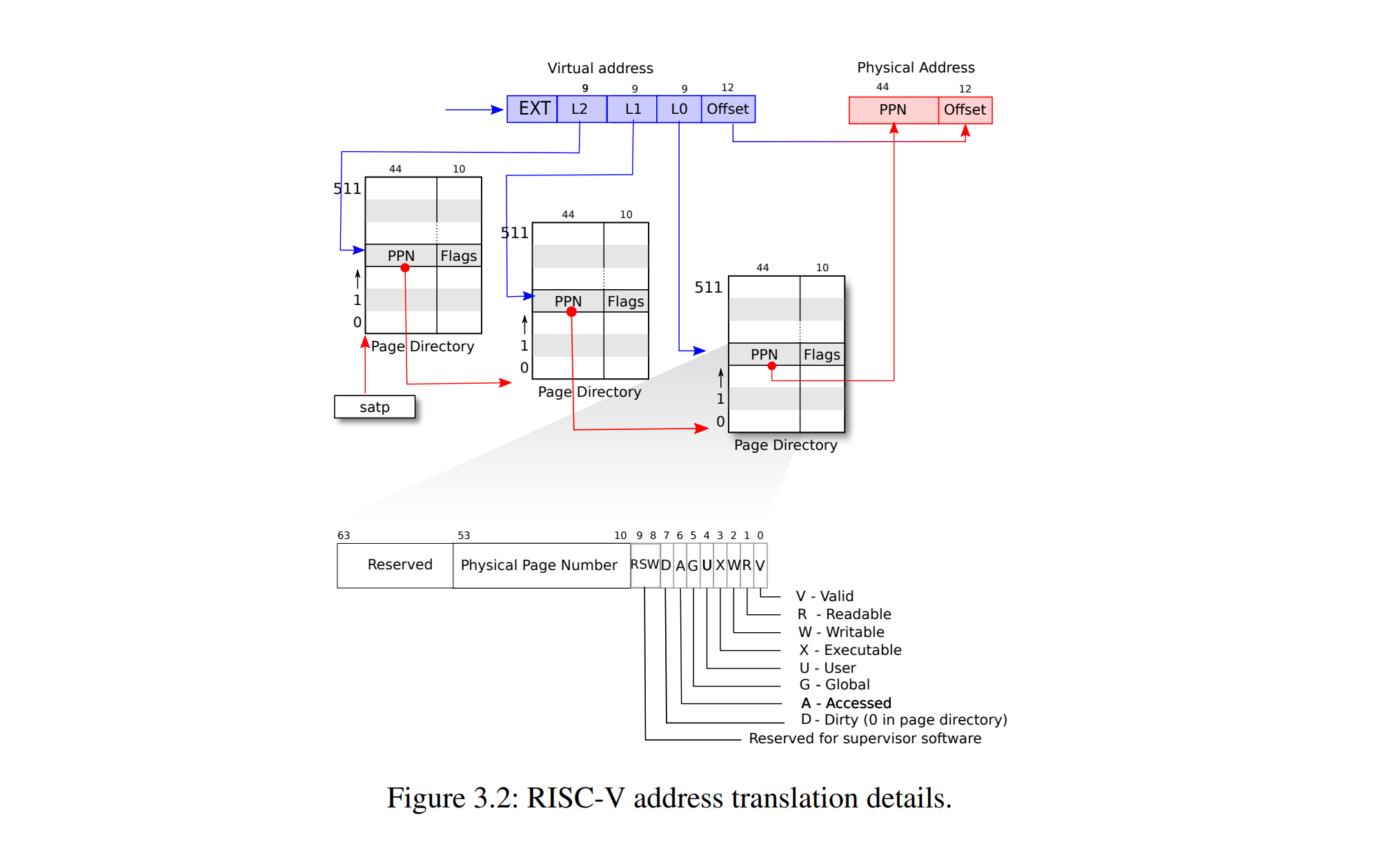 虚拟地址通过三级页表来得到实际物理地址,其中satp寄存器是存储顶级页表(根页表)地址的寄存器。初始时虚拟地址从satp得到根页表内存块地址,找到对应的PPN进一步计算得到下级页表地址......如此重复直到得到物理地址。如果没有找到下级页表,会引发页面故障异常(page-fault
exception),并且让内核处理该异常。
虚拟地址通过三级页表来得到实际物理地址,其中satp寄存器是存储顶级页表(根页表)地址的寄存器。初始时虚拟地址从satp得到根页表内存块地址,找到对应的PPN进一步计算得到下级页表地址......如此重复直到得到物理地址。如果没有找到下级页表,会引发页面故障异常(page-fault
exception),并且让内核处理该异常。
图的下方进一步展示了PTE的细节,每个PTE由8个字节(64位)组成,其中10位为预留位,44位作为PPN,最后10位为标记位(其中高2位为预留标记位)。每个PTE包含标志位,这些标志位告诉分页硬件允许如何使用关联的虚拟地址。PTE_V指示PTE是否有效:如果它没有被设置,对页面的引用会导致异常(即不允许)。PTE_R控制是否允许指令读取到页面。PTE_W控制是否允许指令写入到页面。PTE_X控制CPU是否可以将页面内容解释为指令并执行它们。PTE_U控制用户模式下的指令是否被允许访问页面;如果没有设置PTE_U,PTE只能在监管者模式下使用。其余标志位并不是那么重要。标志和所有其他与页面硬件相关的结构在kernel/riscv.h中定义
内核地址空间
kernel/memlayout.h声明了xv6内核内存布局的常量。 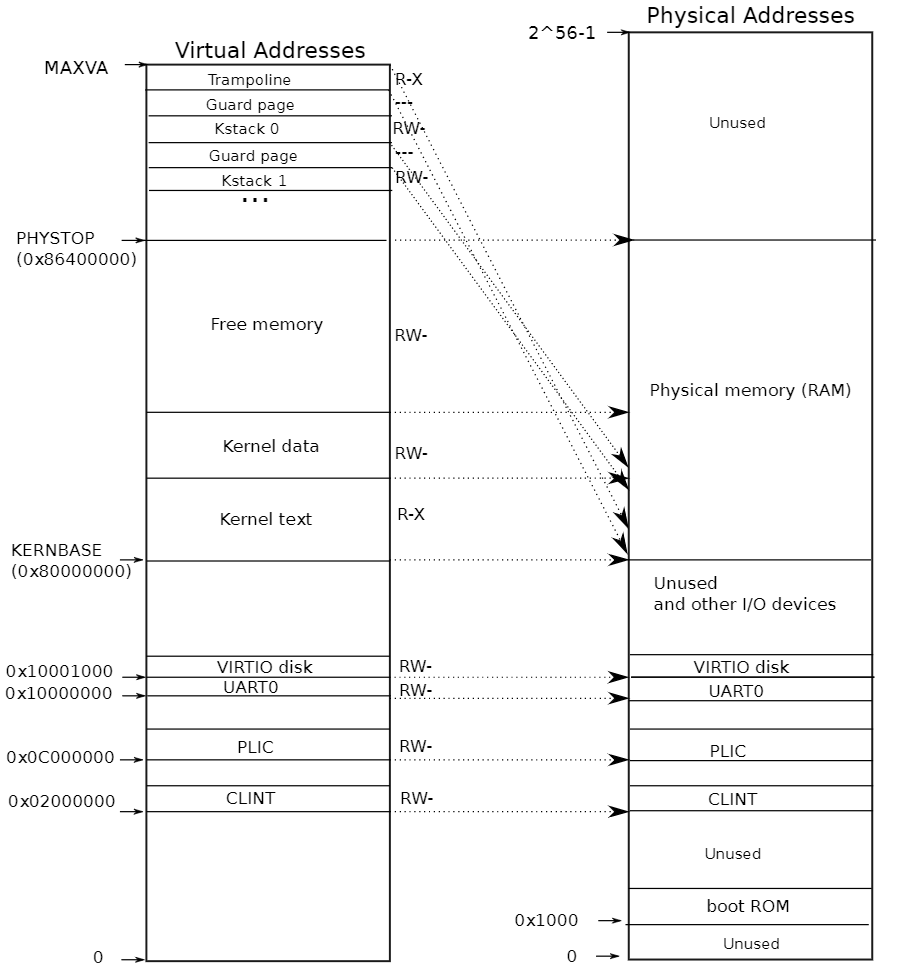 qemu模拟了一台计算机,从我们刚刚的讨论,虚拟内存占据
qemu模拟了一台计算机,从我们刚刚的讨论,虚拟内存占据
从物理地址一侧可以看到,主板上电时,会从0x1000进入运行存储在boot
ROM的代码,boot完成会跳转至0x80000000,这是内存的起始位置;在起始位置之前的地址空间,存储了IO设备的接口,xv6将它们暴露给软件,一些IO设备为:PLIC(Platform-Level
Interrupt
Controller)为中断控制器,负责全局中断控制(如外部中断),CLINT(Core
Local
Interruptor)也是中断的一部分,负责本地中断(如软件中断、定时器中断),UART0(Universal
Asynchronous
Receiver/Transmitter)负责与Console和显示器交互,VIRTIO
disk,与磁盘进行交互;从硬件上看,设备接口实际上是和设备进行交互,注意所谓的内存(0x80000000至PHYSTOP的部分)的硬件实现是DRAM芯片,它们存在是为了CPU与外存数据的高速交互;而0x80000000以下的部分是设备接口,硬件上和内存芯片没什么关系,因此和其交互实际上是和设备交互。
再者,虚拟内存和物理内存几乎是直接平行映射的关系,0x80000000至0x86400000的部分(算的是100MB,但是宏定义是128MB)作为内存,其中kernel text权限为读和执行命令,可以在这里运行代码,但不能写入篡改;kernel data能够存放数据,不能执行命令;
而有两个地方是没有被直接映射的,为:
跳板页trampoline page:映射在虚拟地址空间的顶部;用户页表具有相同的映射。后面再讨论了跳板页面的作用,但我们在这里看到了一个有趣的页表用例;一个物理页面(持有跳板代码)在内核的虚拟地址空间中映射了两次:一次在虚拟地址空间的顶部,一次直接映射,这个特性是跳板页工作的重要依赖,后面在Traps我会介绍。
内核栈页面。每个进程都有自己的内核栈,它将映射到偏高一些的地址,这样xv6在它之下就可以留下一个未映射的保护页(guard page)。保护页的PTE是无效的(也就是说PTE_V没有设置),所以如果内核溢出内核栈就会引发一个异常,内核触发panic。如果没有保护页,栈溢出将会覆盖其他内核内存,引发错误操作。恐慌崩溃(panic crash)是更可取的方案。(注:Guard page不会浪费物理内存,它只是占据了虚拟地址空间的一段靠后的地址,但并不映射到物理地址空间。)也就是说,kernel data和kernel stack都会被映射到物理内存中,而实际使用的虚拟内存是stack部分,因为stack部分存在guard page,提高了安全性。
物理内存kalloc.c相关函数剖析
在system calls那一节我们做过相关的内存实验,但是因为没有涉及页表没有详细对代码进行剖析,在这里进行补充。
变量声明
结点的结构是run定义的,结点里只有指针域,kmem作为结构体,freelist是结构体指针,作为头指针指向空闲的页帧链表,lock是获取锁的结构;如果对这种数据结构不熟悉,可以取看一下数据结构一
链式队列的底层实现部分,也是用到了结构体指针+链表的结构。
end数组是内核空间后的第一个地址,kernel.ld是一个链接器脚本,大概描述了内存的空间分布:在内存结构图,kernel text(代码段)和kernel data(数据段),后面起始还包含了kernel BSS(Block
Started by
Symbol),存储了未初始化的(或初始化为0的)全局变量、静态变量(已初始化的存储在数据段),这三部分是内核的核心数据,end是这三部分后面的第一个地址空间。
1
2
3
4
5
6
7
8
9
10
11struct run {
struct run *next; //结点只有指针域
};
struct {
struct spinlock lock;
struct run *freelist; //头指针,指向空闲链表的第一个结点
} kmem;
extern char end[]; // first address after kernel.
// defined by kernel.ld.
kalloc
从空闲页链表freelist取出一个页帧结点,这个空闲页帧会使用数字5进行数据填充(代表页帧被占用但是没有被正式使用)并且返回void*空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock); //获取锁
r = kmem.freelist; //通过头指针获取r
if(r)
kmem.freelist = r->next; //头指针后移
release(&kmem.lock); //释放锁
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
kfree
kfree的作用是将某段物理内存页面(end~PHYSTOP部分)回收,交给内核以分配给其他进程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22 // Free the page of physical memory pointed at by v,
// which normally should have been returned by a
// call to kalloc(). (The exception is when
// initializing the allocator; see kinit.)
void
kfree(void *pa)
{
struct run *r;
//未对齐、内存越界(end以下存储内核核心数据,不能被kfree操作。
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist; //加入页链表
kmem.freelist = r; //头指针前移
release(&kmem.lock);
}
freerange
用到了一个宏: 1
2
而PGROUNDDOWN是用于下对齐的,直接屏蔽了偏移量,一般是用于获取某个地址的起始地址,后面的vm代码会使用到。
freerange的作用就是将pa_start到pa_end的物理内存页面全部归还内核空闲列表,这里需要考虑对齐问题,为了防止pa_start不是严格的页帧起始地址,因此开始时需要PGROUNDUP将其对齐到下一页,如果使用PGROUNDDOWN,就有可能使pa_start之前到页帧起点的数据也被意外删除,这种结果有可能是破坏性的。
1
2
3
4
5
6
7
8void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
kinit
有了前面三个函数的逐级铺垫,这段代码的作用是将end~PHYSTOP的物理内存页面进行初始化,且建立可用的分页空闲链表freelist。
1
2
3
4
5
6void
kinit()
{
initlock(&kmem.lock, "kmem");
freerange(end, (void*)PHYSTOP);
}
虚拟内存vm.c相关代码剖析
变量声明
pagetable_t是指向根页表的一个指针,既可以是进程页表,也可以是内核页表;
1
2
3
4
5pagetable_t kernel_pagetable;
extern char etext[]; // kernel.ld sets this to end of kernel code.即内存的kernel text的末尾位置
extern char trampoline[]; // trampoline.S 跳板页,未涉及
内核函数
kvminit
主要是内核页表的初始化和映射,映射对象包括设备接口、kernel
text(只读代码)、data(存放数据)和跳板页部分。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33void
kvminit()
{
//新建一个内核页表
kernel_pagetable = (pagetable_t) kalloc();
memset(kernel_pagetable, 0, PGSIZE);
//设备接口注册
// uart registers
kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
kvmmap(CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(PLIC, PLIC, 0x400000, PTE_R | PTE_W);
//etext指向的是kernel text末尾,KERNBASE是内存起始地址即0x80000000
// map kernel text executable and read-only.
kvmmap(KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
//内存存放数据的地址
// map kernel data and the physical RAM we'll make use of.
kvmmap((uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
//跳板映射
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}
kvminithart
hart意为核心、硬件线程。更换页表或者初始化时,都需要设置CPU的satp寄存器使其记录页表基址,另外涉及一个结构TLB(Translation
Lookaside Buffer),也即快表,能够无需访存实现PPN的查询。
1
2
3
4
5
6void
kvminithart()
{
w_satp(MAKE_SATP(kernel_pagetable));
sfence_vma(); //刷新TLB,更换页表快表也必须更新;
}
walk函数
walk函数是一个重要函数,我们先介绍一些宏,以理解walk函数中用到的方法。
1
2
3
4
5
6
7
8
)
walk函数是模拟MMU(Memory Management Unit,内存管理单元)的行为,根据页表查询下一级页表或者目标内存单元,注意这些一系列行为都是MMU的任务,MMU是硬件实现的,并不是操作系统的一部分,操作系统只需要对其进行软件配置;既然硬件接口能完成地址转换,为什么操作系统还需要walk函数,而不是一个简单的命令接口,Frans教授给出了两点原因:
walk函数需要模拟MMU的地址转换能力,以及多级页表的编程能力,使操作系统启动时也能够对页表项等进行初始化配置;
用户空间和内核空间都有各自的页表,内核需要读取用户空间页表中的虚拟地址,将其转换成操作系统能承认的物理地址,访问相应的地址空间,这些操作离不开软件walk实现。
1 | pte_t * |
注意walk的转换没有考虑页偏移量,因此walk和walkaddr返回的物理地址只是页帧的起始地址,而不是具体到页帧偏移量的起始地址。
walkaddr
walk函数通过虚拟地址va,查询页表pagetable,得到最低级页表项地址,walkaddr就负责将这个页表项转换成物理地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// Look up a virtual address, return the physical address,
// or 0 if not mapped.
// Can only be used to look up user pages.
uint64
walkaddr(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
uint64 pa;
if(va >= MAXVA)
return 0;
pte = walk(pagetable, va, 0);
if(pte == 0)
return 0;
if((*pte & PTE_V) == 0)
return 0;
if((*pte & PTE_U) == 0)
return 0;
pa = PTE2PA(*pte);
return pa;
}
mappages函数
宏为PGROUNDDOWN: 1
mappages函数的作用:给出虚拟地址va,需要操作内存大小size,物理地址pa,mappages会循环为这块内存分配4KB的页帧,并且将物理地址、权限转换成页表项设置(将虚拟地址映射到物理地址)。成功返回0,失败-1;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Create PTEs for virtual addresses starting at va that refer to
// physical addresses starting at pa. va and size might not
// be page-aligned. Returns 0 on success, -1 if walk() couldn't
// allocate a needed page-table page.
//参数:页表pagetable,虚拟地址va,操作内存大小size,物理地址pa,perm除PTE_V的其他自定义权限
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last;
pte_t *pte;
a = PGROUNDDOWN(va); //va的页号
last = PGROUNDDOWN(va + size - 1); //偏移量为size-1字节的内存空间(空间大小就是size)
for(;;){
if((pte = walk(pagetable, a, 1)) == 0) //walk返回0代表新页帧分配失败(如空闲页帧不足)
return -1; //返回-1失败
if(*pte & PTE_V) //walk返回pte存在切PTE_V被设置有效,说明这个空间一早被映射了
panic("remap"); //panic重复映射
*pte = PA2PTE(pa) | perm | PTE_V; //设置walk新分配的页表项,物理地址、权限perm、标志位V
if(a == last) //到了操作内存末尾,映射完毕,跳出
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
kvmmap、kvmpa
kvmmap使用mappages初始化了内核页表kernel_pagetable,将逻辑地址va——va+sz-1映射到物理地址pa——pa+sz-1,注意这个映射不会刷新TLB,也不会在CPU启用分页机制、地址转换等。
1
2
3
4
5
6
7
8
9// add a mapping to the kernel page table.
// only used when booting.
// does not flush TLB or enable paging.
void
kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
{
if(mappages(kernel_pagetable, va, sz, pa, perm) != 0)
panic("kvmmap");
} 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// translate a kernel virtual address to
// a physical address. only needed for
// addresses on the stack.
// assumes va is page aligned.
uint64
kvmpa(uint64 va)
{
uint64 off = va % PGSIZE; //计算偏移量,物理地址偏移量和逻辑地址是一致的
pte_t *pte;
uint64 pa;
pte = walk(kernel_pagetable, va, 0); //根据内核页表将va转换成最后一级页表项
if(pte == 0) //返回0代表页表项不存在或者标志位无效
panic("kvmpa");
if((*pte & PTE_V) == 0) //页表项无效
panic("kvmpa");
pa = PTE2PA(*pte); //页表项转换成物理地址
return pa+off; //物理地址
}
用户空间页表操作
上述介绍了vm.c中有关内核(k开头命名)的相关函数,接下来介绍的为用户空间页表(u开头的命名)的相关操作。
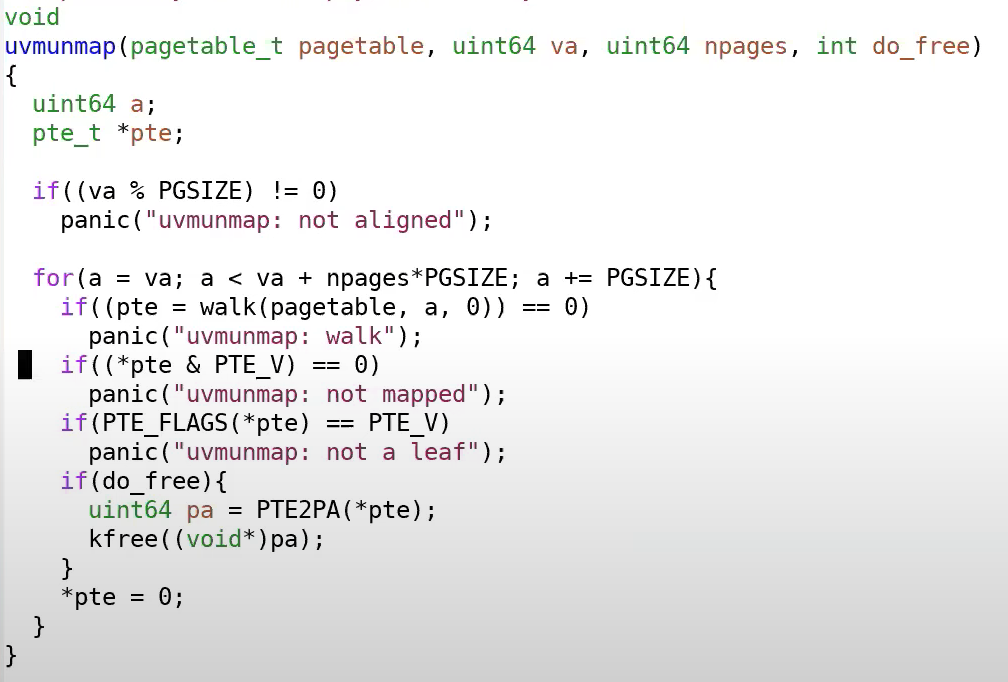
uvmunmap取消映射
uvmunmap用于取消va虚拟地址后面npages个页面的物理映射;do_free选择是否回收这段物理内存,如果回收物理内存会被空白数据填充并添加到空闲页帧链表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// Remove npages of mappings starting from va. va must be
// page-aligned(页面对齐). The mappings must exist.
// Optionally free the physical memory.
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0) //虚拟地址必须和页帧对齐
panic("uvmunmap: not aligned");
//从va开始,释放npages个页帧
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0) //页表项不存在或者标志无效
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0) //页表项标志位或者页表项为全0,映射关系不存在
panic("uvmunmap: not mapped");
if(PTE_FLAGS(*pte) == PTE_V) //这个PTE_FLAGS是取低10位,也即判断其是否只有V标志位为1
panic("uvmunmap: not a leaf"); //只有V为1代表这个不是叶子结点(叶子节点会同时设置读写执行等权限)
if(do_free){
uint64 pa = PTE2PA(*pte); //释放物理内存,加入空闲页帧链表给其他进程使用
kfree((void*)pa);
}
*pte = 0; //页表项PPN、标志位全部置0
}
}
这个看到后面的确有补充函数,在确保叶子结点删除完毕的情况下,进一步删除上层函数见freewalk部分。
uvmcreate
新建一个页面,kalloc从空闲页帧链表取出一个分配给用户存储页表,比较简单。
1
2
3
4
5
6
7
8
9
10
11
12// create an empty user page table.
// returns 0 if out of memory.
pagetable_t
uvmcreate()
{
pagetable_t pagetable;
pagetable = (pagetable_t) kalloc();
if(pagetable == 0)
return 0;
memset(pagetable, 0, PGSIZE);
return pagetable;
}
uvminit
从空闲页帧链表取出一块分配给用户存储代码和数据,用户的代码和数据的指针由src指向,通过memmove(mem,
src,
sz)将src指向的用户初始化程序数据加载到内存页帧mem中,注意大小sz不能超过一个页帧大小。
uvminit 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// Load the user initcode into address 0 of pagetable,
// for the very first process.
// sz must be less than a page.
void
uvminit(pagetable_t pagetable, uchar *src, uint sz)
{
char *mem;
if(sz >= PGSIZE)
panic("inituvm: more than a page");
mem = kalloc(); //页帧链表取出一块空闲页帧空间
memset(mem, 0, PGSIZE);
mappages(pagetable, 0, PGSIZE, (uint64)mem, PTE_W|PTE_R|PTE_X|PTE_U);
memmove(mem, src, sz);
}
uvmdealloc
uvmdealloc由于缩小内存的空间,旧大小为oldsz,新大小为newsz,假如新大小小于旧大小,会调用uvmunmap对若干个物理内存页面进行取消映射,回收物理内存。参数的大小无需考虑内存对齐,也无需保证新大小必须小于旧大小,这些在程序中都会被解决;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Deallocate user pages to bring the process size from oldsz to
// newsz. oldsz and newsz need not be page-aligned, nor does newsz
// need to be less than oldsz. oldsz can be larger than the actual
// process size. Returns the new process size.
uint64
uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
if(newsz >= oldsz) //指定新大小大于等于旧大小,无需释放,返回原来大小。
return oldsz;
//上对齐,按页为空间释放内存,即如果newsz为5000,那么会上对齐至2页即4096*2大小;
if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){
int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE; //计算要释放多少页
uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1); //按页释放物理内存并回收
}
return newsz; //返回新大小
}
uvmalloc
uvmalloc的作用是将进程大小从oldsz扩展至newsz,这里的oldsz、newsz除了描述大小,还带一些隐含的习惯:例如oldsz还一般指的是开始新内存分配的地方,而不只是描述大小关系(否则mappages将a(oldsz+n倍PGSIZE)映射到物理内存mem就会显得很puzzle),所以准确而言,它们是一种相对于起始地址偏移量的概念,既可以描述大小,也描述了相对位置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Allocate PTEs and physical memory to grow process from oldsz to
// newsz, which need not be page aligned. Returns new size or 0 on error.
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
oldsz = PGROUNDUP(oldsz); //上对齐,对齐到下页页帧
for(a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc(); //取空闲页帧
if(mem == 0){ //为0,说明分配失败
uvmdealloc(pagetable, a, oldsz); //失败有可能发生在分配中途,需要撤销a空间大小,变成原来大小oldsz
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){ //将新内存的虚拟地址映射到物理内存,成功返回0
kfree(mem); //映射失败释放申请的物理内存
uvmdealloc(pagetable, a, oldsz); //撤回分配的内存空间。
return 0;
}
}
return newsz; //成功返回新的进程大小
}
freewalk函数
freewalk函数解决了我们在uvmunmap函数中遗留的问题。uvmunmap删除了所有叶子结点,freewalk能够将非叶子结点回收,页表项置0,并且归还内核物理内存页面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// Recursively free page-table pages.
// All leaf mappings must already have been removed.
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
//满足pte & PTE_V=1说明页表项有效,满足pte & (PTE_R|PTE_W|PTE_X)=0说明为非叶子结点(也即pte的PPN指向下一级页表)
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte); //得到下一级页表的物理地址
freewalk((pagetable_t)child); //递归下一级页表,会一直递归直到下层为空结点(因为叶子结点已经没有了)
pagetable[i] = 0; //回溯代码,遇到下层panic会将该上层页表置0
} else if(pte & PTE_V){ //说明叶子结点存在,这是非法情况
panic("freewalk: leaf");
}
}
kfree((void*)pagetable); //递归,循环512子节点后删除当前结点
}
uvmfree
将pagetable及其下级页表(叶子结点、非叶子结点)、相应的物理内存释放,sz采取上对齐。
1
2
3
4
5
6
7
8
9// Free user memory pages,
// then free page-table pages.
void
uvmfree(pagetable_t pagetable, uint64 sz)
{
if(sz > 0)
uvmunmap(pagetable, 0, PGROUNDUP(sz)/PGSIZE, 1);
freewalk(pagetable);
}
uvmcopy
这段代码用于将某个进程大小为sz的物理内存复制到新的一块物理内存,并且建立新页表new来表示新的映射关系。例如将父进程的内存拷贝到子进程中,注意拷贝是以页帧为基本单位的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// Given a parent process's page table, copy
// its memory into a child's page table.
// Copies both the page table and the
// physical memory.
// returns 0 on success, -1 on failure.
// frees any allocated pages on failure.
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
char *mem;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0) //页表项不存在,所以无法从页表old获取根据虚拟地址i找到最低级页号
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0) //页表项无效
panic("uvmcopy: page not present");
pa = PTE2PA(*pte); //物理地址
flags = PTE_FLAGS(*pte); //取十位标志位
if((mem = kalloc()) == 0)
goto err; //申请页帧失败,跳转出错处理
memmove(mem, (char*)pa, PGSIZE); //将原来物理地址空间pa复制到新物理内存页帧mem
if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){ //设置新页表项失败
kfree(mem); //释放刚刚申请的页帧
goto err; //出错处理
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1); //出错处理,将页表new的项都取消映射,因为此时页表由于某项出错导致复制不一致,也没有意义保留其他项
return -1;
}
uvmclear
通过walk获取最低一级页号,将这个页号的页表项(PPN指向物理内存)的flags的用户标志位U置0,代表将物理内存设置成用户不可访问。
1
2
3
4
5
6
7
8
9
10
11
12// mark a PTE invalid for user access.
// used by exec for the user stack guard page.
void
uvmclear(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
pte = walk(pagetable, va, 0);
if(pte == 0)
panic("uvmclear");
*pte &= ~PTE_U; //将U标志位置为0
}
copyout函数
在syscalls就涉及到了这个函数,作用就是将src地址的内核数据复制到用户空间dstva地址对应地址,实现数据的跨态传输。用户空间物理地址通过查询用户空间页表获得。
copyout采取余量按页复制,提高了内存的利用率,这种方法一定程度上避免了内部碎片问题,因为内存的复制是按页进行的,也考虑到了每页的剩余容量,只有最后一页有可能存在较大的页帧没有被覆盖使用,但是单块页帧内存很小,对整体利用率影响有限。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva); //下对齐,va是用户空间目标地址dstva的页帧起始地址
pa0 = walkaddr(pagetable, va0); //获取虚拟地址va0对应的物理地址pa0
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0); //计算当前页帧的余量(dastva到页帧末尾空间)
if(n > len) //如果余量大于长度len
n = len; //复制长度就是len
//如果余量小于len字节,那么只复制余量大小的数据
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n; //更新剩余需要复制字节
src += n; //更新源地址偏移量
dstva = va0 + PGSIZE; //到下一页复制
}
return 0;
}
copyin函数
从用户空间复制数据到内核空间,内核目标地址dst,用户物理地址由srcva通过用户页表pagetable转换获得;需要复制的数据总大小为len;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// Copy from user to kernel.
// Copy len bytes to dst from virtual address srcva in a given page table.
// Return 0 on success, -1 on error.
int
copyin(pagetable_t pagetable, char *dst, uint64 srcva, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(srcva);//下对齐,用户空间虚拟地址srcva起始地址
pa0 = walkaddr(pagetable, va0); //获取va0对应的物理地址
if(pa0 == 0)
return -1;
n = PGSIZE - (srcva - va0); //计算当前页复制数据的部分
if(n > len)
n = len; //如果当前页剩余部分数据大于len,说明不需要全部复制,只复制len即可
memmove(dst, (void *)(pa0 + (srcva - va0)), n); //复制
len -= n; //计算数据余量
dst += n; //目的地址偏移量后移
srcva = va0 + PGSIZE; //为什么是PGSIZE不是n呢?
//因为虚拟地址下一页(如果n<=len,说明页帧余量必然被len填满一页,所以加上PGSIZE到下一页;如果n>len,len-n是负数,下一次循环不会进入,不影响)
}
return 0;
}
copyinstr
copyinstr将srcva通过用户空间页表转换成物理地址pa0,将pa0的用户字符串复制到内核空间dst对应的物理内存,每次复制最大字节数是max大小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// Copy a null-terminated string from user to kernel.
// Copy bytes to dst from virtual address srcva in a given page table,
// until a '\0', or max.
// Return 0 on success, -1 on error.
int
copyinstr(pagetable_t pagetable, char *dst, uint64 srcva, uint64 max)
{
uint64 n, va0, pa0;
int got_null = 0;
while(got_null == 0 && max > 0){
//获取用户空间源串物理地址pa0
va0 = PGROUNDDOWN(srcva);
pa0 = walkaddr(pagetable, va0);
if(pa0 == 0)
return -1;
//计算每次复制大小
n = PGSIZE - (srcva - va0);
if(n > max)
n = max; //n是用于表示需要复制的字符数的
//不用memmove,p代表要对齐到复制地址的偏移量,即使复制字节为max,偏移量也是(srcva - va0)
char *p = (char *) (pa0 + (srcva - va0));
while(n > 0){ //复制的字节数
if(*p == '\0'){ //遇到结束符
*dst = '\0'; //dst也结束
got_null = 1; //结束符标志位
break; //跳出内层循环,然后也会因为标志位退出外层循环
} else {
*dst = *p; //没有结束符就将暂存字符串p更新到dst
}
--n; //逐字符递减
--max; //每次复制都会占用max,max也要更新
p++; //暂存位置的字符串偏移量++
dst++; //目标偏移量++
}
srcva = va0 + PGSIZE; //道理同copyin
}
if(got_null){
return 0;
} else {
return -1;
}
}
至此,我们将与物理内存分配回收相关的代码kalloc.c和页表、虚拟内存实现代码vm.c剖析完毕了。
Traps机制与系统调用
RISC-V汇编
由于MIT有另一门课(6.004)专门介绍了RISC-V汇编,因此这门课的介绍不会很深入。我这里也只是按照介绍做一些备忘录。
C to 汇编
我们说到一个RISC-V处理器时,意味着这个处理器能够理解RISC-V的指令集,任何一个处理器都有一个关联的ISA(Instruction Sets Architecture),ISA就是处理器能够理解的指令集,每一条指令都有一个对应的二进制编码或者一个Opcode。当处理器在运行时,如果看见了这些编码,那么处理器就知道该做什么样的操作。要让C语言能够运行在你的处理器之上。我们首先要写出C程序,之后这个C程序需要被编译成汇编语言。这个过程中有一些链接和其他的步骤(编译器的范畴),之后汇编语言会被翻译成二进制文件也就是.obj或者.o文件。
RISC-V vs x86
RISC-V中的RISC是精简指令集(Reduced Instruction Set Computer),x86通常被称为CISC,复杂指令集(Complex Instruction Set Computer)。例如Intel、AMD的CPU大多数属于x86处理器;RISC-V目前主要应用于一些嵌入式设备;ARM也是一种精简指令集,例如手机的CPU很多都基于ARM指令集,例如高通、苹果的处理器。
RISC-V:
指令数量更少;x86在1970年代发布,新的指令按照每月3条增加,作者认为现有超过15000条指令,许多三四十年前的旧指令还能被现代的Intel CPU执行,新的指令也要像这样向后兼容,或者执行特殊的CMD命令,所以十分庞大。而RISC-V只有十几年的发展历史,指令数量很少。
指令逻辑更加简单;在x86-64中,很多指令都做了不止一件事情。这些指令中的每一条都执行了一系列复杂的操作并返回结果。RISC-V的指令趋向于完成更简单的工作,相应的也消耗更少的CPU执行时间。但没有非常确定的原因说RISC比CISC更好,各自应用场景不同。
RISC-V是市场上唯一的一款开源指令集,任何人可以为RISC-V开发主板。
RISC-V寄存器
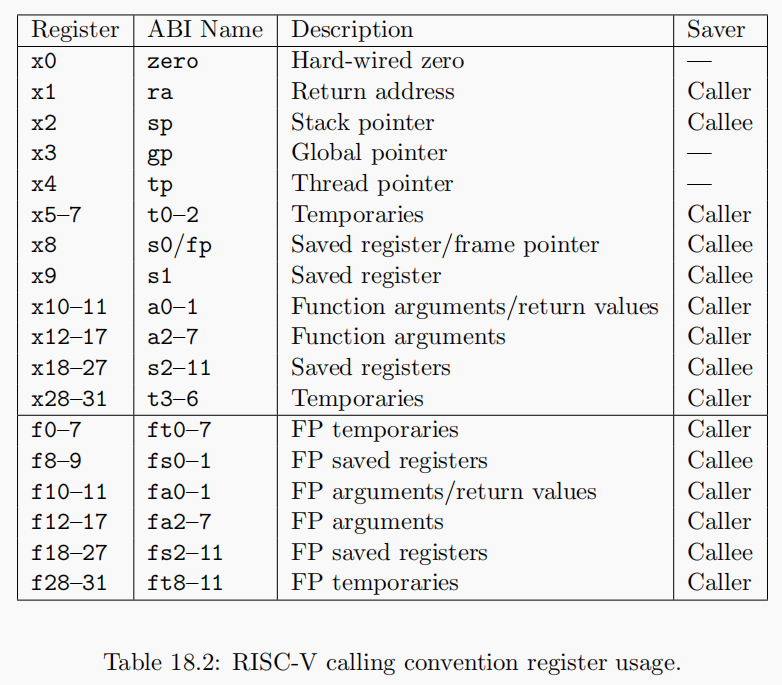
第一列为寄存器编号,并不是很重要,唯一重要的是只用于RISC-V的Compressed Instruction。基本上来说,RISC-V中通常的指令是64bit,但是在Compressed Instruction中指令是16bit。在Compressed Instruction中使用更少的寄存器,也就是x8-x15寄存器。
第二列为寄存器的ABI Name;除了Compressed Instruction,其他基本都是使用ABI Name,包括在汇编代码中使用的也是ABI Name;
RISC-V寄存器是汇编代码执行的单元,寄存器的数据来源、存储对象可以是另一个寄存器,也可以是内存。只有运算时迫不得已使用内存时才会使用内存。fa0~7存放浮点参数,多于8个可能需要使用a寄存器;a0~a7用于存放函数参数(整数、特殊的浮点函数),如果函数有8个整数参数,就不得不使用内存了。返回值还存放在a0、a1,超过也要使用内存,调用方分配内存,作为第一个隐含参数传递给接收方。除了自变量和返回值寄存器外,七个整数寄存器t0–t6和十二个浮点寄存器ft0–ft11是临时寄存器,它们在调用中是不稳定的,如果以后使用,则必须由调用方保存。12个整数寄存器s0–s11和12个浮点寄存器fs0–fs11在调用之间保留,如果使用,则必须由被调用方保存。(摘自RISC-V文档,自行查验)
第四列是Saver列,分为Caller,Callee两种类型;Caller是调用者保存策略,代表寄存器值在函数调用时不会保存(或者调用函数前自行保存),而Callee则在寄存器值调用时,被调用者即新函数负责保存,在返回时恢复保存的寄存器内容,保证新函数没有篡改寄存器内容,使得调用者正常使用。例如函数a调用函数b,被函数a使用的寄存器是Caller Saved寄存器,那么调用b时有可能会改变Caller Saved寄存器的数据。而Callee Saved寄存器则不会改变。
所有的寄存器都是64bit,各种各样的数据类型都会被改造的可以放进这64bit中。比如说我们有一个32bit的整数,取决于整数是不是有符号的,会通过在前面补32个0或者1来使得这个整数变成64bit并存在这些寄存器中。
RISC-V栈
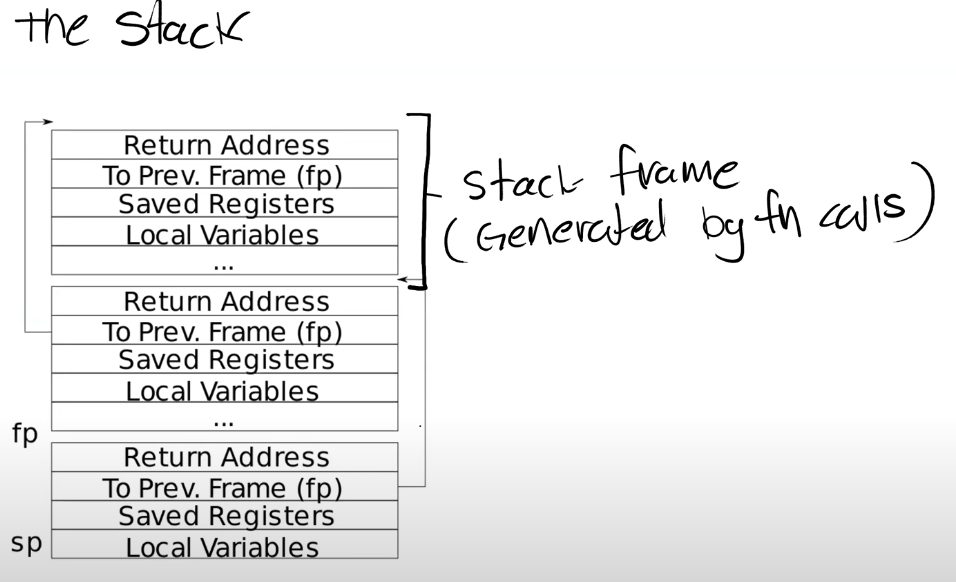 每一个区域都是一个Stack
Frame,每执行一次函数调用,函数会为自己创建一个Stack
Frame。RISC-V栈中约定从高地址向低地址使用,栈是向下延伸的。一个函数的Stack
Frame包含了保存的寄存器,本地变量,并且,如果函数的参数多于8个,额外的参数会出现在Stack中。所以Stack
Frame大小并不总是一样,即使在这个图里面看起来是一样大的。不同的函数有不同数量的本地变量,不同的寄存器,所以Stack
Frame的大小是不一样的。但是有关Stack Frame有两件事情是确定的:
每一个区域都是一个Stack
Frame,每执行一次函数调用,函数会为自己创建一个Stack
Frame。RISC-V栈中约定从高地址向低地址使用,栈是向下延伸的。一个函数的Stack
Frame包含了保存的寄存器,本地变量,并且,如果函数的参数多于8个,额外的参数会出现在Stack中。所以Stack
Frame大小并不总是一样,即使在这个图里面看起来是一样大的。不同的函数有不同数量的本地变量,不同的寄存器,所以Stack
Frame的大小是不一样的。但是有关Stack Frame有两件事情是确定的:
Return address(RA)是函数调用返回的地址,总是会出现在Stack Frame的第一位,调用产生新的Stack Frame,会将返回地址放在栈底;
指向前一个Stack Frame的栈底指针(fp)指针也会出现在栈中的固定位置;
有关Stack Frame中有两个重要的寄存器,第一个是SP(Stack
Pointer),它指向Stack的底部(但是它是栈顶指针,即延伸端,翻译害死人)并代表了当前Stack
Frame的位置。第二个是FP(Frame Pointer),它指向当前Stack
Frame的顶部(栈底指针,栈的第一个位置)。因为Return
address和指向前一个Stack Frame的的指针都在当前Stack
Frame的固定位置,所以可以通过当前的FP寄存器寻址到这两个数据。
Stack Frame存储前一个栈的fp指针原因是可以跳转回去(例如函数调用的时候),每发生一个调用,就要对当前Stack Frame做减法(堆栈指针一般是16字节对齐),也即-16;相反如果函数调用返回,就对sp寄存器+16;其中返回地址RA占8个字节;
没有进行函数调用的函数称为leaf函数,而如果内部调用的其他函数就不算leaf函数,其汇编如下所示:
 一般而言汇编产生函数调用会经历:SP更新为调用函数创建Stack
Frame,将当前函数RA更新到新Stack
Frame的RA,将当前函数的帧指针(FP)放入新Stack
Frame的固定位置(汇编中未体现);
一般而言汇编产生函数调用会经历:SP更新为调用函数创建Stack
Frame,将当前函数RA更新到新Stack
Frame的RA,将当前函数的帧指针(FP)放入新Stack
Frame的固定位置(汇编中未体现);
所以在上图中addi(sp=sp-16)和sd(store double,sp+0=ra,将ra保存到sp指针(新栈)的位置)作为prologue(序言),ld(load double,ra=sp+0,sp和偏移量位置载入到ra寄存器)和addo作为Epilogue,中间部分为函数主体;如果只有函数主体,那么sum_then_double的RA会被调用函数sum_to覆盖,导致无法返回。
Trap机制
在syscalls我们稍微了解了陷入trap,trap完成了用户空间和内核空间的切换,例如发生:
- 程序执行程序调用
- 程序出现了类似page fault、运算时除以0的错误
- 一个设备触发了中断使得当前程序运行需要响应内核设备驱动
均会触发切换。
trap机制设计应该注意安全的隔离性以及性能,因为内核的切换可能是频繁的,trap机制需要尽可能的简单。
陷入相关寄存器
用户可以使用之前我们介绍的所有寄存器,当Trap机制触发时,其中有些特殊寄存器需要介绍:
陷入向量寄存器:如stvec(Supervisor Trap Vector Base Address Register)寄存器存储了监管者模式处理陷入程序的基地址;对应又有mtvec、utvec寄存器;
状态寄存器:如sstatus(Supervisor status register)寄存器存储了一些标志位;对应的也有mstatus、ustatus比较重要的例如:
SIE(Supervisor Interrupt Enable):监管者模式中断使能,为1开启中断使能,为0禁用中断;
SPP (Supervisor Previous Privilege):保存异常发生前的特权级别,0代表用户模式,1代表监管者模式;
陷入原因寄存器:如scause(Supervisor trap cause register)寄存器,存储了监管模式下陷入发生的原因,例如系统调用、异常故障、中断等;对应也有mcause、ucause寄存器。
异常程序计数器:如sepc(Supervisor exception program counter),存储了异常、中断发生时程序计数值,也即没有异常情况即将执行的指令,方便处理完后恢复现场。对应也有uepc、mepc。
sscratch (Scratch register for supervisor trap handler):异常、中断发生时程序会跳转到stvec执行程序,初始时sscratch存储着TRAPFRAME地址,这个页将被用于存储用户寄存器数据。
此外还有程序计数器(Program Counter Register)、SATP寄存器(顶级页表)等。
可以看见寄存器的分类和命名是比较清晰的,在xv6中监管者模式比起用户模式得到的特权并不多。主要体现在两个方面:
监管者模式能自由读写sscratch、SATP、STVEC、SEPC等寄存器,它们是Trap机制的主角,其他的m、u并不那么重要。
监管者模式能够读写PTE_U为0的页表项;另一方面来说,监管者模式不能自由读写内存,和用户模式一样需要通过页表读写内存,如果PTE_U为0代表用户不能访问而监管模式可以访问,PTE_U为1代表监管者模式可以访问而用户模式不能访问。
。。。。。。。好像没有体现出“特权”。
系统调用的trap流程(GDB与sysinfo)
Lecture6是信息价值很高的一节课,教授使用GDB跟踪了一次write系统调用流程,但由于我的xv6版本sh.c的write系统调用已经被弃用,因此我gdb追踪的是之前在syscall实验中的sysinfo调用;切换到syscall分支并且启gdb:
用户空间
1 | file user/_sysinfotest |
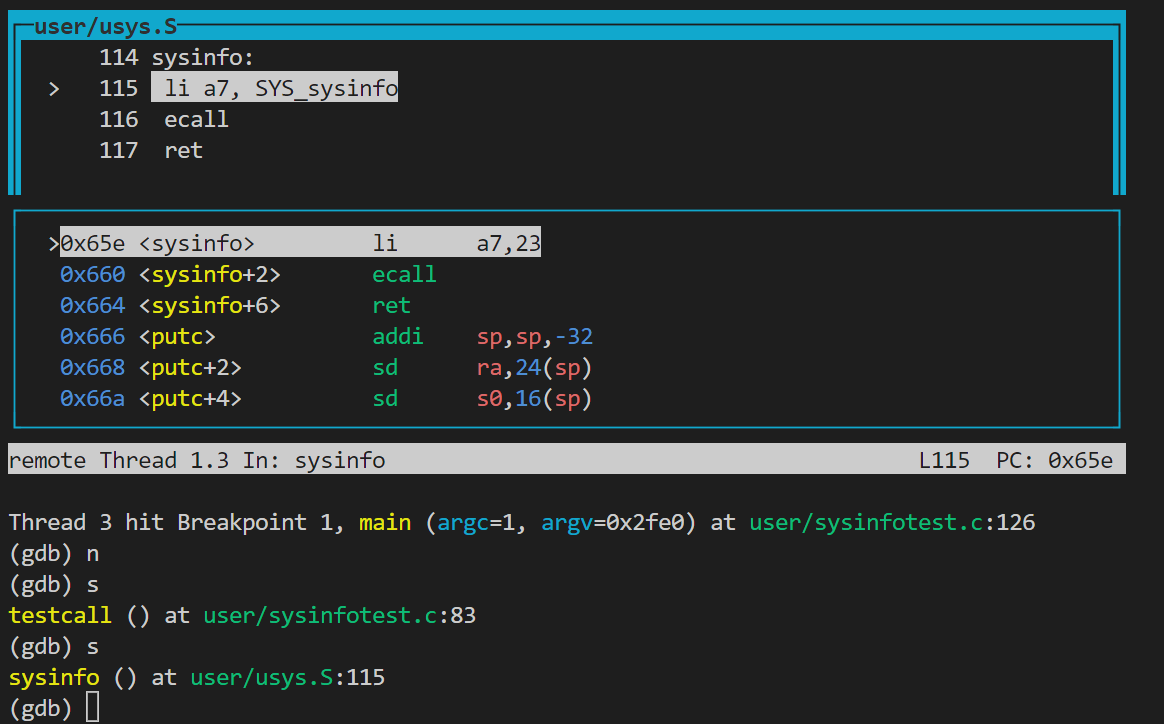 可见这里将系统调用号SYS_sysinfo传值给a7寄存器。
可见这里将系统调用号SYS_sysinfo传值给a7寄存器。
ecall指令
从图中看得出ecall断点为0x660,或者参考sysinfotest.c;ecall是一条CPU指令,不会出现其他代码,但这里我们可以尝试看一下ecall前后寄存器变化情况,以理解ecall完成了什么工作;
1
2
3
4
5
6
7b *0x660
c
info reg #pc=0x660 sp=0x2fb0(栈顶,低地址) fp=0x2fd0(栈底,高地址)
p/x $satp #$1 = 0x8000000000087f48
si #进入ecall内核地址
查看xv6虚拟内存的映射 1
2
3
4
5#无需退出qemu,直接输入即可
ctrl+a c
info mem
#退出同样命令
ctrl+a c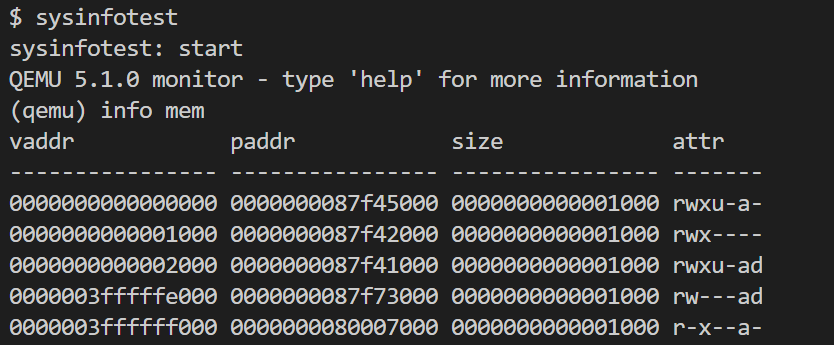 sh作为用户进程运行,这里打印了用户空间shell的进程页表映射。对于这里的权限标志位,从左至右应当为rwxugad,其中rwx是读写执行,u为用户标记,g为Global是否所有进程共享,ad代表是否被使用、修改(与页表调度有关,详见内存管理一文)。
sh作为用户进程运行,这里打印了用户空间shell的进程页表映射。对于这里的权限标志位,从左至右应当为rwxugad,其中rwx是读写执行,u为用户标记,g为Global是否所有进程共享,ad代表是否被使用、修改(与页表调度有关,详见内存管理一文)。
需要留意最后一个页表项0x3ffffff000,这个页表项作为trampoline。
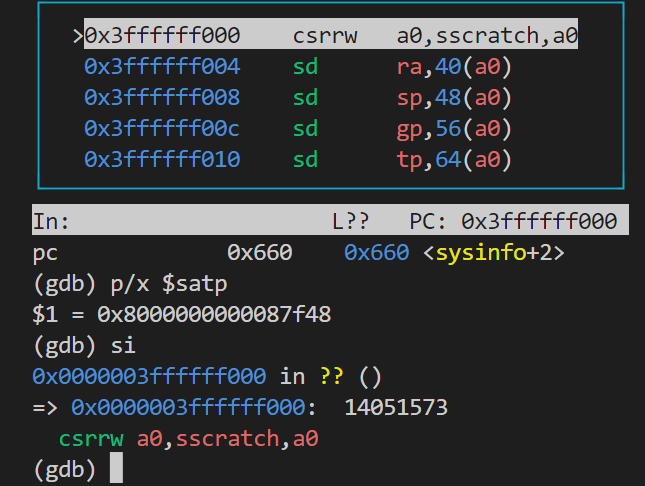 此时查看寄存器:
此时查看寄存器: 1
2
3
4
5#进入ecall后
info reg #pc=0x3ffffff000 sp=0x2fb0(栈顶,低地址) fp=0x2fd0(栈底,高地址)
p/x $stvec #$1=0x3ffffff000 #陷入向量寄存器,存储陷入发生时跳转的地址
p/x $sepc #$2=0x0660 # 异常程序计数器,存储陷入发生时命令的pc
总结来说,ecall完成的任务很简单:
从用户模式切换至监管者模式;
将陷入发生的PC设置到SEPC中;(设置sstatus、scause寄存器、清除SIE禁用中断(避免嵌套陷入)等)
跳转到STVEC寄存器存储的地址,即内存的trampoline页;
为了后续执行内核C代码,还有几项工作没有完成:
保存所有用户寄存器的值,以便内核处理完成恢复现场;
从用户页表切换到内核页表;
为内核找到一个内核栈或者新建一个,并且更新SP指向,为C代码提供执行空间;
跳转到C代码执行位置;
RISC-V设计者想要为软件和操作系统的程序员提供最大的灵活性,在一些任务和内核设计下,前三种任务都不是必须的,因此设计者们没有让ecall完成上述的工作。
uservec函数
目前通过ecall跳转到trampoline页起始,此时还不能执行内核的C代码,而需要执行一段汇编代码,这个代码位于trampoline.S
1 | # |
介绍uservec第一条命令前,先介绍xv6保存用户寄存器的方法;在一些操作系统中,直接将寄存器写入物理内存是可以的,但是对于RISC-V,尽管处于监管者模式也不支持直接操作物理内存;另一种方法是直接设置SATP更换内核页表,通过内核页表就可以操作物理内存了,将用户寄存器映射到物理内存上,但SATP要求数据来源需要来自另一个寄存器,我们现在没有空闲寄存器就实现不了这样的操作;
xv6采取的策略是在每个用户页表都映射了一块trapframe页,这个页的其中一个作用就用于存储用户寄存器的值。首先trapframe的映射地址被放在sscratch寄存器中,sscratch存储的虚拟地址(也是trapframe的虚拟地址)总是0x3ffffffe000。
第一条命令是csrrw a0, sscratch, a0,交换sscratch和a0寄存器的值;此时a0寄存器就变成了0x3ffffffe000;
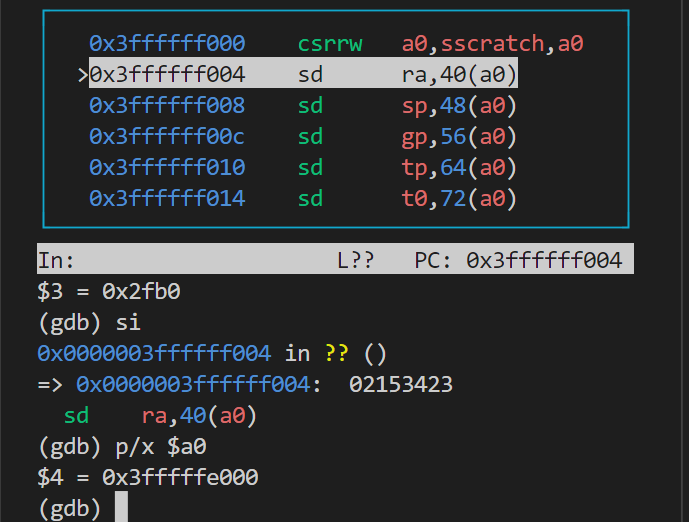 随后紧跟了30条sd命令,作用就是保存30个寄存器(除了zero寄存器,恒为0)到a0的偏移量,此时a0代表trapframe的虚拟地址;
随后紧跟了30条sd命令,作用就是保存30个寄存器(除了zero寄存器,恒为0)到a0的偏移量,此时a0代表trapframe的虚拟地址;
trapframe除了提供空槽存储这31个寄存器,也存储了内核页表的相关信息,从kernel/proc.h可以找到trapframe结构体:注释数字就代表对应的偏移量;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct trapframe {
/* 0 */ uint64 kernel_satp; // kernel page table
/* 8 */ uint64 kernel_sp; // top of process's kernel stack
/* 16 */ uint64 kernel_trap; // usertrap()
/* 24 */ uint64 epc; // saved user program counter
/* 32 */ uint64 kernel_hartid; // saved kernel tp
/* 40 */ uint64 ra; /* 48 */ uint64 sp; /* 56 */ uint64 gp;
/* 64 */ uint64 tp; /* 72 */ uint64 t0; /* 80 */ uint64 t1;
/* 88 */ uint64 t2; /* 96 */ uint64 s0; /* 104 */ uint64 s1;
/* 112 */ uint64 a0; /* 120 */ uint64 a1; /* 128 */ uint64 a2;
/* 136 */ uint64 a3; /* 144 */ uint64 a4; /* 152 */ uint64 a5;
/* 160 */ uint64 a6; /* 168 */ uint64 a7; /* 176 */ uint64 s2;
/* 184 */ uint64 s3; /* 192 */ uint64 s4; /* 200 */ uint64 s5;
/* 208 */ uint64 s6; /* 216 */ uint64 s7; /* 224 */ uint64 s8;
/* 232 */ uint64 s9; /* 240 */ uint64 s10;/* 248 */ uint64 s11;
/* 256 */ uint64 t3; /* 264 */ uint64 t4; /* 272 */ uint64 t5; /* 280 */ uint64 t6;
};csrr t0, sscratch和sd t0, 112(a0)重新存入a0,注意这只是将sscratch存入软件的a0,没有覆盖a0寄存器的地址值;后面通过ld命令更新sp内核栈、核心编号、写入satp、刷新快表等,此时就将用户页表切换成内核页表了。后续就会跳转到C代码继续执行;
总的来说,这段uservec代码完成了我们留在ecall没完成的四个工作,包括保存用户寄存器值、切换到内核页表、准备内核栈、跳转到C代码入口等。
一些问题:
- 为什么寄存器值需要保存在特殊的trapframe页,而不是用户的栈空间?
因为有一些编程语言可能不需要栈空间,也有一些编程语言的栈空间是特殊的、内核不能理解(例如按小块分配),因此不能依赖于用户栈空间,而需要trapframe,而且这个trapframe是由内核进行管理的。
- uservec完成了页表的切换,但是不同的页表同一个虚拟内存的映射都是不一样的,为什么切换页表前后代码没有崩溃,而且还能执行汇编指令?
此时我们重新执行info mem如图: 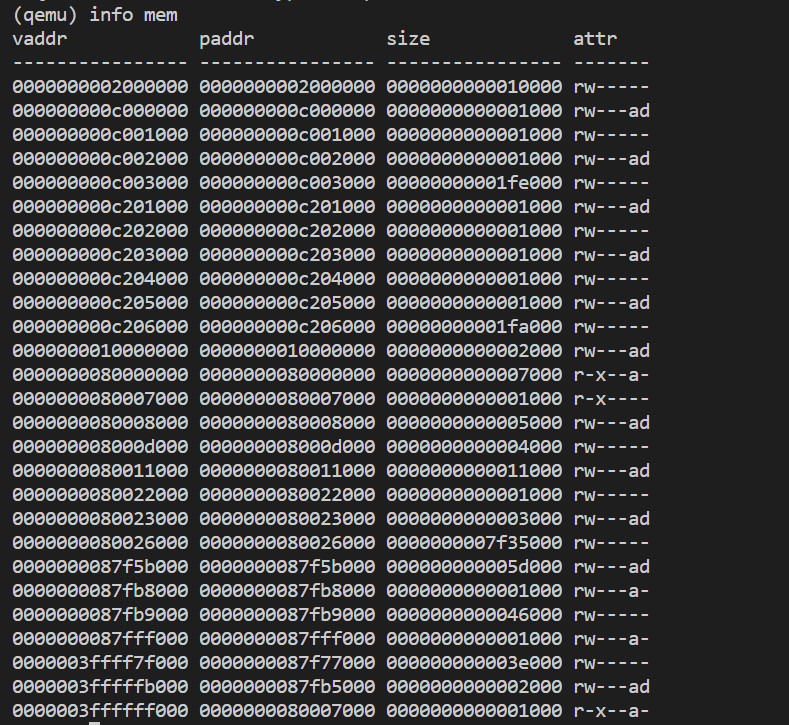 页表的确变成了内核页表;之所以没有发生崩溃,是因为我们仍然处于trampoline页中,在之前内存布局的照片,内核栈和tranpoline都不是直接映射的;也就是说无论是用户页的trampoline还是内核页的trampoline,这部分的所有代码、数据都会被映射到物理内存的同一个区域;因此在trampoline里面执行uservec代码、切换页表不会发生程序崩溃。
页表的确变成了内核页表;之所以没有发生崩溃,是因为我们仍然处于trampoline页中,在之前内存布局的照片,内核栈和tranpoline都不是直接映射的;也就是说无论是用户页的trampoline还是内核页的trampoline,这部分的所有代码、数据都会被映射到物理内存的同一个区域;因此在trampoline里面执行uservec代码、切换页表不会发生程序崩溃。
usertrap函数
usertrap是执行汇编代码后的内核执行的第一个C代码,这个代码目前主要用于处理因为系统调用产生的中断;首先它会检查是否从用户空间发生陷入,如果陷入是来自内核空间,就触发panic(内核陷入不需要用户陷入那么繁琐的处理);接下来为了防止处理系统调用时发生可能存在的异常中断行为,就需要将STVEC寄存器(异常跳转地址)设置成kernelvec、在trapframe备份SEPC寄存器中的用户PC;最后判断陷入原因,如果是系统调用引发的中断就调用kernel/syscall.c中的syscall函数并且开启中断使能;如果是设备中断,本节没有定义具体行为,如果是时钟中断(时间片用完啦)需要让出CPU,其他未定义中断则报错。更多原因见代码更直观:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57//
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void
usertrap(void)
{
int which_dev = 0;
//读取sstatus取SPP特权位,如果等于0说明陷入前是用户模式,不等于0就panic
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
//如果再次触发中断需要跳转到kernelvec,让内核处理,不然反复跳到uservec处理异常中断是不正确行为
w_stvec((uint64)kernelvec);
struct proc *p = myproc(); //获取CPU进程
// save user program counter.
//读取sepc寄存器,当前的sepc存储着用户的程序计数器(例子中就是0x660的ecall指令),如果再触发中断会覆盖,就无法恢复用户空间了。
//因此需要在软件再备份
p->trapframe->epc = r_sepc();
if(r_scause() == 8){ //8代表陷入原因为系统调用
// system call
if(p->killed) //进程杀死就没了
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4; //ecall占4字节,下次恢复现场跳过ecall执行
// an interrupt will change sstatus &c registers,
// so don't enable until done with those registers.
intr_on(); //开启中断,因为后面要调用系统调用,可能耗时间长,允许中断执行任务提高系统性能
syscall(); //调用syscall
} else if((which_dev = devintr()) != 0){ //代表设备中断,暂时没有定义行为
// ok
} else { //未定义陷入原因,报错,结束进程
printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);
printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());
p->killed = 1;
}
if(p->killed)
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2) //如果是时钟中断,让出cpu
yield();
usertrapret(); //准备返回用户空间
}
usertrapret函数
usertrapret函数同样位于kernel/trap.c,定义了从内核空间返回用户空间前的一些准备工作,包括关闭中断、归还内核信息,设置SEPC为即将用户空间的异常处理入口uservec,设置SSTATUS寄存器数据(SSP用户模式,中断使能),计算下一个函数userret的调用地址,通过函数指针调用传入TRAPFRAME基址和用户页表的SATP参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44void
usertrapret(void)
{
struct proc *p = myproc();
// we're about to switch the destination of traps from
// kerneltrap() to usertrap(), so turn off interrupts until
// we're back in user space, where usertrap() is correct.
intr_off();//关闭中断,因为后面需要将traps目标重新定义为用户的usertrap,但是仍然在内核执行代码,此时中断会触发奇怪的错误
// send syscalls, interrupts, and exceptions to trampoline.S
w_stvec(TRAMPOLINE + (uservec - trampoline)); //将STVEC重新定义为用户陷入入口,实际上就是uservec
// set up trapframe values that uservec will need when
// the process next re-enters the kernel.
//内核信息用完了,归还给trapframe下次陷入内核继续使用
p->trapframe->kernel_satp = r_satp(); // kernel page table
p->trapframe->kernel_sp = p->kstack + PGSIZE; // process's kernel stack
p->trapframe->kernel_trap = (uint64)usertrap;
p->trapframe->kernel_hartid = r_tp(); // hartid for cpuid()
// set up the registers that trampoline.S's sret will use
// to get to user space.
// set S Previous Privilege mode to User.
//设置用户空间的SSTATUS寄存器,SPP为0代表用户模式,SPIE为1代表在用户空间启用中断
unsigned long x = r_sstatus();
x &= ~SSTATUS_SPP; // clear SPP to 0 for user mode
x |= SSTATUS_SPIE; // enable interrupts in user mode
w_sstatus(x);
// set S Exception Program Counter to the saved user pc.
w_sepc(p->trapframe->epc); //这是备份的SEPC,存储原来用户的PC,重新取出来写入SEPC(防止SEPC已经被其他异常中断程序修改)
// tell trampoline.S the user page table to switch to.
uint64 satp = MAKE_SATP(p->pagetable); //进程p->pagetable字段就是对应进程的用户页表,产生SATP值
// jump to trampoline.S at the top of memory, which
// switches to the user page table, restores user registers,
// and switches to user mode with sret.
uint64 fn = TRAMPOLINE + (userret - trampoline); //fn代表userret函数的虚拟地址
((void (*)(uint64,uint64))fn)(TRAPFRAME, satp); //函数指针的调用方法,跳转到userret函数,TRAPFRAME和satp分别作为参数
}
userret函数
准备工作完成,后面的工作继续由汇编函数userret完成,它是kernel/trampoline.S汇编代码的下半部分,页表切换的代码都需要在trampoline完成,因为只有这个地方内核和用户到物理内存的映射是一致的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55.globl userret
userret:
# userret(TRAPFRAME, pagetable)
# switch from kernel to user.
# usertrapret() calls here.
# a0: TRAPFRAME, in user page table.
# a1: user page table, for satp.
# switch to the user page table.
csrw satp, a1 #指针调用TRAPFRAME在a0参数寄存器,satp在a1参数寄存器,即读入用户页表的SATP值
sfence.vma zero, zero #刷新缓存
# put the saved user a0 in sscratch, so we
# can swap it with our a0 (TRAPFRAME) in the last step.
ld t0, 112(a0) #a0寄存器TRAPFRAME,112(a0)是软件存储的a0,存储的是原来寄存器值(用户数据)
csrw sscratch, t0 #sscratch存放的是用户数据值
# restore all but a0 from TRAPFRAME
ld ra, 40(a0) #这里的a0是寄存器的a0,即参数TRAPFRAME,从TRAPFRAME恢复用户寄存器
ld sp, 48(a0)
ld gp, 56(a0)
ld tp, 64(a0)
ld t0, 72(a0)
ld t1, 80(a0)
ld t2, 88(a0)
ld s0, 96(a0)
ld s1, 104(a0)
ld a1, 120(a0)
ld a2, 128(a0)
ld a3, 136(a0)
ld a4, 144(a0)
ld a5, 152(a0)
ld a6, 160(a0)
ld a7, 168(a0)
ld s2, 176(a0)
ld s3, 184(a0)
ld s4, 192(a0)
ld s5, 200(a0)
ld s6, 208(a0)
ld s7, 216(a0)
ld s8, 224(a0)
ld s9, 232(a0)
ld s10, 240(a0)
ld s11, 248(a0)
ld t3, 256(a0)
ld t4, 264(a0)
ld t5, 272(a0)
ld t6, 280(a0)
# restore user a0, and save TRAPFRAME in sscratch
csrrw a0, sscratch, a0 #交换sscratch,a0,a0就存储原来用户的数据,sscratch存储TRAPFRAME基址
# return to user mode and user pc.
# usertrapret() set up sstatus and sepc.
sret #返回用户空间
另一个值得注意的地方我们没有在uservec提到,sscratch中TRAPFRAME的数据来源是上一次内核空间返回,与a0交换而来的,这个函数与uservec形成了闭环。而实际上,xv6启动时必然是从内核开始载入的,因此每次系统启动完成,sscratch就存有TRAPFRAME;
Page Fault页面错误
Page Fault不是一个需要避免的错误,相反,很多情况下我们希望在虚拟内存、内存分配中主动触发这个错误,再使用适当的手段去加以解决,这样反而在一定程度上提高了系统性能和内存分配的利用率,这是因为我们无需考虑预先慷慨地给进程分配一大块不必要的空间。善用页面错误是很多现代操作系统实现的基础,遗憾的是xv6并没有太多这样的设计,遇到Page Fault基本都直接将进程杀掉。所以本节也不能涉及代码的介绍,仅是一些有趣功能的设计思想,日后遇到再更出来吧。这些有趣的功能包括:
- lazy allocation
- copy-on-write fork
- demand paging
- memory mapped files
Page Fault处理
虚拟内存存在这样的两个优点:
隔离性;虚拟内存机制允许操作系统为每个用户程序分配专属的地址空间,一个程序不可能有意或者无意地修改另一个程序数据;其次也提供了内核和用户空间的隔离性;
提供了一层抽象;处理器和所有的指令都可以使用虚拟地址,内核会定义虚拟地址和物理地址的映射;除了trampoline和kernel stack,以及没有被映射的guard page,大部分内存都采取了直接映射;但目前的映射关系都是静态的,一开始页表设置了映射关系就不会改变。
Page Fault能够改变这一点,通过页表错误,能够更新内核和用户页表,使映射关系变得动态。
为了响应和处理Page Fault,内核需要三个信息,也是三个重要寄存器信息:
Stval寄存器:存储了出错时的虚拟地址。(注意不是stvec);
Scause寄存器:存储了存储的原因,如下表:

SEPC寄存器:存储了出错时导致出错指令的地址,同时也会保存在trapframe的epc中(方便恢复现场)。
Lazy Page Allocation
进程往往倾向于提前申请一个超过自身需要的空间,这个申请通过sbrk通过系统调用sys_sbrk实现,sys_sbrk调用growproc函数为进程延伸n字节大小空间;页懒分配的思想就是我们仅“虚拟地”增加其需要,实际上并不分配物理空间,因此有:
1
2
3
4
5
6
7
8
9
10
11
12
13uint64
sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
addr = myproc()->sz;
myproc()->sz=myproc()->sz+n;//new
//if(growproc(n) < 0)
// return -1;
return addr;
}echo hi会如愿得到一个pagefault:
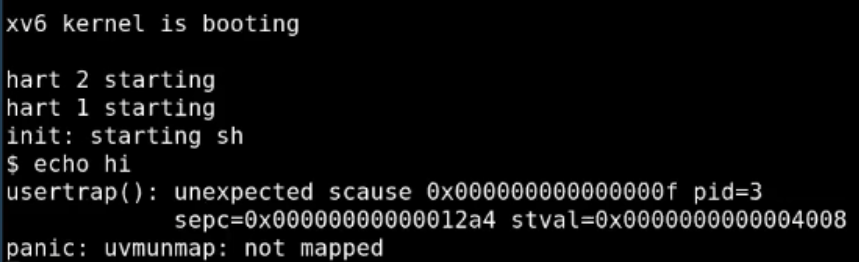 scause为15代表错误类型是
scause为15代表错误类型是page fault,shell进程pid为3,出错指令地址0x12a4,出错虚拟内存4008;因为我们没有分配物理内存,所以引发了页面的错误;panic和后面的一起讨论;
为了解决这个pagefault,需要在别的地方为进程分配内存,例如当出现页面错误时就说明了进程需要物理内存,所以在trap.c处理时,新增页面错误的处理机制:
 这里如果出现pagefault,就读取stval获取错误的虚拟地址,为其分配内存,此时重新运行
这里如果出现pagefault,就读取stval获取错误的虚拟地址,为其分配内存,此时重新运行echo hi:
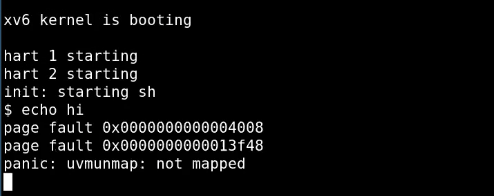 这里打印出现的page
fault我们已经处理了,仅打印信息而并没有阻塞进程,进程被
这里打印出现的page
fault我们已经处理了,仅打印信息而并没有阻塞进程,进程被unmap阻塞,这里和第一次运行的都是因为:uvmunmap释放了不存在的物理内存。
这里可能有一点疑问,为什么kalloc了还会触发这样的panic?
运行echo hi,myproc()->sz=myproc()->sz+n增加了虚拟内存,但注意我们此时采用的是懒分配策略,因此物理内存没有实质性的增加;当发生了第一个和第二个page
fault,确实增加了物理内存,但是也可能会遇到一种情况:也即增加了虚拟内存,但是没有触发page
fault,因为前面提过进程会倾向于申请更多不必要的虚拟内存,所以实际上进程连虚拟内存都没用完,自然不会触发page
fault,导致物理内存也没有分配(对应的页表项无效或者有效位设置成0)。然而,freeproc时是根据申请的虚拟内存大小(myproc()->sz)回收的,具体表现在freeproc调用了proc_freepagetable调用了uvmfree,释放页帧数量=上对齐的进程虚拟大小/页帧大小,因此触发了uvmunmap。
所以Fans教授给出一种简单的解决方法就是:当uvmunmap发现有无效的页表项时,不要使用panic,而是跳过继续释放下一个页表。
Zero Fill On Demand
第二个有趣的page fault技术是Zero Fill On
Demand(按需填零),本节没有设计lab,仅当了解。Zero Fill On
Demand聚焦一个地方:BSS段的数据变量存储。在用户地址空间中,包含了text代码段和data数据段(存储初始化完成的全局变量、静态变量),还包含一个BSS段用于存储未初始化、初始化为0的全局变量、静态变量。
 Zero Fill On
Demand的思想就是既然BSS段存储的都是0,那么无需每个进程都开辟一块物理内存存放这样的零矩阵,可以将每个程序的BSS段都映射到同一块内存中,内存数据全部为0,而且因为该内存是共享的,因此PTE设置成只读。
Zero Fill On
Demand的思想就是既然BSS段存储的都是0,那么无需每个进程都开辟一块物理内存存放这样的零矩阵,可以将每个程序的BSS段都映射到同一块内存中,内存数据全部为0,而且因为该内存是共享的,因此PTE设置成只读。
这时一旦出现用户进程对BSS段的写操作(将变量初始化等),就会出现page fault。为了处理这个page fault,就为其分配一个物理内存,将PTE设置成读写,映射到新内存再指向写操作指令。
这种方法的优点是节省了内存,而且系统启动时进程无需将BSS段保存到内存中,只需要设置一个映射关系即可,性能提高。但值得注意的是,性能的提高并非是一定的,如果存在大量的BSS段需要读写,那么就会频发引发page fault,而page fault的代价比将程序拷贝到内存的代价大得多,因为触发page fault就需要陷入到内核空间,在那里就保留了31个用户寄存器并且切换页表等。
Copy on Write Fork
Copy on Write Fork(写时复制)是第七个lab内容,从原理来说和Zero Fill On Demand是基本一致的,Copy on Write Fork聚焦于一个操作场景:父进程创建子进程时,系统会为子进程分配物理内存,并且拷贝父进程,但是子进程未必会进行写操作,也即这些物理内存有可能是未被利用的。例如,在xv6系统启动时,父进程Shell占4个字节,shell会调用fork新建子进程,子进程得到同样的4字节空间,而子进程很快就会被exec替换成其他进程(如echo),这个替换的第一时间就是丢弃子进程的地址空间,因此这样的分配操作既带来了内存的浪费,也带来了分配的性能开销。
Copy on Write Fork的思想就是在父进程调用fork创建子进程时,不会直接分配物理内存,子进程的物理内存将指向父进程的地址空间。同Zero Fill On Demand类似,这块空间会被设置成只读,来保证数据的安全。一旦发生对子进程的写操作(例如copyout),就会触发page fault。
为了处理这个page fault,可以为子进程分配新的物理内存(更多的细节请参考实验)。另一方面,从以前的xv6系统来看,处理多进程共享内存只有在trampoline那里看过,这是一块由内核、用户进程共同拥有的地址空间,不同的是,trampoline永远不会释放物理内存。但是这里分配的物理内存需要考虑释放的时机,因此需要引入计数机制来统计一块物理内存被多少进程共享了。
Demand Paging
Demand Paging这节也没有对应的lab,仅当了解。Demand Paging聚焦于一个操作:加载程序的指令和数据进入内存;xv6采取了一种eager加载的方式,即会一次性将程序的text和data全部载入内存。Demand Paging只会按需地读入数据,其他数据会存放在外存,当遇到找不到数据触发page fault,就可以使用某些handler从外存读取数据。
这部分以及内存映射文件部分在内存管理一文讨论比较详细,包括遇到OOM情况,如何确定调度的策略?LRU、Clock算法等,为什么一般需要换出non-dirty page(读入内存但未被修改的页),详细可以参考内存管理的页面置换一节。
线程Thread
线程概述
xv6线程从结合两方面技术,其一xv6线程可以运行在多核CPU中,所有可用的CPU都可以运行xv6的线程(指的是线程不同时间能被多个CPU调度,绝对不是单个线程同时运行在多个CPU上);其二每个CPU可以实现线程的自由切换。不同的线程系统主要区别是线程之间是否共享内存。
对xv6来说,每个用户进程都有一个内核线程,这个线程可以响应用户的系统调用,而且这个内核线程的内存是所有用户进程共享的。其次,xv6每个用户进程只有一个用户线程,这个线程控制了用户代码指令的执行,每个用户线程的地址空间是独立而不共享的。
对其他一些更复杂的操作系统,如Linux,则运行单个用户进程同时控制多个用户线程,这种跟踪多个线程的机制是复杂的。
除了线程以外,还有其他支持多任务方法,如event-driven programming、state machine等;线程不是其中最有效的方法,但是它是最简洁、对程序员最友好、最方便的方法。
xv6线程调度
xv6线程调度需要解释三个问题:
如何实现线程间的切换;
如何处理运算密集型线程(指的是那些需要长时间计算、不会自愿让出CPU控制的线程,需要系统主动撤回CPU的控制并且稍后继续运行);
线程调度时需要保存前一个线程的数据和状态,需要考虑要保存哪些信息、在哪里保存这些信息以及如何恢复它们;
第一个问题:对于线程的调度,xv6会为每个CPU都创建一个线程调度器(Scheduler),停止一个进程并且运行另一个进程的过程被称为线程调度(Scheduling)
第二个问题:通过pre-emptive scheduling(抢占式调度);这种调度依赖于优先级高的中断(如定时器中断),中断触发,无论用户进程在运行什么进程就会陷入到内核(实际就是用户进程的内核线程)处理中断,这时内核会使用yield将CPU让出,同时会告诉线程调度器可以运行其他线程了。
与其相反的是voluntary scheduling(自愿式调度);用户线程会主动调用系统调用yield让出线程,无需定时器中断这种优先级别高的进行强力抢占。
第三个问题:线程重要的信息是PC、寄存器、栈空间、状态等,用户寄存器还是会被保存到trapframe,内核寄存器会被保存到context,它是一个进程维护的字段,更多细节会在下节描述。
xv6线程切换
xv6中,线程的分类大致分为三类,对应三个状态
RUNNIGN,线程当前正在某个CPU上运行;
RUNABLE,线程当前没有在某个CPU上运行,但是处于就绪状态,一旦CPU空闲就可以运行;
SLEEPING,线程等待一些I/O事件,只有事件发生才能唤醒被运行;
这里的线程切换主要先针对前两种状态进行描述。
一个xv6线程切换程序
在xv6这种简化的操作系统,谈到线程切换,实际上就是进程的切换。因为用户进程只有单个线程,线程的切换,必然经过:
1.
将用户寄存器保存到trapframe,切换到内核线程运行内核栈代码,保存内核寄存器到context;
2.
从当前进程的内核线程切换到另一个进程的内核线程(调度器线程的任务),恢复其context;
3. 从另一个进程内核线程trapframe恢复用户寄存器,返回用户空间。
从整个描述来看,既是切换了线程,也切换了进程,但不要因此混淆了线程和进程,也不要因此纠结xv6的术语描述。
首先回顾一下进程字段,对线程切换而言,重要的字段有lock、state(三种线程状态+僵尸态+未使用的进程)、kstack(内核栈)、trapframe、context等;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state,enum procstate { UNUSED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
struct proc *parent; // Parent process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
通过一个示例程序体会进程的切换:子进程赋值为斜杆,父进程赋值为反斜杠,i递增100w次就会输出到控制台;这是一个运算密集型进程,因为进程i是无限增大的,进程不会主动让出CPU;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int main(int argc,char *arvg[]){
int pid;
char c;
pid=fork();
if(pid==0){
c = '/';
}
else{
printf("parent pid is %d,child pid is %d",getpid(),pid);
c='\\';
}
for(int i =0;;i++){
if((i%1000000)==0)
write(2,&c,1);
}
exit(0);
}
```**
父子进程能够切换运行,说明时间片是生效的,所谓时间片就是定时中断的作用。添加上述程序到用户Makefile,使用gdb进行追踪:
```bash
spin #循环输出斜杠、反斜杠
ctrl+c kernel\trap.c的devintr()函数:
1
2b trap.c:207
c1
2
3
4
5
6
7
8
9
10
11
12//203行:
else if(scause == 0x8000000000000001L){
// software interrupt from a machine-mode timer interrupt,
// forwarded by timervec in kernelvec.S.
if(cpuid() == 0){ //207行
clockintr();
}
// acknowledge the software interrupt by clearing
// the SSIP bit in sip.
w_sip(r_sip() & ~2);
return 2;}1
2
3
4d 1 #删除断点
bt #查看调用栈
finish #返回上层调用usertrap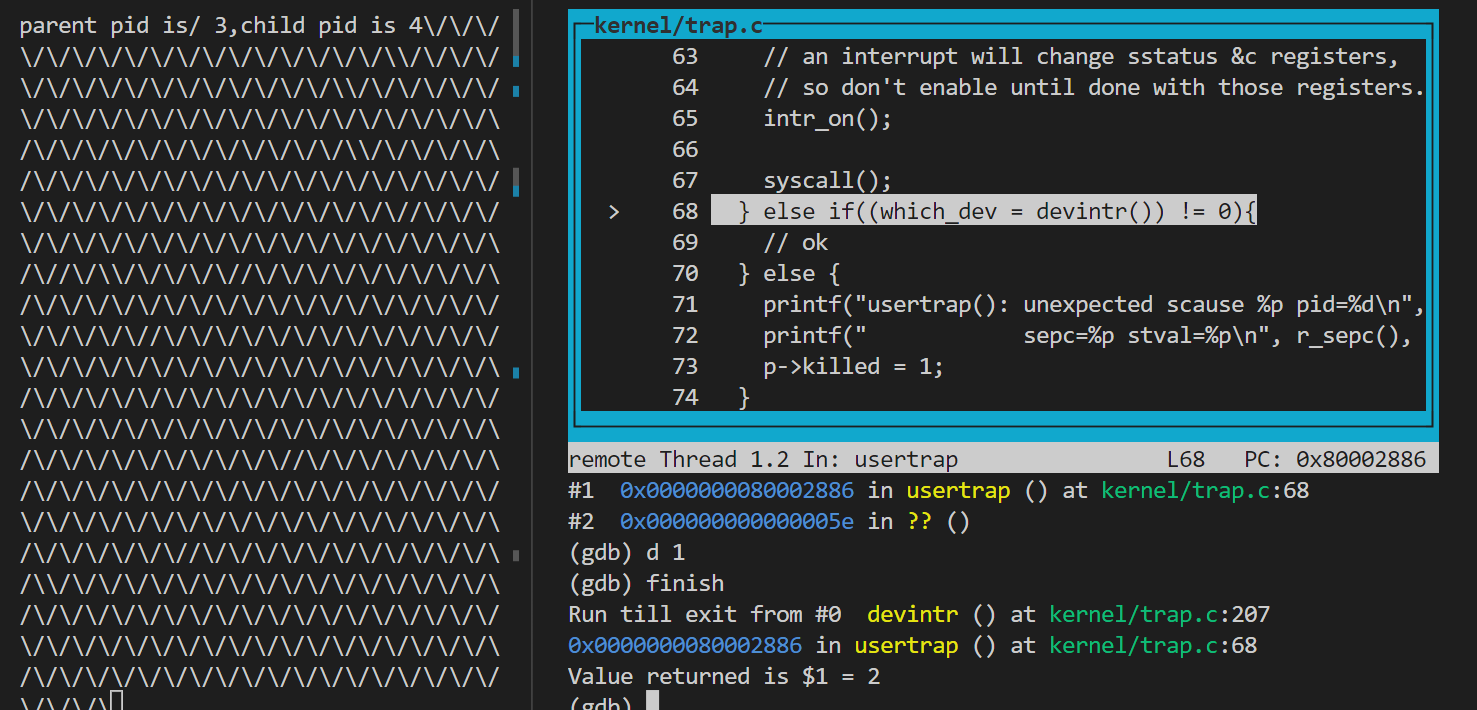 从返回值看确实返回了2,进入usertrap会执行
从返回值看确实返回了2,进入usertrap会执行 1
2if(which_dev == 2)
yield();
yield函数
yield获取锁,改变状态为RUNNABLE,执行sched函数,在进程持有锁的情况下,即使进程状态变成RUNNABLE,其他CPU也不能捕获这个进程并且运行,因此这里的锁是很必要的。
1
2
3
4
5
6
7
8
9void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock); //锁
p->state = RUNNABLE; //改变状态
sched();
release(&p->lock);
}
noff和intena字段是CPU重要的中断控制字段,进程调用push_off,noff字段计数会增加,代表中断嵌套深度增加,intena会自动记录嵌套增加前的CPU中断状态;而调用pop_off,noff计数减少,恢复intena字段的中断状态,只有嵌套为1层再启动中断时,中断才能被启动,因此如果控制不当,可能造成CPU中断无法启动,导致死锁的局面。
另一个问题是mycpu的context字段和myproc的context字段,都存储了上下文信息,主要mycpu的context特指的是CPU结构体维护的context字段,这个字段是调度器线程使用的,所谓调度线程,也是内核线程的一种,每个CPU只有一个调度线程;而后者字段是每个进程存储的上下文信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// Switch to scheduler. Must hold only p->lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->noff, but that would
// break in the few places where a lock is held but
// there's no process.
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock)) //确保持有锁
panic("sched p->lock");
if(mycpu()->noff != 1) //中断的嵌套只有1层,避免死锁
panic("sched locks");
if(p->state == RUNNING) //状态不能是正在运行
panic("sched running");
if(intr_get()) //返回1代表中断开启,0代表中断关闭
panic("sched interruptible");
intena = mycpu()->intena; //备份CPU中断状态
swtch(&p->context, &mycpu()->context); //交换上下文,备份进程p->context,恢复线程调度器的context
mycpu()->intena = intena; //恢复交换前的中断状态
}
swtch函数
swtch汇编代码中,a0代表第一个参数,a1代表第二个参数,sched调用时分别传参p->context和mycpu()->context,也即备份当前进程p的内核寄存器,恢复线程调度器的上下文,后续会执行线程调度器的进程。最后返回的是ret,将返回ra指向的地址,其中a0的ra为sched,因为swtch函数被sched调用;重新ld后ra变成a1的返回地址,即scheduler函数,可以通过gdb验证这点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
retswtch(&p->context, &mycpu()->context),运行
1
2
3
4
5
6
7p/x cpus[0].context #打印线程调度器的上下文
x/i 0x地址 #显示汇编指令
#额外用法:
#x/i $pc 当前汇编指令
#x/10i 0x地址 地址后10条指令
p/x $ra #打印当前进程ra 验证了我们刚刚的陈述。此外,还有两个问题需要注意(摘自课程):
验证了我们刚刚的陈述。此外,还有两个问题需要注意(摘自课程):
- 为什么内核没有保存pc程序指针的寄存器?
- 当前pc指向swtch函数调用,ra寄存器储存了返回地址,无论如何pc都会根据返回地址更新。
- 为什么内核只保存了14个寄存器,其他寄存器没有保存?
- 因为其中13个为Callee类型寄存器,ra为Caller寄存器但是存储返回地址信息,swtch被C代码调用,调用方默认调用会使寄存器变化,Caller寄存器会被调用方保存在栈上,函数调用返回自动恢复,所以其他Caller寄存器无需被保存。
pc指针无效,gdb也不会显示swtch内容,需要调用swtch需要设置断点:
1
2
3
4
5tbreak swtch #临时断点,触发一次即删除
si #单步执行到ret
p/x $ra
p/x $sp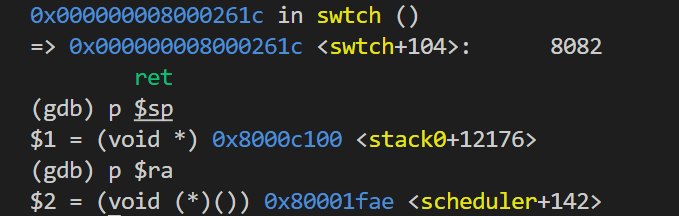 函数调用返回,就进入到线程调度器线程,注意这里的返回是scheduler函数的swtch函数返回的,sched调用的swtch还没有返回。sp现在处于内核栈stack0位置,线程调度器在这里运行。
函数调用返回,就进入到线程调度器线程,注意这里的返回是scheduler函数的swtch函数返回的,sched调用的swtch还没有返回。sp现在处于内核栈stack0位置,线程调度器在这里运行。
scheduler函数
如果你之前使用gdb,你对这个函数不会陌生,每次系统系统都会循环查找RUNABLE进程,这里不是讨论的核心,因为下一个环节不是这里;我们是从swtch返回的,这个swtch是什么时候调用的?是第一次运行spin(父子进程打印斜杠的应用名称)时;因此下面的操作是c->proc = 0,因为刚刚spin进程已经被切走了,将cpu的进程置0没有问题,然后我们释放了锁,这里的锁是yeild申请的,回顾一下,yeild为了防止将spin进程设置为RUNABLE就立刻被其他CPU捕获运行,导致数据保存不当,因此到这里才可以释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
int nproc = 0;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state != UNUSED) {
nproc++;
}
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
if(nproc <= 2) { // only init and sh exist
intr_on();
asm volatile("wfi");
}
}
}RUNABLE进程了,假设这里我们找到了还是spin,这时候的spin应该运行的是fork创建的子进程了,刚刚的是父进程,这里需要获取锁,防止调用swtch时寄存器未来得及恢复就被定时器中断等打断,导致数据不完整;然后又调用了swtch(&c->context, &p->context),装载子进程的上下文,最后返回到sched调用的swtch函数,恢复中断,返回yield释放锁,yield过程就完成了,trap.c的usertrap任务也处理完了,后续经过和系统调用基本相同的过程返回用户空间继续执行。
这里swtch的调用可能是多线程最让人困惑的地方,因为他的调用和返回不是在同一个函数完成的,简单来描述整个过程是:spin输入命令运行的父进程(swtch调用,pid=3),经过某段时间触发了定时器中断,发生陷入,ecall、uservec保存父进程用户寄存器到trapframe,然后进入trap.c的usertrap函数处理,这个函数会调用yield函数,yield函数获取锁,就调用swtch保存父进程内核的寄存器到context,进入调度器线程;调用返回的是proc.c的scheduler函数的swtch函数,切走cpu进程项置0,释放锁,然后重新查找RUNABLE进程,得到spin子进程(pid=4),获得锁、设置RUNING,调用swtch恢复子进程的上下文,又返回到sched调用的swtch函数(这是上次子进程调用的,不是父进程的sched),这时候我们已经又从调度器线程切换成了子进程的内核线程,随即释放scheduler申请的锁,此时内核寄存器已经是子进程的上下文了,通过后续的usertrapret、userret恢复子进程用户寄存器,返回用户空间继续执行子进程。
这里存在一个问题:假设系统刚刚启动,没有其他进程运行,第一个进程第一次运行调用proc.c的scheduler函数的swtch,那么按道理它应该会返回到这个进程之前在sched调用的swtch,但是作为第一个进程第一次运行,根本没有这个调用记录,所以要看xv6的处理方式,以下:
第一次调用scheduler的swtch返回
allocproc函数定义了 1
2
3memset(&p->context, 0, sizeof(p->context));
p->context.ra = (uint64)forkret; //第一次返回指针设置了forkret函数
p->context.sp = p->kstack + PGSIZE; 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
void
forkret(void)
{
static int first = 1;
// Still holding p->lock from scheduler.
release(&myproc()->lock);
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
first = 0;
fsinit(ROOTDEV);
}
usertrapret();
}scheduler获取锁,得到第一个RUNABLE进程,调用swtch会跳转到forkret函数,这个函数并不是什么功能函数,只是为了使得调度更具循环性,它释放锁就返回到用户空间了。对其他进程来说,调度时会把上下文存入context,因此尽管allocproc定义了这样的入口,也不会通过这种方式实现线程切换。
Lock锁
锁的诞生
二十年前单核CPU频率就进入缓慢增长的时代,如果想要对应用程序进行加速,一般是透过多核CPU的方式进行。多个CPU可能会同时访问共享内存,因此需要锁结构来确保数据安全性。
锁与性能
锁的一个矛盾是性能和并发的冲突,因为提高性能的并发性的需要,诞生了锁这种结构,但是锁的存在又反过来限制了性能。锁是为了避免race condition(竞争条件),所谓race condition就是没有加锁的非原子操作造成的冲突。锁的两个api分别是acquire和release,它们中间的代码通常被称为critical section。critical section作为原子操作,要么一起执行,要么不会执行。
锁的使用时机
锁的数量对系统也是有影响的,如果每个系统只有一把大锁big kernel lock,对程序员而言这是容易维护的,但是这牺牲了系统的性能和并发性,因为所有事情都需要等待这把大锁;因此一般系统都会包含若干的锁,保证一定的并发性;此外,锁的使用取决于设计者,不是所有的操作都适合加锁。
死锁
导致死锁的场景有很多;例如单核CPU下,一个进程acquire了锁,进程内又再次acquire锁,第二个锁需要第一个锁release才能继续执行,但是不能执行又走不到第一个锁的release,因此进程就永远卡死在这里了。xv6会检测同一个进程是否多次acquire了锁决定是否触发panic,这种机制有效地探测这种死锁;但是在一些多进程场景就比较难探测了,例如进程1完成一次操作需要获取一次a锁和b锁,与此同时进程2需要先后获取一次b锁和a锁,某个时间进程1获得了a锁等待b锁释放,同时进程2获得了b锁等待a锁释放,造成了循环等待死锁。
因此系统设计者需要对共享的锁进行全局排序,排序靠前的锁首先被获得,同时要考虑代码模块的抽象性,将一些模块内部不必要暴露的锁隐藏。
自旋锁(Spin Lock)
常用的锁有互斥锁(Mutex Lock)、自旋锁,其区别在于线程的处理方法有所不同。互斥锁是一种开销比较大的锁,当一个线程首先获得锁,另一个线程获取互斥锁失败,会陷入内核将线程状态更改成睡眠然后阻塞,并且切换上下文让出CPU给其他线程执行;而使用自旋锁,线程获取自旋锁失败会进入忙等待,本质就像在循环中等待锁释放,一般不会进入内核态,因此开销比较小,开销随着等待时间线性增加,适合短时间等待。自旋锁一般应用在多核CPU系统,因为使用自旋锁的线程不会主动放弃CPU,要么只能通过抢占式中断从自旋锁线程转到其他线程。
xv6使用的锁为自旋锁,自旋锁的实现一般依赖一些原子操作的硬件指令,保证所谓test-and-set的原子性。在xv6中这个特殊的指令是amoswap(atomic memory swap);这个指令接收三个参数,分别是地址address、寄存器r1、寄存器r2,操作是将address原始数据写入tmp变量,将r1数据写入地址,将tmp变量写入r2,最后对地址解锁;这一系列操作具有原子性,将软件锁变成硬件锁是自旋锁的一般实现方式,很多处理器都支持这种硬件操作;
1
2
3
4
5
6
7#riscv原子交换值:
try_lock:
AMOSWAP.W t0, t1, zero # t0获取内存锁的旧值,zero表示锁定状态
BNE t0, zero, try_lock # 如果 t0 不为零,表示锁已被占用,继续尝试
# 锁获取成功后,执行临界区代码
release_lock:
SW zero, 0(t1) # 将锁释放(置零)locked标志位置为1,release时会将其重新置为0;一个线程获取锁将标志位置1,其他线程就会轮询这个标志位是否被置0,否则会自旋等待。配合硬件原子指令,能够保证有且只有一个线程轮询得到标志位为0,不会同时有两个同时获得锁,具体实现是:
kernel/spinlock.h自旋锁结构体:包含了locked、锁名、持锁cpu编号的信息。
1
2
3
4
5
6
7
8// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
};kernel/spinlock.c定义了acquire、release的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// Acquire the lock.
// Loops (spins) until the lock is acquired.
void
acquire(struct spinlock *lk)
{
push_off(); // disable interrupts to avoid deadlock.
if(holding(lk))
panic("acquire");
// On RISC-V, sync_lock_test_and_set turns into an atomic swap:
// a5 = 1
// s1 = &lk->locked
// amoswap.w.aq a5, a5, (s1)
while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
;
// Tell the C compiler and the processor to not move loads or stores
// past this point, to ensure that the critical section's memory
// references happen strictly after the lock is acquired.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Record info about lock acquisition for holding() and debugging.
lk->cpu = mycpu();
}__sync_lock_test_and_set是一个原子操作,原理就是通过amoswap指令实现,在kernel.asm代码中可以找到如下片段:
1
2
3
4
5while(__sync_lock_test_and_set(&lk->locked, 1) != 0)
80000c9a: 87ba mv a5,a4
80000c9c: 0cf4a7af amoswap.w.aq a5,a5,(s1)
80000ca0: 2781 sext.w a5,a5
80000ca2: f7f5 bnez a5,80000c8e <acquire+0x42>locked字段为0,会向locked字段写入1,并且返回之前的字段0代表没有持锁,跳出循环;如果locked字段为1,那么会向locked字段写入1,字段没有改变返回1代表别的线程早已经持锁,此时不会跳出循环,直到返回0字段,这就是acquire的实现;后续的__sync_synchronize是一个内存屏障,它确保某个内存指令前的操作被执行完才会继续执行,防止编译器、处理器对内存进行重排,确保锁的顺序对各个线程是一致的。
release函数: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// Release the lock.
void
release(struct spinlock *lk)
{
if(!holding(lk)) //没有持锁报错
panic("release");
lk->cpu = 0;
// Tell the C compiler and the CPU to not move loads or stores
// past this point, to ensure that all the stores in the critical
// section are visible to other CPUs before the lock is released,
// and that loads in the critical section occur strictly before
// the lock is released.
// On RISC-V, this emits a fence instruction.
__sync_synchronize();
// Release the lock, equivalent to lk->locked = 0.
// This code doesn't use a C assignment, since the C standard
// implies that an assignment might be implemented with
// multiple store instructions.
// On RISC-V, sync_lock_release turns into an atomic swap:
// s1 = &lk->locked
// amoswap.w zero, zero, (s1)
__sync_lock_release(&lk->locked);
pop_off();
}__sync_lock_release(&lk->locked)也是一个原子操作,它将0写入locked字段;
1
2
3__sync_lock_release(&lk->locked);
80000d3a: 0f50000f fence iorw,ow
80000d3e: 0804a02f amoswap.w zero,zero,(s1)
文件系统File Systems
同虚拟内存类似,文件系统的设计牵涉到很多别出心裁的设计,除了理解文件系统的内容,也要横向联系虚拟内存、锁等系统特性,在Lab中也会有相似的体现。
文件系统概述
一些文件系统背后的机制是有趣的,例如:
文件系统如何对硬件进行抽象,作为操作系统的一部分,它向上层的应用层提供了什么样的接口?
它如何实现Crash Safety?所谓Crash Safety,也即计算机崩溃再重启的时候,文件系统的数据仍然存在,你依然可以使用大部分的文件。
文件系统在磁盘上的布局数据结构、铺排是如何的?
文件系统的性能如何保证?例如磁盘是一种低速设备,如何避免和磁盘过多地交互,文件操作的并发如何进行?
在xv6中,文件系统被简化成七层结构,从下至上分为磁盘(Disk)、缓冲区高速缓存(Buffer cache)、日志(Logging)、索引结点(Inode)、目录(Directory)、路径名(Pathname)、文件描述符(File descriptor)
磁盘层
作为最底层的部分,目前常用的磁盘有HDD(机械硬盘)和SSD(固态硬盘),前者读写一个block时间量级在10ms左右,后者通常是在0.1到1ms左右;磁盘读写的基本单位是扇区(sector),通常是512字节;在xv6的文件系统描述,另一种描述读写的单位是块(block),它的大小由操作系统定义,在xv6中对应1024字节,也即两个扇区;在其他一些操作系统描述中也有将扇区术语等同于块的。
SSD和HDD的工作方式是大为不同的,但是操作系统会屏蔽这些硬件的差异,使用标准的通信协议,例如PCIE和磁盘进行交互,从驱动上层的角度看,编程方式的大体相同的,通过read/write接口以及block编号,读写设备的控制寄存器完成相关操作。
xv6在外存的布局如下: 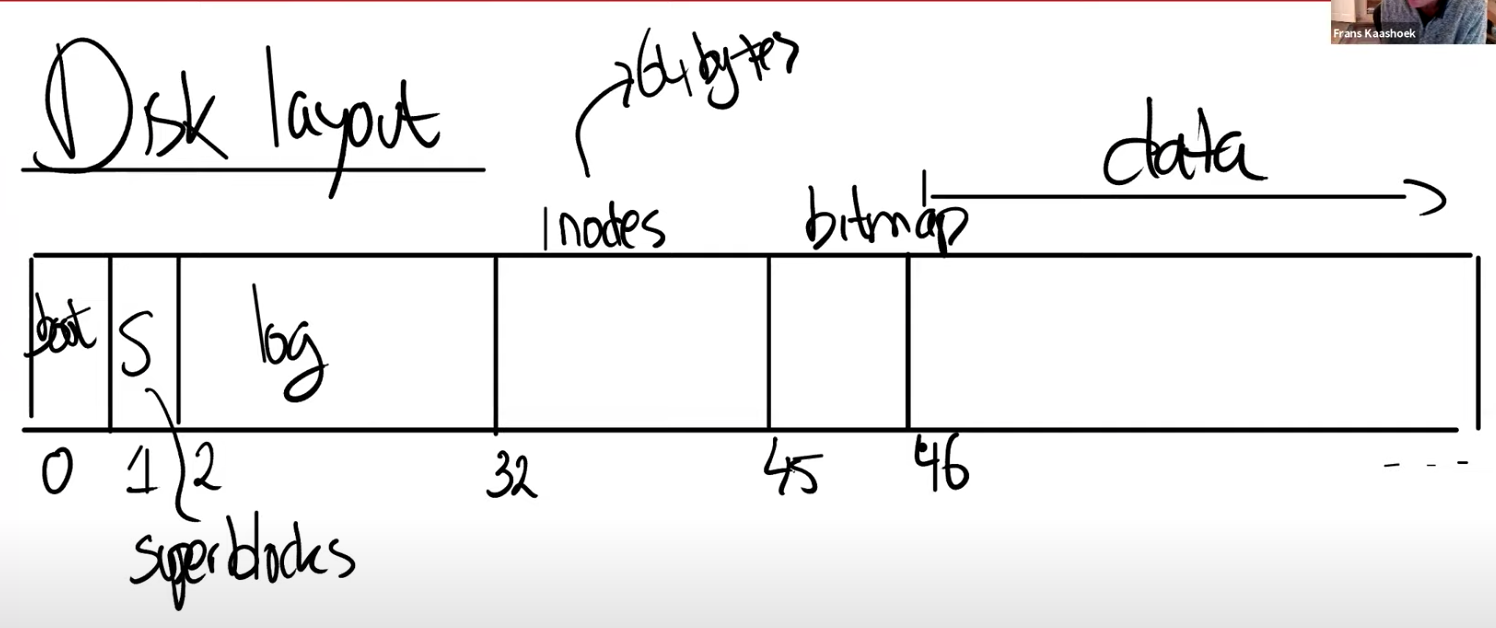
块0(boot sector):作为启动引导扇区用于启动操作系统;但是我们的xv6运行在qemu之上,因此它没有像物理机启动一样从这块内存读取扇区,而只是向虚拟机发送了指令并且运行;
块1(super block):超级块,描述了文件系统的重要信息;定义了块的分布、块数量等;
log(块2-块31):日志层是实现
Crash Recovery的重要依赖层,后面会详细介绍,log层占30个block;inode(块32-块44):存储inode,多个inode会打包存放在一个block中,一个inode为64字节(指的是dinode),inode占13个块;
Bit Map块(块45):位图块,跟踪正在使用的数据块;
数据块(块46-磁盘末尾块999):存储了文件的内容和目录内容;占954个Blocks;
在xv6中inode块前占了0-31共32块,因此如果需要通过inode获取内存块编号,为32+inode*64/1024(仅适用于直接Inode);
Buffer cache层
代码在bio.c中。Buffer cache有两个任务:
同步对磁盘块的访问,以确保磁盘块在内存中只有一个副本,并且一次只有一个内核线程使用该副本。
缓存常用块,以便不需要从慢速磁盘重新读取它们。
Buffer
cache层导出的主接口主要是bread和bwrite;bread从磁盘读取一个块,返回一个上锁的缓冲区,内存可以对这个缓冲区进行读取,或者修改这个块的副本,再调用bwrite将该块的修改更新回磁盘对应的块。Buffer
cache每个缓冲区使用一个睡眠锁,确保每个缓冲区(也是每个磁盘块)只能被一个内核线程访问,需要调用brelse释放该锁。xv6缓冲区的数量是固定的,如果有新块加入而且没有空闲的缓冲区,会采取最近最少使用策略(LRU)将缓冲区换出给新块使用。
Buffer cache代码剖析
这个层次和Lab 9的Lock实验相关,因此了解相关的代码结构是必要的。
Buffer结构
先看一些缓冲块结构体维护了什么数据,代码在kernel/buf.h,首先这里特殊的是“睡眠锁”。睡眠锁是一种轻量的锁,与自旋锁(spinlock)相比,它不会自旋等待,而是使进程睡眠等待锁的释放,另一方面,它获取锁的时候不会关闭CPU中断。因为获取spinlock关闭中断,去进行磁盘操作,意味着CPU无法获得磁盘中断,也无法释放锁,在单核CPU机器就会导致死锁,所以,睡眠锁适用于单核CPU的内核编程,自旋锁一般用于多线程编程。
prev和next是双向链表的指针结构,LRU代表换出最近最少使用的缓存块,后面将看到具体操作。
1
2
3
4
5
6
7
8
9
10
11struct buf {
int valid; // has data been read from disk? 是否已经读入缓存块?
int disk; // does disk "own" buf? 缓存块是否写入了磁盘?
uint dev; //设备号(不同的磁盘设备号不同)
uint blockno; //磁盘的块号
struct sleeplock lock; //睡眠锁
uint refcnt; //缓存块的引用计数
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE]; //BSIZE=1024,即xv6一个块的大小,代表一个缓存块的数据data
};
binit函数
缓存块的管理是一种双向循环链表结构,bcache结构由头结点head和缓存数组组成,其中buf结构体是一种含有prev和next指针的双向结点,在链表结构中,头结点head的next指针始终指向最近插入的结点,prev指针始终指向最近最长时间未使用的结点(第一个插入的数据节点)。
双向循环链表的插入采取的是头插法,bcache.head.next->prev = b这一句的作用,当没有数据结点时,它会将头结点的prev指向插入的数据结点(所以头结点的prev是不会因为插入新元素更新的),当有数据结点时,会将最近插入结点的prev指针指向新插入结点,bcache.head.next = b将头结点next指针更新到新插入结点,其他代码也就不难看懂了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28struct {
struct spinlock lock; //自旋锁
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct buf head;
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
bget函数
bget函数用于遍历链表,查找某个磁盘的块号是否已经存入缓存块,如果存在则返回一个持有睡眠锁的缓存块,如果不存在则从head->prev反向遍历,寻找refcnt引用数等于0的缓存块分配给这个磁盘块号,并返回(但bget没有定义如果缓存块不存在且没有缓存块引用数为0的具体操作,按道理应该是将head->prev置换出去),这个函数的自旋锁仅为了保证缓存块计数是单线程的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
bread、bwrite函数
bread用于将磁盘数据读入缓存块,bwrite用于将缓存块数据更新到磁盘。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno); //获取磁盘对应的缓存块
if(!b->valid) {
virtio_disk_rw(b, 0); //将磁盘数据读入缓存块,0代表读操作
b->valid = 1; //标记读入
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1); //将缓存块数据写回磁盘,1代表写操作
}
brelse函数
调用brelse接口,会将该缓存块引用数减一,代表某个进程不再使用这个缓存块进行磁盘读写,如果一个缓存块的引用数降到0,会将其重新插入到双向链表的头结点的后面,代表这个缓存块可以被其他新的磁盘块占用(xv6缓存块数量是固定的,不会释放空间)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev; //取消原来的插入位置,将b孤立出来
b->prev->next = b->next;
b->next = bcache.head.next; //头插法,将b插入头结点之后
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock);
}
计数函数bpin、bunpin
增加、减少缓存块引用计数;
1
2
3
4
5
6
7
8
9
10
11
12
13void
bpin(struct buf *b) {
acquire(&bcache.lock);
b->refcnt++;
release(&bcache.lock);
}
void
bunpin(struct buf *b) {
acquire(&bcache.lock);
b->refcnt--;
release(&bcache.lock);
}
inode层
inode结构体占64个字节(uint、int占4字节,short占2字节)
1
2
3
4
5
6
7
8
9
10
11
12
13
14struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count,这是在文件系统中文件的引用计数
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?(是否读入内存)
short type; //目录还是文件
short major; //主设备号
short minor; //次设备号
short nlink; //硬链接计数,多少文件指向当前inode
uint size; //文件大小
uint addrs[NDIRECT+1]; //NDIRECT=12,
};ref和nlink字段,nlink是dinode也有的字段,代表在磁盘存储中,同一份文件有多少硬链接的数量,例如磁盘存储的a和b都指向了inode;而ref字段是内存中inode的引用数,例如进程a和进程b都对inode进行操作,都会增加它的引用数。
这里与inode紧密相关的是addrs,它是一个连续存储的数组,存储了13个Block编号(每个4字节(uint))。xv6的inode有12个block的编号(block0~block11),这十二个编号被称为Direct Block Number,它对应了文件的前十二个block,也即12*1024的空间。紧接着还有一个Inderect Block Number,它指向磁盘的另一个block,存储了256个block
number,这256个block num本身也指向了block,它们是文件数据。 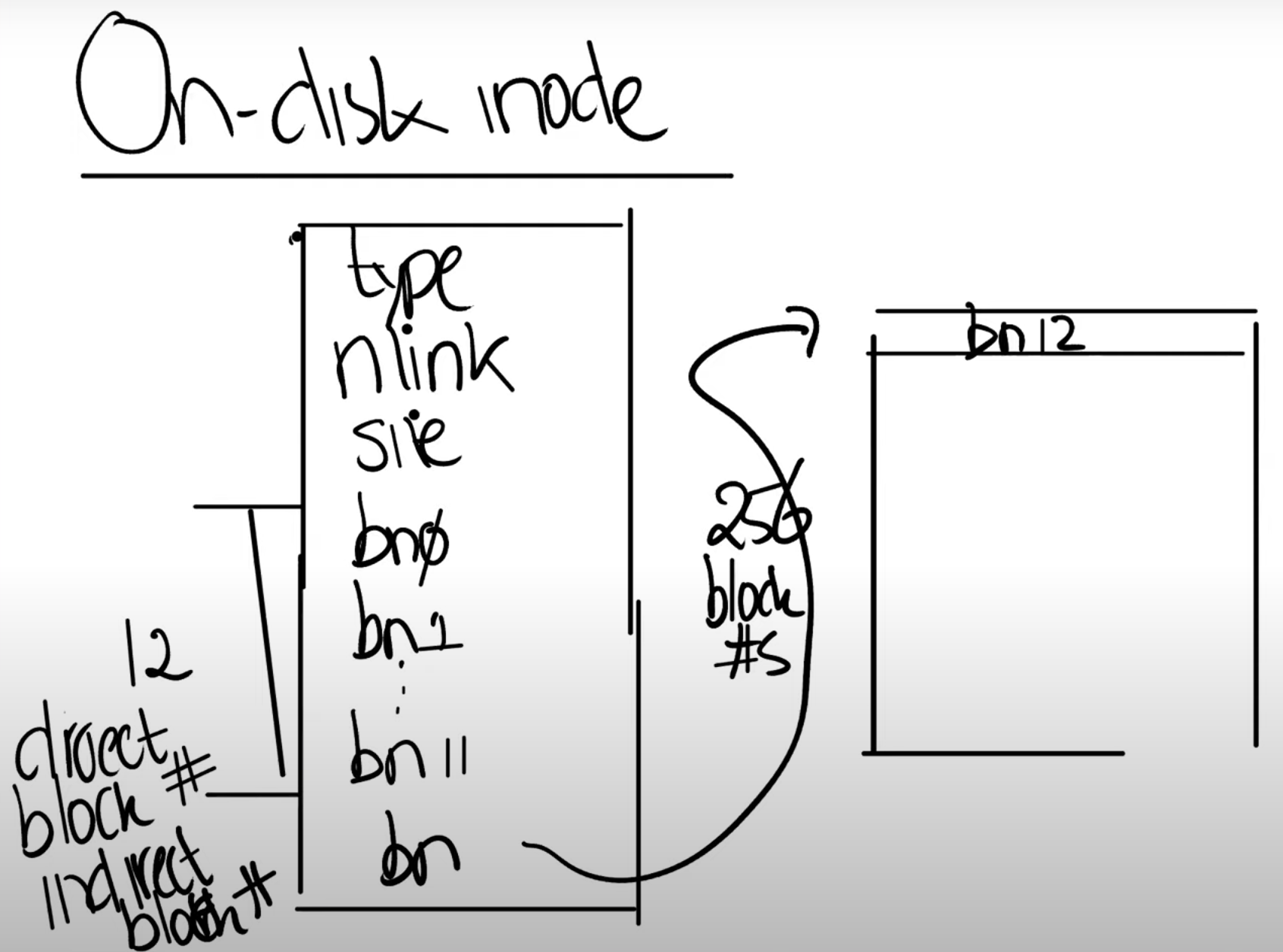 不难计算,xv6支持的最大文件长度为(12+256)*1024字节;为了扩展xv6最大支持的文件长度,我们在文件系统的Lab会使用双重的Indirect
Block
Number实现更大的文件,原理就和页表的离散存储基本一致。其次,每个Block
Num定义成32位(4字节),意味着磁盘最大空间是
不难计算,xv6支持的最大文件长度为(12+256)*1024字节;为了扩展xv6最大支持的文件长度,我们在文件系统的Lab会使用双重的Indirect
Block
Number实现更大的文件,原理就和页表的离散存储基本一致。其次,每个Block
Num定义成32位(4字节),意味着磁盘最大空间是
inode结构提供了文件read/write的必要信息,read、write系统调用以某种隐式方式告诉内核读写的起始地址(系统追踪而知)以及读写大小(参数),例如内核获知现在需要读写某个文件的8000字节的位置,那么文件系统会将8000/12,向下取整得Block 7包含这个位置的数据,Block 7的起始字节是7*1024=7168,因此读写Block位置在Block 7的832字节偏移位置,这就是我们需要的文件数据位置。
接下来讨论读取目录索引文件的例子:目录本质是文件+特殊数据结构,对xv6而言这种数据结构是16字节的目录条目(Directory Entry),前两个字节是目录中子目录或者目录文件的inode编号;后14字节是子目录名称或者目录文件名称。
假设我们现在需要查找/y/x文件,首先从root inode出发(root inode是inode区编号为1的inode),然后读取root inode的13个Block Number对应的Block以查找y对应的inode,假设找到y对应的inode为251(inode区或Indirect Number=251,目录的Entry前两字节=251),那么就跳转到该inode继续读取该条目,索引y inode下的x文件,最后返回结果。
在写这里的时候,我刚开始不太能理解为什么inode可以是251,因为inode区就占13块(13*1024字节),每个inode占64字节(指的是dinode),最大inode也是208。这其实正是Indirect Block Number的作用,每个inode的第13个Indirect Block Number还能指向更大的inode,因此编号自然会大于208。越多级的Indirect,能支持的inode越大,尽管是对Linux而言,仍然存在inode分配完、但是外存没有使用完的情况,这时候也会无法新建文件。
xv6文件系统运行逻辑
剩下的log层主要用于Crash Recovery,xv6没有很复杂的机制也没有设计相关的实验,因此后面再提,有机会看论文结合更复杂的Linux机制一起学习一下。这里记录一下xv6文件组织方式,并对相关代码进行剖析,对理解Lab10的file
system可能会有帮助。
echo "hi" > x
echo实现源码在user/echo.c,重定向">"在user/sh.c定义,这里只关心echo即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int
main(int argc, char *argv[])
{
int i;
for(i = 1; i < argc; i++){
write(1, argv[i], strlen(argv[i]));
if(i + 1 < argc){ //代表后面还有参数,以单个空格分开(尽管输入参数之间有很多空格)
write(1, " ", 1);
} else { //到达末尾
write(1, "\n", 1);
}
}
exit(0);
}
1
2
3
4
5write 33 #标识文件x inode的type字段,为文件
write 33 #填充文件x inode的其他字段
write 46 #根目录数据增加Entry条目,包括文件x的inode编号和文件名x
write 32 #根inode变更,因为目录大小等信息改变
write 33 #再次更新inode
将"hi"写入文件x;
1
2
3
4write 45 #bitmap区,声明某个数据块被使用设置成1,这个就是595数据块
write 595 #写入h
write 595 #写入i
write 33 #更新文件x的inode,新增了字符size字段要相应更新将换行符写入文件x;
1
2write 595 #写入换行符
write 33 #更新文件x的inode
文件系统相关代码
相关代码存于kernel/file.c、kernel/sysfile.c、kernel/fs.c。
file.h&file.c
长文预警警告:全部注释均为原创,一次性看五十几个函数是很折磨且头脑发热的事情,因此并不保证我的思路完全正确,请读者参考时加以甄别,如若出错请酌情提醒。
file.h
声明了文件结构体、inode结构体、设备读写结构体以及一些用到的宏;inode结构体在前文已经描述,这里不再赘述,宏在使用的地方再相应描述。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct file {
enum { FD_NONE, FD_PIPE, FD_INODE, FD_DEVICE } type; //四种文件类型:未定义类型、管道类型、普通文件/目录、设备文件
int ref; //文件的引用数
char readable;
char writable;
struct pipe *pipe; // FD_PIPE,管道文件指针
struct inode *ip; // FD_INODE and FD_DEVICE,普通文件/目录/设备文件指针
uint off; // FD_INODE,普通文件/目录偏移量
short major; // FD_DEVICE,主设备号
};
struct devsw { //设备驱动读写函数指针;
int (*read)(int, uint64, int);
int (*write)(int, uint64, int);
};
结构体、fileinit
1 | struct devsw devsw[NDEV]; //主设备驱动,最多为NDEV=10; |
filealloc
返回一个分配好的文件结构体指针,分配操作仅是将引用数置1;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// Allocate a file structure.
struct file*
filealloc(void)
{
struct file *f;
acquire(&ftable.lock);
for(f = ftable.file; f < ftable.file + NFILE; f++){
if(f->ref == 0){
f->ref = 1;
release(&ftable.lock);
return f;
}
}
release(&ftable.lock);
return 0;
}
filedup
filedup将非零引用数的文件引用数加一; 1
2
3
4
5
6
7
8
9
10
11// Increment ref count for file f.
struct file*
filedup(struct file *f)
{
acquire(&ftable.lock);
if(f->ref < 1)
panic("filedup");
f->ref++;
release(&ftable.lock);
return f;
}
fileclose
fileclose用于安全地关闭一个文件,减少文件引用数,如果降为0则分管道文件关闭和普通/设备文件关闭,前者使用管道库函数关闭读写两端的文件描述符,后者需要减少inode引用数,若降为0会回收相应的inode空间;begin_op在文件操作前需要调用,代表将某个操作写入log层,防止文件操作进行一半系统崩溃,导致文件系统不再可用,end_op在文件操作后调用,代表该操作已经安全完成,log层无需再追踪;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Close file f. (Decrement ref count, close when reaches 0.)
void
fileclose(struct file *f)
{
struct file ff;
acquire(&ftable.lock);
if(f->ref < 1)
panic("fileclose");
if(--f->ref > 0){
release(&ftable.lock);
return;
}
//引用数为0执行以下操作
ff = *f;
f->ref = 0; //引用数归0
f->type = FD_NONE; //文件类型置NONE
release(&ftable.lock);
if(ff.type == FD_PIPE){ //管道文件
pipeclose(ff.pipe, ff.writable); //管道关闭
} else if(ff.type == FD_INODE || ff.type == FD_DEVICE){ //普通文件/目录、设备文件
begin_op(); //日志记录
iput(ff.ip); //inode引用数减1,降为0回收inode,详见后文fs.c
end_op(); //提交记录
}
}
filestat
filestat是用户空间接口,接收文件结构体指针和用户空间虚拟地址(用户命名的变量地址),内核会调用stati将inode结点的信息填充到stat结构体,包括文件设备号、inode号、目录/文件、inode引用数、inode大小,拷贝这个结构体到用户虚拟地址空间中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Get metadata about file f.
// addr is a user virtual address, pointing to a struct stat.
int
filestat(struct file *f, uint64 addr)
{
struct proc *p = myproc();
struct stat st;
if(f->type == FD_INODE || f->type == FD_DEVICE){
ilock(f->ip);
stati(f->ip, &st);
iunlock(f->ip);
if(copyout(p->pagetable, addr, (char *)&st, sizeof(st)) < 0)
return -1;
return 0;
}
return -1;
}
//其中
struct stat {
int dev; // File system's disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
fileread
用户接口函数,从文件描述符f读取n个字节数据到addr,读方法分管道、设备、普通文件,它们都调用了copyout将内核读取的内容复制到用户虚拟空间addr;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// Read from file f.
// addr is a user virtual address.
int
fileread(struct file *f, uint64 addr, int n)
{
int r = 0;
if(f->readable == 0)
return -1;
if(f->type == FD_PIPE){
r = piperead(f->pipe, addr, n); //管道读
} else if(f->type == FD_DEVICE){
if(f->major < 0 || f->major >= NDEV || !devsw[f->major].read)
return -1;
r = devsw[f->major].read(1, addr, n); //设备读,对应函数指针,1代表addr是用户空间虚拟地址
} else if(f->type == FD_INODE){
ilock(f->ip);
if((r = readi(f->ip, 1, addr, f->off, n)) > 0) //ip是inode指针,1代表addr是用户空间虚拟地址,普通文件使用off计算文件读写偏移量(inode能定位起始地址);
f->off += r;
iunlock(f->ip);
} else {
panic("fileread");
}
return r;
}
filewrite
设备写、管道写都和读操作调用差不多,它们都调用copyin将用户虚拟地址数据写入文件;这里写普通文件/目录有点不一样,一次不能写入很长的数据,因为大操作无法同步到log层,因此这里设定了max = ((MAXOPBLOCKS-1-1-2) / 2) * BSIZE,其中MAXOPBLOCKS=10,除去1个块留给inode更新、1个块留给间接inode,2个块用于系统块对齐,除以二确保单次写入足够安全(猜的,乘以BSIZE(1024字节)即Block的大小,max就是单次写入的最大字节数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50// Write to file f.
// addr is a user virtual address.
int
filewrite(struct file *f, uint64 addr, int n)
{
int r, ret = 0;
if(f->writable == 0)
return -1;
if(f->type == FD_PIPE){
ret = pipewrite(f->pipe, addr, n);
} else if(f->type == FD_DEVICE){
if(f->major < 0 || f->major >= NDEV || !devsw[f->major].write)
return -1;
ret = devsw[f->major].write(1, addr, n);
} else if(f->type == FD_INODE){
// write a few blocks at a time to avoid exceeding
// the maximum log transaction size, including
// i-node, indirect block, allocation blocks,
// and 2 blocks of slop for non-aligned writes.
// this really belongs lower down, since writei()
// might be writing a device like the console.
int max = ((MAXOPBLOCKS-1-1-2) / 2) * BSIZE;
int i = 0;
while(i < n){
int n1 = n - i;
if(n1 > max)
n1 = max;
begin_op();
ilock(f->ip);
if ((r = writei(f->ip, 1, addr + i, f->off, n1)) > 0)
f->off += r;
iunlock(f->ip);
end_op();
if(r != n1){
// error from writei
break;
}
i += r;
}
ret = (i == n ? n : -1); //逻辑表达式再次判断是否成功写入n字节
} else {
panic("filewrite");
}
return ret;
}
fs.h&fs.c
定义了文件系统块、inode的操作,它们被文件系统更高层的调用例如sysfile等调用,子模块也比较多。
fs.h
fs.h定义了一些结构体:
超级块定义了块数、inode块、log块的数量以及相应的起始number,特殊的是一个magic,这个字段是特殊的常数,被用于区分不同的文件系统,例如Linux的ext3、ext4,Windows的NTFS、U盘的Fat32都是不同的文件系统;
dinode和inode有着相似的结构体内容,后者多了dev、inum、lock等字段,这是因为dinode描述的是磁盘的inode物理分布,而inode结构体是为了描述磁盘而存于内存中的,可以看成是一种逻辑分布,需要额外的字段便于系统对齐进行管理和控制。
dirent就是目录条目,2字节的inode号和14字节的文件名;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27//超级块
struct superblock {
uint magic; // Must be FSMAGIC
uint size; // Size of file system image (blocks)
uint nblocks; // Number of data blocks
uint ninodes; // Number of inodes.
uint nlog; // Number of log blocks
uint logstart; // Block number of first log block
uint inodestart; // Block number of first inode block
uint bmapstart; // Block number of first free map block
};
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
struct dirent {
ushort inum;
char name[DIRSIZ];
};
块操作函数
readsb
readsb读取dev磁盘块号为1的数据(超级块数据),并且填充superblock结构体;
1
2
3
4
5
6
7
8
9
10
11
12
13
14// there should be one superblock per disk device, but we run with
// only one device
struct superblock sb;
// Read the super block.
static void
readsb(int dev, struct superblock *sb)
{
struct buf *bp;
bp = bread(dev, 1); //bread从设备dev的1号块(superblock)读取缓存块内容
memmove(sb, bp->data, sizeof(*sb)); //填入超级块结构体,大小4字节
brelse(bp);
}
fsinit
文件系统初始化,检查magic字段是否为系统支持的文件系统,initlog从log层恢复上次崩溃的文件系统;
1
2
3
4
5
6
7
8// Init fs
void
fsinit(int dev) {
readsb(dev, &sb);
if(sb.magic != FSMAGIC)
panic("invalid file system");
initlog(dev, &sb);
}
bzero
将磁盘块读取到缓存块,将一个块数据清零置空; 1
2
3
4
5
6
7
8
9
10
11// Zero a block.
static void
bzero(int dev, int bno)
{
struct buf *bp;
bp = bread(dev, bno);
memset(bp->data, 0, BSIZE);
log_write(bp);
brelse(bp);
}
离了个大谱balloc函数
位图区通过0和1标记一个块对应的位,来标志这个块是否空闲;因此分配一个块的操作就是检查位图块对应的位是否为0,将其置1并且将对应的数据块清0返回;
这个函数实现我看得是有点迷,主要困惑(已解决)的地方是:
假设
sb.bmapstart被解析为位图区的块号起始,即45,那么BBLOCK(b, sb)宏代表的是对应的数据块,例如块48=45+3,对应第三个数据块;bp就变成读取数据块了,bzero(dev, b + bi)的b + bi既非块号,它清零的位置对应哪里呢?假设
sb.bmapstart被解析成位数,BBLOCK(b, sb)对应的确实是第b/BPB个块对应的位,bread接收的是块号参数,为什么传入了位偏移;sb.size代表是"Size of file system image (blocks)",我的理解是系统的总块数,即1000个块,外层循环b = 0; b < sb.size; b += BPB,b每次递增BPB个位,为什么和块数相比。最后的返回值应当返回空数据块的块号,b和bi显然都是位数,为什么能直接返回?
这些问题硬控了我几个小时,任何一条它们都不应该使内核正常工作,很粗暴的看法是b是块号,bi是位号,但是这个实在无法让人从代码而言解释得通,后面我想到一个很离谱,但是很合理的解释:首先要肯定这4条问题都是合理的,因为在当前系统中,b不可能大于块数sb.size,所以这个函数,b只有一种可能,等于0;
b=0,说明外层循环只会进入一次,BBLOCK(b,
sb)完全就是sb.bmapstart,也即内核定义的唯一一个位图块,bp读取的是位图块,bi < BPB && b + bi < sb.size成立的只有bi < sb.size,也即bi只会小于1000,因为内核本身只有1000个块,此时bi恰好就是对应第bi个数据块,返回的也是bi,对应数据块号。
我令sb.size等于1,它通过了所有usertests。假设这个猜想是合理的,很难想明白源码为什么会有这种写法,从逻辑而言它没有符合xv6布局的拓展特性,合理的解释只能是设计者从别的设计角度(例如多个bitmap块)转过来,而没有完全删改源码。
一天后更新:破案了,xv6在Lab
file_system确实重新定义了xv6的磁盘布局,包括70个元数据块(boot、super、30
log、13 inode 、25
bitmap)、199930个数据块,对于原来的布局(即只有一个bitmap),上述b=0的解释是合理的;而新布局我们需要结合循环来解释四个问题,首先现在sb.size=2000000,所以使用了25个bitmap区(共204800位)来记录199930个数据块的位图,因此bp = bread(dev, BBLOCK(b, sb))能够得到对应的位图块,此时的b + bi既是位数,也是块号(因为它真的有那么多块),每次外层循环,都会先分配1024×8个块,内层循环则是分配1个块;至此所有的困惑就解开了,但标题也不改了,这个问题还是有意思的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// Blocks.
// Allocate a zeroed disk block.
static uint
balloc(uint dev)
{
int b, bi, m;
struct buf *bp;
bp = 0;
for(b = 0; b < sb.size; b += BPB){ //其中struct superblock sb;
bp = bread(dev, BBLOCK(b, sb));
for(bi = 0; bi < BPB && b + bi < sb.size; bi++){
m = 1 << (bi % 8);
if((bp->data[bi/8] & m) == 0){ // Is block free?
bp->data[bi/8] |= m; // Mark block in use.
log_write(bp);
brelse(bp);
bzero(dev, b + bi);
return b + bi;
}
}
brelse(bp);
}
panic("balloc: out of blocks");
}
离了个小谱bfree函数
对应bfree函数,BBLOCK(b, sb)=((b)/BPB + sb.bmapstart)对xv6(bitmap只有一个区)而言只有一种结果,块号b取值为0到999,因此(b)/BPB=0;所以宏只能是sb.bmapstart即对应块45,b%BPB,对应b=bi块号,因此bfree读取bitmap区,将bi块位图的位置为空闲即释放了块给其他进程使用。
一天后更新:bitmap区有25个时,BBLOCK(b, sb)=((b)/BPB + sb.bmapstart)能够读取块号b所在的位图区,因此能够对应将位图的位置0;你不离谱,我离谱;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// Free a disk block.
static void
bfree(int dev, uint b)
{
struct buf *bp;
int bi, m;
bp = bread(dev, BBLOCK(b, sb));
bi = b % BPB;
m = 1 << (bi % 8);
if((bp->data[bi/8] & m) == 0)
panic("freeing free block");
bp->data[bi/8] &= ~m;
log_write(bp);
brelse(bp);
}
inode操作函数
iinit
每次从磁盘读取dinode代价太大,内存维护了icache,用于缓存最近访问的inode;在inode层设计的两个inode结构体是inode和dinode,inode结构体存在于icache中,我们存储磁盘的物理分布是dinode,注意dinode本身不是在磁盘中,我们铭记磁盘层已经被bcache给隔离开了,因此dinode存储在bcache中,它实际是通过访问buf的data从而访问磁盘的dinode块,既然dinode本身就通过bcache抽象在buf中,为什么还要抽象出icache呢?因为这种抽象更有利于管理和性能提高,例如icache维护了自己的锁,进行文件系统并发时,就不用和bcache去竞争bcache的锁了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83// Inodes.
//
// An inode describes a single unnamed file.
// The inode disk structure holds metadata: the file's type,
// its size, the number of links referring to it, and the
// list of blocks holding the file's content.
//
// The inodes are laid out sequentially on disk at
// sb.startinode. Each inode has a number, indicating its
// position on the disk.
//
// The kernel keeps a cache of in-use inodes in memory
// to provide a place for synchronizing access
// to inodes used by multiple processes. The cached
// inodes include book-keeping information that is
// not stored on disk: ip->ref and ip->valid.
//
// An inode and its in-memory representation go through a
// sequence of states before they can be used by the
// rest of the file system code.
//
// * Allocation: an inode is allocated if its type (on disk)
// is non-zero. ialloc() allocates, and iput() frees if
// the reference and link counts have fallen to zero.
//
// * Referencing in cache: an entry in the inode cache
// is free if ip->ref is zero. Otherwise ip->ref tracks
// the number of in-memory pointers to the entry (open
// files and current directories). iget() finds or
// creates a cache entry and increments its ref; iput()
// decrements ref.
//
// * Valid: the information (type, size, &c) in an inode
// cache entry is only correct when ip->valid is 1.
// ilock() reads the inode from
// the disk and sets ip->valid, while iput() clears
// ip->valid if ip->ref has fallen to zero.
//
// * Locked: file system code may only examine and modify
// the information in an inode and its content if it
// has first locked the inode.
//
// Thus a typical sequence is:
// ip = iget(dev, inum)
// ilock(ip)
// ... examine and modify ip->xxx ...
// iunlock(ip)
// iput(ip)
//
// ilock() is separate from iget() so that system calls can
// get a long-term reference to an inode (as for an open file)
// and only lock it for short periods (e.g., in read()).
// The separation also helps avoid deadlock and races during
// pathname lookup. iget() increments ip->ref so that the inode
// stays cached and pointers to it remain valid.
//
// Many internal file system functions expect the caller to
// have locked the inodes involved; this lets callers create
// multi-step atomic operations.
//
// The icache.lock spin-lock protects the allocation of icache
// entries. Since ip->ref indicates whether an entry is free,
// and ip->dev and ip->inum indicate which i-node an entry
// holds, one must hold icache.lock while using any of those fields.
//
// An ip->lock sleep-lock protects all ip-> fields other than ref,
// dev, and inum. One must hold ip->lock in order to
// read or write that inode's ip->valid, ip->size, ip->type, &c.
struct {
struct spinlock lock;
struct inode inode[NINODE]; //NINODE=50,inode最大缓存数
} icache;
void
iinit() //初始化icache锁,初始化缓冲区的inode的锁
{
int i = 0;
initlock(&icache.lock, "icache");
for(i = 0; i < NINODE; i++) {
initsleeplock(&icache.inode[i].lock, "inode");
}
}
iget函数
从内存缓存中索引设备dev的inode=inum的inode结构体,如果找到就返回这个inode,如果没有就查看内存是否有空引用的inode,如果有就分配给dev的inum
inode使用,并且返回这个新inode内存,如果没有就panic。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// Find the inode with number inum on device dev
// and return the in-memory copy. Does not lock
// the inode and does not read it from disk.
static struct inode*
iget(uint dev, uint inum)
{
struct inode *ip, *empty;
acquire(&icache.lock);
// Is the inode already cached?
empty = 0;
for(ip = &icache.inode[0]; ip < &icache.inode[NINODE]; ip++){
if(ip->ref > 0 && ip->dev == dev && ip->inum == inum){ //icache缓存了这个inode且引用数不为0
ip->ref++; //引用数加1
release(&icache.lock);
return ip; //返回这个inode结构体内存
}
if(empty == 0 && ip->ref == 0) //只找到空的inode
empty = ip; //将该inode记为empty inode
}
//inode不存在内存缓存icache、也没有空inode(这时需要额外的换出策略)
if(empty == 0)
panic("iget: no inodes");
ip = empty; //将空inode给dev的inum使用
ip->dev = dev;
ip->inum = inum;
ip->ref = 1;
ip->valid = 0; //逻辑上创建,没有从磁盘读入,因此置0
release(&icache.lock);
return ip;
}
ialloc函数
ialloc函数会为dev设备,文件类型(普通文件/目录文件)为type的文件分配一个inode,这个inode存在于内存的icache缓存中,这里的分配是线性的,内存从inum=1开始查找,检查每个inode结构体的type字段是否为0(空闲状态),如果是则将这个inode分配给dev的文件,并且inode字段记录这个inum作为这个文件的inode编号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// Allocate an inode on device dev.
// Mark it as allocated by giving it type type.
// Returns an unlocked but allocated and referenced inode.
struct inode*
ialloc(uint dev, short type)
{
int inum; //inode号
struct buf *bp;
struct dinode *dip;
for(inum = 1; inum < sb.ninodes; inum++){
bp = bread(dev, IBLOCK(inum, sb)); //读取inum所在的块
dip = (struct dinode*)bp->data + inum%IPB; //inum%IPB得到索引号在一个块的偏移量,dip=data[inum%IPB]对应inum的缓存块数据
if(dip->type == 0){ // a free inode
memset(dip, 0, sizeof(*dip));
dip->type = type;
log_write(bp); // mark it allocated on the disk
brelse(bp);
return iget(dev, inum); //通过iget从内存查找或者新建inode给dev,返回inode结构体内存
}
brelse(bp);
}
panic("ialloc: no inodes");
}
iupdate
在文件系统操作中,操作首先调用和影响的是内存中的inode,通过iupdate函数可以将它更新到磁盘的dinode,更新的内容是它们的共同字段,例如文件类型、设备号、引用数、大小、13个inode编号,然后调用brelse尝试释放这个inode空间(只有ref=0才会被真正释放)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// Copy a modified in-memory inode to disk.
// Must be called after every change to an ip->xxx field
// that lives on disk, since i-node cache is write-through.
// Caller must hold ip->lock.
void
iupdate(struct inode *ip)
{
struct buf *bp;
struct dinode *dip;
bp = bread(ip->dev, IBLOCK(ip->inum, sb)); //读取ip->inum所在的块
dip = (struct dinode*)bp->data + ip->inum%IPB; //
dip->type = ip->type;
dip->major = ip->major;
dip->minor = ip->minor;
dip->nlink = ip->nlink;
dip->size = ip->size;
memmove(dip->addrs, ip->addrs, sizeof(ip->addrs));
log_write(bp);
brelse(bp);
}
idup
将inode引用数加1; 1
2
3
4
5
6
7
8
9
10// Increment reference count for ip.
// Returns ip to enable ip = idup(ip1) idiom.
struct inode*
idup(struct inode *ip)
{
acquire(&icache.lock);
ip->ref++;
release(&icache.lock);
return ip;
}
ilock
ilock对缓存的inode上睡眠锁,从bcache的buf(磁盘的“代理人”)读入dinode信息;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// Lock the given inode.
// Reads the inode from disk if necessary.
void
ilock(struct inode *ip)
{
struct buf *bp;
struct dinode *dip;
if(ip == 0 || ip->ref < 1)
panic("ilock");
acquiresleep(&ip->lock);
if(ip->valid == 0){ //没有从磁盘读取过dinode
bp = bread(ip->dev, IBLOCK(ip->inum, sb)); //获取ip->inum所在的块号
dip = (struct dinode*)bp->data + ip->inum%IPB; //读取ip->inum的inode块内容
ip->type = dip->type; //读取磁盘数据(这些数据缓存在bcache的buf块中)
ip->major = dip->major;
ip->minor = dip->minor;
ip->nlink = dip->nlink;
ip->size = dip->size;
memmove(ip->addrs, dip->addrs, sizeof(ip->addrs));
brelse(bp);
ip->valid = 1;
if(ip->type == 0)
panic("ilock: no type");
}
}
iunlock
解inode的睡眠锁 1
2
3
4
5
6
7
8
9// Unlock the given inode.
void
iunlock(struct inode *ip)
{
if(ip == 0 || !holdingsleep(&ip->lock) || ip->ref < 1) //无inode/无睡眠锁/空inode
panic("iunlock");
releasesleep(&ip->lock); //睡眠锁
}
itrunc
itrunc函数将整个文件的Inode的数据清空,包括十三个Inode
Number的位图清空,Inode大小置0,位图清空对磁盘而言(dinode),即表明它可以重新分配给其他文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// Truncate inode (discard contents).
// Caller must hold ip->lock.
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
for(i = 0; i < NDIRECT; i++){ //NDIRECT=12,也就是前12个Direct Inode
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]); //将inode回收,即将其对应位图的位清0即可
ip->addrs[i] = 0;
}
}
if(ip->addrs[NDIRECT]){ //NDIRECT=12,也即第十三个Indirect Inode
bp = bread(ip->dev, ip->addrs[NDIRECT]); //读取这个inode块,这个块指向了一个块,存储了256个Inode(uint,每个4字节)
a = (uint*)bp->data; //256个Inode的起始地址
for(j = 0; j < NINDIRECT; j++){ //NINDIRECT=(BSIZE / sizeof(uint))=256
if(a[j])
bfree(ip->dev, a[j]); //逐个Inode释放(位图置0)
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]); //最后将这个Indirect Inode对应位图也置0
ip->addrs[NDIRECT] = 0; //数组清0
}
ip->size = 0;
iupdate(ip); //写回磁盘
}
iput
iput将一个没有硬链接(nlink=0)、只有当前进程使用、且已经经历过从磁盘读取的Inode释放,首先它调用了itrunc清空了其位图和大小,对内存而言,将type标志成0代表这个inode真正空闲,随后将ref和valid置0防止影响下次使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// Drop a reference to an in-memory inode.
// If that was the last reference, the inode cache entry can
// be recycled.
// If that was the last reference and the inode has no links
// to it, free the inode (and its content) on disk.
// All calls to iput() must be inside a transaction in
// case it has to free the inode.
void
iput(struct inode *ip)
{
acquire(&icache.lock);
if(ip->ref == 1 && ip->valid && ip->nlink == 0){ //只有一个引用(只有当前进程用,确保不会产生死锁)&&从磁盘读取&&没有硬链接
// inode has no links and no other references: truncate and free.
// ip->ref == 1 means no other process can have ip locked,
// so this acquiresleep() won't block (or deadlock).
acquiresleep(&ip->lock);
release(&icache.lock);
itrunc(ip); //清空addr的十三个Inode Number以及size大小
ip->type = 0; //type标志空闲
iupdate(ip); //至此dinode所有字段(除了针对设备文件的主次设备字段)都被清空,因此更新到dinode
ip->valid = 0; //初始化0
releasesleep(&ip->lock);
acquire(&icache.lock);
}
ip->ref--; //
release(&icache.lock);
}
iunlockput
解开Inode的睡眠锁并且标记这个Inode为空闲,其他进程可以将其初始化成新Inode使用。因为Inode操作都需要持有Inode的锁,在故障处理时必须先释放睡眠锁,再iput调失败的Inode操作,所以就之间封装了这个函数。
1
2
3
4
5
6
7// Common idiom: unlock, then put.
void
iunlockput(struct inode *ip)
{
iunlock(ip);
iput(ip);
}
bmap函数
bmap是重要的Inode映射函数,我们指定Inode和块号bn(默认机制是0~267,见前文Inode层),系统会为Inode分配一个块并且返回数据块号,我们查找文件数据时,得到其Inode,且得到数据的偏移(addr的偏移),就可以找到这个数据块号,读取相应的数据块就得到了文件数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38// Inode content
//
// The content (data) associated with each inode is stored
// in blocks on the disk. The first NDIRECT block numbers
// are listed in ip->addrs[]. The next NINDIRECT blocks are
// listed in block ip->addrs[NDIRECT].
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
if(bn < NDIRECT){ //bn是Direct Inode
if((addr = ip->addrs[bn]) == 0) //读取第bn个数据块,如果为0说明没有被分配
ip->addrs[bn] = addr = balloc(ip->dev); //分配,返回addr块号,此时bn块存储addr对应的数据块号
return addr; //返回数据块号
}
bn -= NDIRECT; //代表bn是Indirect Inode,减去12才能得到在256Inode Number的序号
if(bn < NINDIRECT){ //256个Inode中
// Load indirect block, allocating if necessary.
if((addr = ip->addrs[NDIRECT]) == 0) //读取第十三个Inode
ip->addrs[NDIRECT] = addr = balloc(ip->dev); //为0则需要开辟一个块存放Indirect Inode(存放第一个Inode Number)
bp = bread(ip->dev, addr);
a = (uint*)bp->data; //获得第一个Inode Number
if((addr = a[bn]) == 0){ //查找第bn个
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr; //返回间接块号
}
panic("bmap: out of range");
}
stati
将inode的设备号、Inode编号、文件类型、硬链接数、文件大小信息拷贝到st结构体;
1
2
3
4
5
6
7
8
9
10
11// Copy stat information from inode.
// Caller must hold ip->lock.
void
stati(struct inode *ip, struct stat *st)
{
st->dev = ip->dev;
st->ino = ip->inum;
st->type = ip->type;
st->nlink = ip->nlink;
st->size = ip->size;
}
readi
readi从Inode读取数据,off是每次读取的起始地址,一般由上层的系统函数进行跟踪,每次调用读取n字节。其中调用either_copyout只是封装了copyout和内核的memmove,代表既可以复制到用户空间(user_dst=1)也可以读到内核空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Read data from inode.
// Caller must hold ip->lock.
// If user_dst==1, then dst is a user virtual address;
// otherwise, dst is a kernel address.
int
readi(struct inode *ip, int user_dst, uint64 dst, uint off, uint n)//off偏移量一般是系统上层函数负责维护追踪
{
uint tot, m;
struct buf *bp;
if(off > ip->size || off + n < off) //偏移量越界或者读取字节为0
return 0;
if(off + n > ip->size) //读取n字节越界
n = ip->size - off; //只读到末尾
for(tot=0; tot<n; tot+=m, off+=m, dst+=m){ //m是每次读取字节
bp = bread(ip->dev, bmap(ip, off/BSIZE)); //读取off/BSIZE(Inode号)对应的数据块
m = min(n - tot, BSIZE - off%BSIZE); //m=剩下字节数、块剩余字节数的较小者,因为读取也要遵循块读取原则
if(either_copyout(user_dst, dst, bp->data + (off % BSIZE), m) == -1) { //复制块剩下字节的m字节到内核dst或者用户dst
brelse(bp);
tot = -1;
break; //一次读取失败返回-1
}
brelse(bp);
}
return tot;
}
writei
writei将来自内核或者用户空间的数据写入文件的Inode,单次调用时写入的数据大小不能超过Inode结构大小,即256+12个块;为什么这里判断的是off而不是n呢,n是数据写入大小,off是文件的整体偏移量(上层函数追踪),文件的数据必须连续地存储在一个Inode中,xv6也没有将单个文件数据分散到若干个Inode的机制,因此是文件的off不能超过268个块,大于此的文件就无法写入了,这就是Lab
10文件系统需要优化的地方。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// Write data to inode.
// Caller must hold ip->lock.
// If user_src==1, then src is a user virtual address;
// otherwise, src is a kernel address.
// Returns the number of bytes successfully written.
// If the return value is less than the requested n,
// there was an error of some kind.
int
writei(struct inode *ip, int user_src, uint64 src, uint off, uint n)
{
uint tot, m;
struct buf *bp;
if(off > ip->size || off + n < off)
return -1;
if(off + n > MAXFILE*BSIZE) //MAXFILE=(NDIRECT + NINDIRECT),单个Inode大小不能超过12+256个块
return -1;
for(tot=0; tot<n; tot+=m, off+=m, src+=m){
bp = bread(ip->dev, bmap(ip, off/BSIZE));
m = min(n - tot, BSIZE - off%BSIZE);
if(either_copyin(bp->data + (off % BSIZE), user_src, src, m) == -1) {//写入数据来自用户空间或者内核空间
brelse(bp);
break;
}
log_write(bp);
brelse(bp);
}
if(off > ip->size) //更新inode的大小
ip->size = off;
// write the i-node back to disk even if the size didn't change
// because the loop above might have called bmap() and added a new
// block to ip->addrs[].
iupdate(ip);
return tot;
}
目录操作函数
namecmp
调用strncmp比较目录名是否一致,一致返回0,DIRSIZ=14,为目录项最大文件名长度。
1
2
3
4
5
6// Directories
int
namecmp(const char *s, const char *t)
{
return strncmp(s, t, DIRSIZ);
}
dirlookup
dirlookup从dp
Inode查找名为name的目录项,返回这个目录项对应文件或者目录的Inode,且poff记录了目录项字节偏移(Optional)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// Look for a directory entry in a directory.
// If found, set *poff to byte offset of entry.
struct inode*
dirlookup(struct inode *dp, char *name, uint *poff)
{
uint off, inum;
struct dirent de;
if(dp->type != T_DIR)
panic("dirlookup not DIR");
for(off = 0; off < dp->size; off += sizeof(de)){
if(readi(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de))
panic("dirlookup read");
if(de.inum == 0) //未分配目录项
continue;
if(namecmp(name, de.name) == 0){ //根据目录名匹配到目录项
// entry matches path element
if(poff)
*poff = off; //记录目录项字节偏移
inum = de.inum; //目录项对应的inum
return iget(dp->dev, inum); //返回目录项对应的Inode
}
}
return 0;
}
dirlink
dirlink函数在dp Inode中加入新的目录项,名为name,inode编号为inum;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// Write a new directory entry (name, inum) into the directory dp.
int
dirlink(struct inode *dp, char *name, uint inum)
{
int off;
struct dirent de;
struct inode *ip;
// Check that name is not present.
if((ip = dirlookup(dp, name, 0)) != 0){ //目录名不存在
iput(ip);
return -1;
}
// Look for an empty dirent.
for(off = 0; off < dp->size; off += sizeof(de)){
if(readi(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de)) //读取dp Ionde现存的目录项
panic("dirlink read");
if(de.inum == 0) //寻找未分配的目录项
break;
}
strncpy(de.name, name, DIRSIZ); //复制到目录名
de.inum = inum; //设置目录项
if(writei(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de)) //0代表数据来自内核,将目录项写入dp的Inode
panic("dirlink");
return 0;
}
skipelem
skipelem函数提取了一个路径的首个目录名到name参数,函数返回剩下的目录名,他完成的操作是:
1. 跳过开头的'/'元素;
找到下一个'/'元素位置,将中间的字符提取到name;
跳过name字符后面的‘/’,并且返回; 见注释的几个例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// Paths
// Copy the next path element from path into name.
// Return a pointer to the element following the copied one.
// The returned path has no leading slashes,
// so the caller can check *path=='\0' to see if the name is the last one.
// If no name to remove, return 0.
//
// Examples:
// skipelem("a/bb/c", name) = "bb/c", setting name = "a"
// skipelem("///a//bb", name) = "bb", setting name = "a"
// skipelem("a", name) = "", setting name = "a"
// skipelem("", name) = skipelem("////", name) = 0
// skipelem("/a/bb/c", name) = "bb/c",name="a"
// skipelem("/////a/////bb///c", name) = "bb///c",name="a"
static char*
skipelem(char *path, char *name)
{
char *s;
int len;
while(*path == '/') //跳过开头的‘/’
path++;
if(*path == 0) //空path
return 0;
s = path; //从‘/’后面的字符起始
while(*path != '/' && *path != 0)
path++; //没遇到下个path
len = path - s; //这是两个'/'中间字符的长度
if(len >= DIRSIZ)
memmove(name, s, DIRSIZ);
else { //中间字符赋值给name
memmove(name, s, len);
name[len] = 0; //结束符
}
while(*path == '/') //跳过中间字符后面所有斜杠
path++; //这是下级字符的起始地址
return path; //剩下的下级字符
}
莫名其妙namex函数
这个函数设计有点逻辑混乱,但用起来还是很必要的。path是需要解析的路径名,例如‘a/b/file.c’;name会自动填充,调用了skipelem循环地将path的每级文件名从上级到下级填入name;这里使用了nameiparent,用于指示是否要解析出末级的Inode,如果nameiparent=1,那么指向的是末级Inode的父目录的Inode;
看例子比较直观:
namex("a/b/file.c", 0, char *name),这种情况,假设b不是一个目录,返回0代表失败;假如b下面没有file.c或者传入的参数是"a/b/",查找失败,返回0;其他成功查找"file.c",则会返回这个file.c的Inode,此时name=“file.c”;
namex("a/b/file.c", 1, char
*name)这种情况,假设b不是一个目录,返回0代表失败;假设b下面没有file.c、传入的参数是"a/b/c"或者查找“file.c”成功,都会返回b的Inode,name分别是0,c,file.c;因为这里返回b的优先级是最高的,但是逻辑处理之间存在重叠,就有点费解;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38// Look up and return the inode for a path name.
// If parent != 0, return the inode for the parent and copy the final
// path element into name, which must have room for DIRSIZ bytes.
// Must be called inside a transaction since it calls iput().
static struct inode*
namex(char *path, int nameiparent, char *name)
{
struct inode *ip, *next;
if(*path == '/') //起始时为根目录
ip = iget(ROOTDEV, ROOTINO); //索引根目录的Inode
else
ip = idup(myproc()->cwd); //cwd是当前进程所在的目录,ref++
while((path = skipelem(path, name)) != 0){//返回的path是循环的提取下级目录,name存储了当前目录名称
ilock(ip);
if(ip->type != T_DIR){ //当前Inode不是目录
iunlockput(ip);
return 0;
}
if(nameiparent && *path == '\0'){ //nameiparent!=0,下级目录为空,说明已经解析到某尾了
// Stop one level early.
iunlock(ip);
return ip; //返回的是当前目录的Inode
}
if((next = dirlookup(ip, name, 0)) == 0){ //当前目录Inode没有name的Inode
iunlockput(ip);
return 0;
}
iunlockput(ip);
ip = next; //如果有name的Inode,ip指向的是name的Inode
}
if(nameiparent){ //nameiparent=1,只有特殊情况才能运行到这里,例如参数是"/"
iput(ip);
return 0;
}
return ip;
}
namei
见namex解析,0代表解析path的末级文件或者目录的Inode,name将存储末级文件或者目录名称,因为文件inode已经返回了,name也没必要作为参数;
1
2
3
4
5
6struct inode*
namei(char *path)
{
char name[DIRSIZ];
return namex(path, 0, name);
}
nameiparent
见namex解析,1代表解析path的末级文件或者目录的上一级目录的Inode,name返回的是文件名;
1
2
3
4
5struct inode*
nameiparent(char *path, char *name)
{
return namex(path, 1, name);
}
sysfile.c
一部分系统调用存在于kernel/sysproc.c,另一部分和文件系统调用相关的调用接口就存于kernel/sysfile.c;
argfd
argfd和argint、argaddr是孪生兄弟,argfd从文件描述符n提取文件描述符存入int指针pfd,提取文件结构体指针存入pf,二者之一可为NULL;文件描述符和文件结构体指针都提供了访问读写文件的方式,文件描述符作用域是整个操作系统,通过系统调用的方式,文件结构体指针作用域是当前进程,通过库函数实现;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// Fetch the nth word-sized system call argument as a file descriptor
// and return both the descriptor and the corresponding struct file.
static int
argfd(int n, int *pfd, struct file **pf)
{
int fd;
struct file *f;
if(argint(n, &fd) < 0)
return -1;
//文件描述符合法,NOFILE是系统最大文件数,ofile是进程文件描述符表,检查fd对应的文件结构是否有效
if(fd < 0 || fd >= NOFILE || (f=myproc()->ofile[fd]) == 0)
return -1;
if(pfd)
*pfd = fd;
if(pf)
*pf = f;
return 0;
}
fdalloc
系统为文件结构体指针分配一个文件描述符。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/ Allocate a file descriptor for the given file.
// Takes over file reference from caller on success.
static int
fdalloc(struct file *f)
{
int fd;
struct proc *p = myproc();
for(fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd] == 0){ //文件描述符未使用
p->ofile[fd] = f;
return fd;
}
}
return -1;
}
sys_dup
接收文件结构体指针参数f,为f分配一个文件描述符fd,并且将文件f引用数加1;
1
2
3
4
5
6
7
8
9
10
11
12
13uint64
sys_dup(void)
{
struct file *f;
int fd;
if(argfd(0, 0, &f) < 0)
return -1;
if((fd=fdalloc(f)) < 0)
return -1;
filedup(f);
return fd;
}
sys_read
接收参数依次是文件描述符f,用户虚拟地址p,读字节数n,系统调用从文件描述符f读取n个字节到用户虚拟地址p;
1
2
3
4
5
6
7
8
9
10
11uint64
sys_read(void)
{
struct file *f;
int n;
uint64 p;
if(argfd(0, 0, &f) < 0 || argint(2, &n) < 0 || argaddr(1, &p) < 0)
return -1;
return fileread(f, p, n);
}
sys_write
接收参数依次是文件描述符f,用户虚拟空间源地址p,n字节数,代表从用户空间p接收n字节数据,内核会将其写入文件f;
1
2
3
4
5
6
7
8
9
10
11
12
13uint64
sys_write(void)
{
struct file *f;
int n;
uint64 p;
if(argfd(0, 0, &f) < 0 || argint(2, &n) < 0 || argaddr(1, &p) < 0)
return -1;
return filewrite(f, p, n);
}
sys_close
接收参数文件结构体指针f和文件描述符f,将文件描述符回收,
1
2
3
4
5
6
7
8
9
10
11
12uint64
sys_close(void)
{
int fd;
struct file *f;
if(argfd(0, &fd, &f) < 0)
return -1;
myproc()->ofile[fd] = 0; //回收该进程的文件描述符表fd项信息
fileclose(f); //关闭文件f
return 0;
}
sys_fstat
接收参数文件描述符f,用户虚拟地址(struct
stat地址),返回stat的结构体信息,见filestat; 1
2
3
4
5
6
7
8
9
10uint64
sys_fstat(void)
{
struct file *f;
uint64 st; // user pointer to struct stat
if(argfd(0, 0, &f) < 0 || argaddr(1, &st) < 0)
return -1;
return filestat(f, st);
}
sys_link函数
在这个函数之前,必须先了解文件链接的两种方式:软链接和硬链接,它们都能实现不同的文件名访问同一个文件,但是存在区别:
硬链接:一个文件的inode可以对应多个文件名,在Linux下,这个命令是ln a b(应先创建b),文件a和b都将指向同一块inode,通过任何一方修改,都会同步到另一个文件名的内容,但注意,删除文件不等于删除inode,因为这里相当于inode引用数有两个,只有引用数为0,inode才会被系统回收;另一个重要的特点是硬链接不能跨文件系统创建,也不能指向目录;
软链接:可以看成一种快捷方式,在Linux下命令是ln -s a b(注意运行命令时不要提前创建b,会发生嵌套),此时b相当于一个快捷方式,b有自己的inode和数据块,但是数据块存储的是a的路径信息,因此它能通过b访问a。软链接可以跨文件系统创建,也支持对目录进行软链接。
这里的sys_link是对inode而言,因此是硬链接,sys_link接受旧路径和新路径,并且将新路径的inode指向旧路径末级文件(目录没有硬链接操作)的inode;
sys_link接收的参数依次是旧路径名称(a/b/file)、新路径名称(c/d/newfile),通过namei所以到file的inode,通过nameiparent索引到d的Inode,确保file是文件不是目录,增加file的nlink,将file的inum加入到d的目录项,并且目录项的名称为newfile,这样就建立了硬链接关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50// Create the path new as a link to the same inode as old.
uint64
sys_link(void)
{
char name[DIRSIZ], new[MAXPATH], old[MAXPATH]; //文件名、新路径、旧路径
struct inode *dp, *ip;
if(argstr(0, old, MAXPATH) < 0 || argstr(1, new, MAXPATH) < 0)
return -1;
begin_op(); //log层开始记录
if((ip = namei(old)) == 0){ //通过old路径索引其末级文件或者目录的Inode失败
end_op(); //结束
return -1;
}
//ip为末级目录或者末级文件的Inode
ilock(ip);
if(ip->type == T_DIR){ //目录类型是无法硬链接的(因为目录的Inode放的是目录项,没有nlink)
iunlockput(ip);
end_op();
return -1;
}
ip->nlink++; //文件ip硬链接数加一
iupdate(ip);
iunlock(ip);
if((dp = nameiparent(new, name)) == 0) //解析new路径的文件的上一级目录(name为new路径的末级文件名,即硬链接的新文件名)
goto bad;
ilock(dp);
//设备号不同(inum是不对应的,不能跨设备)
if(dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0){ //将name、ip->inum加入dp的目录项
iunlockput(dp);
goto bad;
}
iunlockput(dp);
iput(ip);
end_op();
return 0;
bad: //故障处理
ilock(ip);
ip->nlink--; //硬链接
iupdate(ip); //更新硬盘
iunlockput(ip);
end_op();
return -1;
}
isdirempty
通过一个目录Inode判断该目录是否为空目录,为空返回1,否则返回0,空目录的Inode只有"."和".."目录项;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// Is the directory dp empty except for "." and ".." ?
static int
isdirempty(struct inode *dp)
{
int off;
struct dirent de;
for(off=2*sizeof(de); off<dp->size; off+=sizeof(de)){ //跳过当前目录和上级目录的目录项
if(readi(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de))//0代表读数据到内核,off读入de
panic("isdirempty: readi");
if(de.inum != 0) //有其他目录项
return 0; //返回0
}
return 1;
}
sys_unlink
sys_unlink接受一个路径参数,如果该路径的末级是一个文件或者空目录,则会从其父目录中删去;具体是解析出路径末级文件或者目录的inode,称ip,且得到ip的父目录inode,称dp;从dp通过文件名索引ip的目录项,置空这个目录项;然后处理ip的inode,无论ip是一个文件inode还是目录inode,将其nlink字段-1代表该路径已经失效,特别的是如果ip是目录inode,还需要将其父目录inode即dp的nlink-1,因为子目录被删去了,删去前子目录的".."目录项是可以进入父目录的,说明父目录的nlink也减小了1;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56uint64
sys_unlink(void)
{
struct inode *ip, *dp;
struct dirent de;
char name[DIRSIZ], path[MAXPATH];//14,128
uint off;
if(argstr(0, path, MAXPATH) < 0) //参数path
return -1;
begin_op();
if((dp = nameiparent(path, name)) == 0){ //dp=path末级文件/目录的父目录的Inode,name返回path的末级文件名或者目录名
end_op();
return -1;
}
ilock(dp); //读入dp目录信息
// Cannot unlink "." or "..".
if(namecmp(name, ".") == 0 || namecmp(name, "..") == 0) //name找到的是当前.或者..,不处理,这两个目录项不用删除
goto bad;
if((ip = dirlookup(dp, name, &off)) == 0) //从dp查找name的目录项,返回ip为文件或者目录对应的inode,off是目录项的地址
goto bad; //找不到
ilock(ip); //lock且从磁盘读入ip信息
if(ip->nlink < 1) //这个文件没有硬链接(因为如果ip文件/目录存在于当前的目录,nlink肯定不为0,见sys_link)
panic("unlink: nlink < 1");
if(ip->type == T_DIR && !isdirempty(ip)){ //ip不是非空目录则执行故障处理
iunlockput(ip);
goto bad;
}
//ip已经是空目录或者文件
memset(&de, 0, sizeof(de)); //de空目录项
if(writei(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de)) //将de写入dp目录项,即置空原有的目录项
panic("unlink: writei");
if(ip->type == T_DIR){ //空目录
dp->nlink--; //子目录删除了,父目录会失去一个nlink(新建是dp也会++,见create函数)
iupdate(dp);
}
iunlockput(dp);
ip->nlink--; //文件或者目录自身的硬链接要减一,因为该处路径没有了
iupdate(ip);
iunlockput(ip);
end_op();
return 0;
bad:
iunlockput(dp);
end_op();
return -1;
}
create
在路径path下创建一个文件类型为type(文件、目录、设备文件、符号链接(Lab
File
System内容)),如果是设备文件,major、minor为对应的主次设备号,最后返回这个文件的Inode;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46static struct inode*
create(char *path, short type, short major, short minor)
{
struct inode *ip, *dp;
char name[DIRSIZ];
if((dp = nameiparent(path, name)) == 0) //从path获取末级目录或者文件的父目录,name为末级文件名或者目录名
return 0;
ilock(dp);
if((ip = dirlookup(dp, name, 0)) != 0){ //从dp目录查找名为name的文件或目录Inode
iunlockput(dp);
ilock(ip);
if(type == T_FILE && (ip->type == T_FILE || ip->type == T_DEVICE)) //新建类型是文件类型,且原来存在的文件或设备文件也称name
return ip; //返回这个文件Inode
//其他情况
iunlockput(ip);
return 0;
}
//没有名为name的目录项
if((ip = ialloc(dp->dev, type)) == 0) //分配IP
panic("create: ialloc");
ilock(ip);
ip->major = major; //设备文件才有意义,其他文件类型一概传入是0;
ip->minor = minor;
ip->nlink = 1;
iupdate(ip);
//新建的是目录
if(type == T_DIR){ // Create . and .. entries.
dp->nlink++; // for "..",注意,这就是为什么sys_unlink的dp--,新建目录,ip的..硬链接到父目录
iupdate(dp);
// No ip->nlink++ for ".": avoid cyclic ref count.
if(dirlink(ip, ".", ip->inum) < 0 || dirlink(ip, "..", dp->inum) < 0) //加入目录项
panic("create dots");
}
if(dirlink(dp, name, ip->inum) < 0) //将ip加入父目录的目录项
panic("create: dirlink");
iunlockput(dp);
return ip;
}
sys_open
sys_open定义了打开文件的方法,首先打开文件xv6定义了几种类型:
1
2
3
4
5
6//kernel/fcntl.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67uint64
sys_open(void)
{
char path[MAXPATH];
int fd, omode;
struct file *f;
struct inode *ip;
int n;
if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0) //接收参数path,和打开方式omode
return -1;
begin_op();
if(omode & O_CREATE){ //创建文件模式
ip = create(path, T_FILE, 0, 0); //调用create创建文件,文件类型是普通文件,返回新建文件的Inode
if(ip == 0){
end_op();
return -1;
}
} else { //非创建模式
if((ip = namei(path)) == 0){ //解析path路径末级文件或者目录
end_op();
return -1;
}
ilock(ip); //从磁盘更新这个文件、目录的数据,即读入文件数据(相当于文件打开了)
if(ip->type == T_DIR && omode != O_RDONLY){ //xv6目录只能只读打开,不允许写操作(即创建子目录、更改命名等)
iunlockput(ip);
end_op();
return -1;
}
}
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){ //设备文件判断主次设备号是否合法
iunlockput(ip);
end_op();
return -1;
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){ //为文件分配文件结构体指针f,分配文件描述符fd
if(f) //指针成功,但文件描述符没有了
fileclose(f); //释放指针
iunlockput(ip);
end_op();
return -1;
}
if(ip->type == T_DEVICE){ //设备文件
f->type = FD_DEVICE; //向文件结构体写入
f->major = ip->major;
} else {
f->type = FD_INODE;
f->off = 0;
}
f->ip = ip;
f->readable = !(omode & O_WRONLY); //非只写就可读
f->writable = (omode & O_WRONLY) || (omode & O_RDWR); //只有只写、读写才可写
if((omode & O_TRUNC) && ip->type == T_FILE){ //文件截断
itrunc(ip); //清除位图,即仅清空文件数据,不会删除文件本身
}
iunlock(ip);
end_op();
return fd;
}
sys_mkdir
sys_mkdir接收路径参数,在路径path下创建一个目录; 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15uint64
sys_mkdir(void)
{
char path[MAXPATH];
struct inode *ip;
begin_op();
if(argstr(0, path, MAXPATH) < 0 || (ip = create(path, T_DIR, 0, 0)) == 0){
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19uint64
sys_mknod(void)
{
struct inode *ip;
char path[MAXPATH];
int major, minor;
begin_op();
if((argstr(0, path, MAXPATH)) < 0 ||
argint(1, &major) < 0 ||
argint(2, &minor) < 0 ||
(ip = create(path, T_DEVICE, major, minor)) == 0){
end_op();
return -1;
}
iunlockput(ip);
end_op();
return 0;
}
sys_chdir
接收目录路径参数path,确保它是一个目录类型,sys_chdir会将当前进程的工作目录切换到path指向的目录;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24uint64
sys_chdir(void)
{
char path[MAXPATH];
struct inode *ip;
struct proc *p = myproc();
begin_op();
if(argstr(0, path, MAXPATH) < 0 || (ip = namei(path)) == 0){ //解析path的末级文件或者目录,作为新目录
end_op();
return -1;
}
ilock(ip);
if(ip->type != T_DIR){ //防止path末级是文件类型
iunlockput(ip);
end_op();
return -1;
}
iunlock(ip);
iput(p->cwd); //进程cwd指向是当前工作目录
end_op();
p->cwd = ip;
return 0;
}
sys_exec
sys_exec是exec的系统调用,核心还是调用了exec函数,exec函数接收参数是路径path(一般是指向一个可执行程序),以及与这个程序对应的参数,用这个程序+参数替代当前进程的程序(详见exec.c的实现);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41uint64
sys_exec(void)
{
char path[MAXPATH], *argv[MAXARG];
int i;
uint64 uargv, uarg; //用户参数数组、用户参数数组的字符
if(argstr(0, path, MAXPATH) < 0 || argaddr(1, &uargv) < 0){//接收路径参数path,用户参数数组起始地址uargv
return -1;
}
memset(argv, 0, sizeof(argv)); //
for(i=0;; i++){ //遍历参数数组uargv
if(i >= NELEM(argv)){
goto bad;
}
if(fetchaddr(uargv+sizeof(uint64)*i, (uint64*)&uarg) < 0){ //每个参数字符存入uarg地址(临时)
goto bad;
}
if(uarg == 0){
argv[i] = 0;
break;
}
argv[i] = kalloc(); //开辟内存
if(argv[i] == 0)
goto bad;
if(fetchstr(uarg, argv[i], PGSIZE) < 0) //将字符复制到内存argv
goto bad;
}
int ret = exec(path, argv); //调用exec,aggv对应参数所在内存的起始地址
for(i = 0; i < NELEM(argv) && argv[i] != 0; i++)
kfree(argv[i]);
return ret;
bad:
for(i = 0; i < NELEM(argv) && argv[i] != 0; i++)
kfree(argv[i]);
return -1;
}
sys_pipe
sys_pipe接收用户的管道(文件描述符数组地址),内核创建新的管道(分配文件描述符),并且将改文件描述符关联到(copyout)用户的读端和写端;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30uint64
sys_pipe(void)
{
uint64 fdarray; // user pointer to array of two integers
struct file *rf, *wf;
int fd0, fd1;
struct proc *p = myproc();
if(argaddr(0, &fdarray) < 0)
return -1;
if(pipealloc(&rf, &wf) < 0)
return -1;
fd0 = -1;
if((fd0 = fdalloc(rf)) < 0 || (fd1 = fdalloc(wf)) < 0){
if(fd0 >= 0)
p->ofile[fd0] = 0;
fileclose(rf);
fileclose(wf);
return -1;
}
if(copyout(p->pagetable, fdarray, (char*)&fd0, sizeof(fd0)) < 0 ||
copyout(p->pagetable, fdarray+sizeof(fd0), (char *)&fd1, sizeof(fd1)) < 0){
p->ofile[fd0] = 0;
p->ofile[fd1] = 0;
fileclose(rf);
fileclose(wf);
return -1;
}
return 0;
}
至此,文件系统的Inode、目录、文件相关调用就解析完毕了。
log层(Crash Recovery)
先鸽
