
【Openpcdet】部署之二:训练VOD数据集
在上一篇文章中,我们在服务器上部署了Openpcdet并完成了KITTI数据集的训练、可视化操作,这篇文章记录了在同样环境下更换数据集过程。
概述
KITTI点云数据是一个四维数据(空间坐标、反射强度),而VOD点云是一个七维数据(空间坐标、反射界面RCS、径向速度、径向补偿速度、时间戳)。我们的起始目标是去除VOD的标定文件,使用纯点云进行训练。但是这个目标没有达成,最大的原因是对于具体空间坐标转换不明确,因此不能代替标定文件。我在kitti上做了尝试,理由是有一款开源软件labelcloud给出了代码,当用户选择kitti格式标注时,它会自动给出这样的转换关系。我把代码应用在VOD数据集上,然而虽然得到了最佳的数据库表现,但是还是不足以用于训练,因为无法得到有效的梯度。另一方面应该说的是,Openpcdet的模块化完成得很好,另一方面是开源团队同样采取了Openpcdet作为他们的框架网络,尽管更改了数据集,只需要对若干个配置文件进行修改即可,而无需过多的修改训练、测试、可视化等demo。以下介绍了基于pointpillars框架训练毫米波雷达数据集的过程。值得注意的是,该文章写于搭建之后,仅记录了比较有价值的问题,没有面面俱到。
VOD数据集
在4D毫米波雷达领域,开源且高质量的数据集并不如激光雷达常见。View-of-Delft Dataset是Andras Palffy等发布并开源,包含激光雷达点云、4D毫米波雷达点云、摄像头照片、标定文件等,按照KITTI数据格式标注的一个免费数据集。
请注意,VoD 和 KITTI 标签之间有 3 个重要的不同之处(来自官方): 1. 2D 边界框是自动计算的:在 LiDAR 点云上进行的 3D 注释。虽然我们在 KITTI 格式的标签中提供了 2D 边界框,但这些边界框是通过将 3D 边界框投影到相机平面上并分配最小适合矩形来自动计算的。 2. 截断:由于相同原因(在图像平面上无标注),我们不提供截断信息(用于其他元数据)。重要提示:如果您不使用提供的 eval 模块,请务必不要在评估中使用截断值,请参阅此问题。 3. 旋转:原始的 KITTI devkit 假定相机和 LiDAR 的垂直轴(Y 和 Z)是平行的,只是指向不同的方向。然而在我们的研究车辆中,相机略微倾斜。因此,为了方便起见,我们定义对象围绕 LiDAR 的负垂直(-Z)轴旋转。实际上,许多开源库也是这样假定的:LiDAR 和相机的垂直轴(Z 和 Y)完全对齐。
我整理的标注说明如下:
KITTI数据集含义:15位数据
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66
34.98 -1.60
第1个字段:“Car”是目标类别
(若无摄像头标定,2、3、4字段被认为是不重要的)
第2个字段:“0.00”是截断程度,0代表物体未被截断,1代表完全截断;1位
第3个字段:“0”是遮挡标志,这里代表没有被遮挡;1位
第4个字段:“-1.67”是观察角度;1位
第5个字段:“642.24 178.50 680.14
208.68”是目标在2D图像上的左上角和右下角坐标,单位像素;4位
第6个字段:“1.38 1.49
3.32”是物体的三位尺度高宽长;3位
第7个字段:“2.41 1.66 34.98”是3D标注的坐标;3位
第8个字段:“-1.60”是物体相对Y轴的旋转角度;1位
VOD数据集含义:16位标记
bicycle 1005 1 -2.2331832977561787 732.4326 849.4864 904.0343 1007.20197
1.218651355883582 0.489789530635952 2.2042625008776606
-1.4975028696884864 3.6584763317992395 15.278407180581874
-2.330885557997906 1
第1个字段:“:bicycle”是目标类别
(若无摄像头标定,2、3、4字段被认为是不重要的)
第2个字段:是截断标志(但未使用,因为没有图片标注);新一版中1005是跟踪ID,是某个对象的唯一辨证信息
第3个字段:“1”是遮挡程度,这里代表部分被遮挡,0没有遮挡,2大部分遮挡;1位
第4个字段:“-2.2331832977561787”是观察角度;1位
第5个字段:“732.4326 849.4864 904.0343
1007.20197”,2Dbbox,是目标在2D图像上的左上角和右下角坐标,这个标注来自Lidar3D标注框投影自动生成,单位像素;4位
第6个字段:“1.218651355883582 0.489789530635952
2.2042625008776606”是物体的三位尺度高宽长;3位
第7个字段:“-1.4975028696884864 3.6584763317992395
15.278407180581874”是3D标注的坐标;3位
第8个字段:“-2.330885557997906”是相对-Z轴的旋转角度;1位
第9个字段:1,无用,去除和保留不影响读取
修改文件
因为该服务器同时存储了kitti数据的训练结果,为了防止数据混淆,使用custom路径配置网络,训练我们的VOD数据。
pointpillars网络配置
进入/tools/cfgs/kitti_models,复制pointpillar.yaml到custom_models,这个文件参考仓库,记录和修改了比较重要的信息: 1. L3 数据集配置路径 2. 点云信息POINT_CLOUD_RANGE、体素信息VOXEL_SIZE、数据增强的方法DATA_AUGMENTOR,由于pointpillars是基于4维数据的,还创建的一个新的编码类Radar7PillarVFE用于适配7维的VOD数据。 3. 优化方案:设置batch_size(显存小调小)、训练轮数epochs(给你玩)、学习率(一般默认,梯度下降)、学习率衰减等,采用adam_onecycle作为优化学习率算法。
完整配置: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152CLASS_NAMES: ['Car', 'Pedestrian', 'Cyclist']
DATA_CONFIG:
_BASE_CONFIG_: cfgs/dataset_configs/custom_dataset.yaml
POINT_CLOUD_RANGE: [0, -25.6, -3, 51.2, 25.6, 2]
DATA_PROCESSOR:
- NAME: mask_points_and_boxes_outside_range
REMOVE_OUTSIDE_BOXES: True
- NAME: shuffle_points
SHUFFLE_ENABLED: {
'train': True,
'test': False
}
- NAME: transform_points_to_voxels
VOXEL_SIZE: [0.16, 0.16, 5]
MAX_POINTS_PER_VOXEL: 10
MAX_NUMBER_OF_VOXELS: {
'train': 16000,
'test': 40000
}
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['random_world_rotation', 'gt_sampling']
AUG_CONFIG_LIST:
- NAME: random_world_flip
ALONG_AXIS_LIST: ['x']
- NAME: random_world_scaling
WORLD_SCALE_RANGE: [0.95, 1.05]
MODEL:
NAME: PointPillar
VFE:
NAME: Radar7PillarVFE
USE_XYZ: True
USE_RCS: True
USE_VR: True
USE_VR_COMP: True
USE_TIME: True
USE_NORM: True
USE_ELEVATION: True
USE_DISTANCE: False
NUM_FILTERS: [64]
MAP_TO_BEV:
NAME: PointPillarScatter
NUM_BEV_FEATURES: 64
BACKBONE_2D:
NAME: BaseBEVBackbone
LAYER_NUMS: [3, 5, 5]
LAYER_STRIDES: [2, 2, 2]
NUM_FILTERS: [64, 128, 256]
UPSAMPLE_STRIDES: [1, 2, 4]
NUM_UPSAMPLE_FILTERS: [128, 128, 128]
DENSE_HEAD:
NAME: AnchorHeadSingle
CLASS_AGNOSTIC: False
USE_DIRECTION_CLASSIFIER: True
DIR_OFFSET: 0.78539
DIR_LIMIT_OFFSET: 0.0
NUM_DIR_BINS: 2
ANCHOR_GENERATOR_CONFIG: [
{
'class_name': 'Car',
'anchor_sizes': [[3.9, 1.6, 1.56]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-1.78],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.6,
'unmatched_threshold': 0.45
},
{
'class_name': 'Pedestrian',
'anchor_sizes': [[0.8, 0.6, 1.73]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-0.6],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.5,
'unmatched_threshold': 0.35
},
{
'class_name': 'Cyclist',
'anchor_sizes': [[1.76, 0.6, 1.73]],
'anchor_rotations': [0, 1.57],
'anchor_bottom_heights': [-0.6],
'align_center': False,
'feature_map_stride': 2,
'matched_threshold': 0.5,
'unmatched_threshold': 0.35
}
]
TARGET_ASSIGNER_CONFIG:
NAME: AxisAlignedTargetAssigner
POS_FRACTION: -1.0
SAMPLE_SIZE: 512
NORM_BY_NUM_EXAMPLES: False
MATCH_HEIGHT: False
BOX_CODER: ResidualCoder
LOSS_CONFIG:
LOSS_WEIGHTS: {
'cls_weight': 1.0,
'loc_weight': 2.0,
'dir_weight': 0.2,
'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
}
POST_PROCESSING:
RECALL_THRESH_LIST: [0.3, 0.5, 0.7]
SCORE_THRESH: 0.1
OUTPUT_RAW_SCORE: False
EVAL_METRIC: kitti
NMS_CONFIG:
MULTI_CLASSES_NMS: False
NMS_TYPE: nms_gpu
NMS_THRESH: 0.01
NMS_PRE_MAXSIZE: 4096
NMS_POST_MAXSIZE: 500
OPTIMIZATION:
BATCH_SIZE_PER_GPU: 16
NUM_EPOCHS: 80
OPTIMIZER: adam_onecycle
LR: 0.003
WEIGHT_DECAY: 0.01 #权值衰减,L2正则化
MOMENTUM: 0.9 #动量
MOMS: [0.95, 0.85] #动量范围
PCT_START: 0.4 #学习率增加的周期时间占比
DIV_FACTOR: 10 #onecycle策略,学习率最高和学习率最低比值
DECAY_STEP_LIST: [35, 45] #第35、45周期学习率会衰减
LR_DECAY: 0.1 #学习率衰减
LR_CLIP: 0.0000001 #最小学习率,防止衰减到0
LR_WARMUP: False #是否进行学习率预热:从小线性增长到大
WARMUP_EPOCH: 1 #预热周期数
GRAD_NORM_CLIP: 10 #梯度裁剪:如果L2梯度范数大于10,则进行梯度放缩,防止梯度不稳定甚子爆炸
编码网络设置
为了适应点云数据,/pcdet/models/backbones_3d/vfe/pillar_vfe.py新建一个类来编码输入的点云数据,官方给出的编码网络如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147class Radar7PillarVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, voxel_size, point_cloud_range):
super().__init__(model_cfg=model_cfg)
num_point_features = 0
self.use_norm = self.model_cfg.USE_NORM # whether to use batchnorm in the PFNLayer
self.use_xyz = self.model_cfg.USE_XYZ
self.with_distance = self.model_cfg.USE_DISTANCE
self.selected_indexes = []
## check if config has the correct params, if not, throw exception
radar_config_params = ["USE_RCS", "USE_VR", "USE_VR_COMP", "USE_TIME", "USE_ELEVATION"]
if all(hasattr(self.model_cfg, attr) for attr in radar_config_params):
self.use_RCS = self.model_cfg.USE_RCS
self.use_vr = self.model_cfg.USE_VR
self.use_vr_comp = self.model_cfg.USE_VR_COMP
self.use_time = self.model_cfg.USE_TIME
self.use_elevation = self.model_cfg.USE_ELEVATION
else:
raise Exception("config does not have the right parameters, please use a radar config")
self.available_features = ['x', 'y', 'z', 'rcs', 'v_r', 'v_r_comp', 'time']
num_point_features += 6 # center_x, center_y, center_z, mean_x, mean_y, mean_z, time, we need 6 new
self.x_ind = self.available_features.index('x')
self.y_ind = self.available_features.index('y')
self.z_ind = self.available_features.index('z')
self.rcs_ind = self.available_features.index('rcs')
self.vr_ind = self.available_features.index('v_r')
self.vr_comp_ind = self.available_features.index('v_r_comp')
self.time_ind = self.available_features.index('time')
if self.use_xyz: # if x y z coordinates are used, add 3 channels and save the indexes
num_point_features += 3 # x, y, z
self.selected_indexes.extend((self.x_ind, self.y_ind, self.z_ind)) # adding x y z channels to the indexes
if self.use_RCS: # add 1 if RCS is used and save the indexes
num_point_features += 1
self.selected_indexes.append(self.rcs_ind) # adding RCS channels to the indexes
if self.use_vr: # add 1 if vr is used and save the indexes. Note, we use compensated vr!
num_point_features += 1
self.selected_indexes.append(self.vr_ind) # adding v_r_comp channels to the indexes
if self.use_vr_comp: # add 1 if vr is used (as proxy for sensor cue) and save the indexes
num_point_features += 1
self.selected_indexes.append(self.vr_comp_ind)
if self.use_time: # add 1 if time is used and save the indexes
num_point_features += 1
self.selected_indexes.append(self.time_ind) # adding time channel to the indexes
### LOGGING USED FEATURES ###
print("number of point features used: " + str(num_point_features))
print("6 of these are 2 * (x y z) coordinates realtive to mean and center of pillars")
print(str(len(self.selected_indexes)) + " are selected original features: ")
for k in self.selected_indexes:
print(str(k) + ": " + self.available_features[k])
self.selected_indexes = torch.LongTensor(self.selected_indexes) # turning used indexes into Tensor
self.num_filters = self.model_cfg.NUM_FILTERS
assert len(self.num_filters) > 0
num_filters = [num_point_features] + list(self.num_filters)
pfn_layers = []
for i in range(len(num_filters) - 1):
in_filters = num_filters[i]
out_filters = num_filters[i + 1]
pfn_layers.append(
PFNLayer(in_filters, out_filters, self.use_norm, last_layer=(i >= len(num_filters) - 2))
)
self.pfn_layers = nn.ModuleList(pfn_layers)
## saving size of the voxel
self.voxel_x = voxel_size[0]
self.voxel_y = voxel_size[1]
self.voxel_z = voxel_size[2]
## saving offsets, start of point cloud in x, y, z + half a voxel, e.g. in y it starts around -39 m
self.x_offset = self.voxel_x / 2 + point_cloud_range[0]
self.y_offset = self.voxel_y / 2 + point_cloud_range[1]
self.z_offset = self.voxel_z / 2 + point_cloud_range[2]
def get_output_feature_dim(self):
return self.num_filters[-1] # number of outputs in last output channel
def get_paddings_indicator(self, actual_num, max_num, axis=0):
actual_num = torch.unsqueeze(actual_num, axis + 1)
max_num_shape = [1] * len(actual_num.shape)
max_num_shape[axis + 1] = -1
max_num = torch.arange(max_num, dtype=torch.int, device=actual_num.device).view(max_num_shape)
paddings_indicator = actual_num.int() > max_num
return paddings_indicator
def forward(self, batch_dict, **kwargs):
## coordinate system notes
# x is pointing forward, y is left right, z is up down
# spconv returns voxel_coords as [batch_idx, z_idx, y_idx, x_idx], that is why coords is indexed backwards
voxel_features, voxel_num_points, coords = batch_dict['voxels'], batch_dict['voxel_num_points'], batch_dict[
'voxel_coords']
if not self.use_elevation: # if we ignore elevation (z) and v_z
voxel_features[:, :, self.z_ind] = 0 # set z to zero before doing anything
orig_xyz = voxel_features[:, :, :self.z_ind + 1] # selecting x y z
# calculate mean of points in pillars for x y z and save the offset from the mean
# Note: they do not take the mean directly, as each pillar is filled up with 0-s. Instead, they sum and divide by num of points
points_mean = orig_xyz.sum(dim=1, keepdim=True) / voxel_num_points.type_as(voxel_features).view(-1, 1, 1)
f_cluster = orig_xyz - points_mean # offset from cluster mean
# calculate center for each pillar and save points' offset from the center. voxel_coordinate * voxel size + offset should be the center of pillar (coords are indexed backwards)
f_center = torch.zeros_like(orig_xyz)
f_center[:, :, 0] = voxel_features[:, :, self.x_ind] - (
coords[:, 3].to(voxel_features.dtype).unsqueeze(1) * self.voxel_x + self.x_offset)
f_center[:, :, 1] = voxel_features[:, :, self.y_ind] - (
coords[:, 2].to(voxel_features.dtype).unsqueeze(1) * self.voxel_y + self.y_offset)
f_center[:, :, 2] = voxel_features[:, :, self.z_ind] - (
coords[:, 1].to(voxel_features.dtype).unsqueeze(1) * self.voxel_z + self.z_offset)
voxel_features = voxel_features[:, :, self.selected_indexes] # filtering for used features
features = [voxel_features, f_cluster, f_center]
if self.with_distance: # if with_distance is true, include range to the points as well
points_dist = torch.norm(orig_xyz, 2, 2, keepdim=True) # first 2: L2 norm second 2: along 2. dim
features.append(points_dist)
## finishing up the feature extraction with correct shape and masking
features = torch.cat(features, dim=-1)
voxel_count = features.shape[1]
mask = self.get_paddings_indicator(voxel_num_points, voxel_count, axis=0)
mask = torch.unsqueeze(mask, -1).type_as(voxel_features)
features *= mask
for pfn in self.pfn_layers:
features = pfn(features)
features = features.squeeze()
batch_dict['pillar_features'] = features
return batch_dict
在/pcdet/models/backbones_3d/vfe/__init__.py初始化文件中添加初始化声明:
1
2
3
4
5
6
7
8
9from .mean_vfe import MeanVFE
from .pillar_vfe import PillarVFE, Radar7PillarVFE
from .vfe_template import VFETemplate
__all__ = {
'VFETemplate': VFETemplate,
'MeanVFE': MeanVFE,
'PillarVFE': PillarVFE,
'Radar7PillarVFE': Radar7PillarVFE,
}
数据集配置
进入/tools/cfgs/dataset_configs,custom_dataset.yaml配置了数据集的相关信息,修改信息主要有:
1. L1数据集名:这个和后面文件的class必须对应,L2放数据的路径。
2.
INFO_PATH:python序列化文件名称,和后面一个文件命名一致,否则该配置无法读入
3.
POINT_FEATURE_ENCODING、POINT_CLOUD_RANGE、DATA_AUGMENTOR、VOXEL_SIZE、FOV_POINTS_ONLY、MAX_POINTS_PER_VOXEL等VOD数据集修改的点云配置。
完整配置: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55DATASET: 'CustomDataset'
DATA_PATH: '/root/autodl-tmp/opcnet/OpenPCDet/data/custom'
POINT_CLOUD_RANGE: [0, -25.6, -3, 51.2, 25.6, 2]
MAP_CLASS_TO_KITTI: {
'Vehicle': 'Car',
'Pedestrian': 'Pedestrian',
'Cyclist': 'Cyclist',
}
DATA_SPLIT: {
'train': train,
'test': val
}
INFO_PATH: {
'train': [custom_infos_train.pkl],
'test': [custom_infos_val.pkl],
}
FOV_POINTS_ONLY: True
POINT_FEATURE_ENCODING: {
encoding_type: absolute_coordinates_encoding,
used_feature_list: ['x', 'y', 'z', 'rcs', 'v_r', 'v_r_comp', 'time'],
src_feature_list: ['x', 'y', 'z', 'rcs', 'v_r', 'v_r_comp', 'time'],
}
DATA_AUGMENTOR:
DISABLE_AUG_LIST: ['placeholder']
AUG_CONFIG_LIST:
- NAME: random_world_flip
ALONG_AXIS_LIST: ['x']
- NAME: random_world_scaling
WORLD_SCALE_RANGE: [0.95, 1.05]
DATA_PROCESSOR:
- NAME: mask_points_and_boxes_outside_range
REMOVE_OUTSIDE_BOXES: True
- NAME: shuffle_points
SHUFFLE_ENABLED: {
'train': True,
'test': False
}
- NAME: transform_points_to_voxels
VOXEL_SIZE: [0.16, 0.16, 5]
MAX_POINTS_PER_VOXEL: 10
MAX_NUMBER_OF_VOXELS: {
'train': 16000,
'test': 40000
}
框架设置
来到了比较复杂的一个框架文件设置,如果遇到纰漏请参考其他博客。pcdet体贴地为我们准备了大量的custom文件夹和文件,但是给出了很多空间我们发挥,由于VOD数据集和KITTI是几乎同一数据格式的,所以很多东西可以沿用kitti,直接使用custom反而导致配置不完整而出错。
1. 进入/pcdet/utils,复制一份kitti命名为custom: 1
2mv object3d_custom.py object3d_custom1.py #不放心可以备份一份原来的,后面不再赘述这个问题
cp object3d_kitti.py object3d_custom.py1
cp -r kitti custom
1
2mv kitti_dataset.py custom_dataset.py
mv kitti_utils.py custom_utils.py
2. L66修改为reshape(-1,7),因为VOD是7位数据。
L176注释截断标注,因为VOD数据集没有使用,因为他们没有做图片标注。而且在新版标注中,该位置是对象跟踪ID,因此无用。
最后两行,修改文件路径,kitti改为custom,我们的数据放在/data/custom。
记住把文件名kitti改为custom,例如.pkl文件,L446、L452、L456等位置隐蔽信息,为了方便在检查一段代码后可以采取局部的替换,不要进行全文字符替换,因为这会带来更复杂的麻烦。全文坚持使用kitti目前来说未尝是一个坏选择,但是不利于日后更繁杂的修改,还要注意修改数据载入命令。
完整配置如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485import copy
import pickle
import numpy as np
from skimage import io
from . import custom_utils
from ...ops.roiaware_pool3d import roiaware_pool3d_utils
from ...utils import box_utils,calibration_kitti, common_utils, object3d_custom
from ..dataset import DatasetTemplate
class CustomDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None):
"""
Args:
root_path:
dataset_cfg:
class_names:
training:
logger:
"""
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger
)
self.split = self.dataset_cfg.DATA_SPLIT[self.mode]
self.root_split_path = self.root_path / ('training' if self.split != 'test' else 'testing')
split_dir = self.root_path / 'ImageSets' / (self.split + '.txt')
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if split_dir.exists() else None
self.kitti_infos = []
self.include_kitti_data(self.mode)
def include_kitti_data(self, mode):
if self.logger is not None:
self.logger.info('Loading custom dataset')
kitti_infos = []
for info_path in self.dataset_cfg.INFO_PATH[mode]:
info_path = self.root_path / info_path
if not info_path.exists():
continue
with open(info_path, 'rb') as f:
infos = pickle.load(f)
kitti_infos.extend(infos)
self.kitti_infos.extend(kitti_infos)
if self.logger is not None:
self.logger.info('Total samples for custom dataset: %d' % (len(kitti_infos)))
def set_split(self, split):
super().__init__(
dataset_cfg=self.dataset_cfg, class_names=self.class_names, training=self.training, root_path=self.root_path, logger=self.logger
)
self.split = split
self.root_split_path = self.root_path / ('training' if self.split != 'test' else 'testing')
split_dir = self.root_path / 'ImageSets' / (self.split + '.txt')
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if split_dir.exists() else None
def get_lidar(self, idx):
lidar_file = self.root_split_path / 'velodyne' / ('%s.bin' % idx)
assert lidar_file.exists()
return np.fromfile(str(lidar_file), dtype=np.float32).reshape(-1, 7)
def get_image(self, idx):
"""
Loads image for a sample
Args:
idx: int, Sample index
Returns:
image: (H, W, 3), RGB Image
"""
img_file = self.root_split_path / 'image_2' / ('%s.jpg' % idx)
assert img_file.exists()
image = io.imread(img_file)
image = image.astype(np.float32)
image /= 255.0
return image
def get_image_shape(self, idx):
img_file = self.root_split_path / 'image_2' / ('%s.jpg' % idx)
assert img_file.exists()
return np.array(io.imread(img_file).shape[:2], dtype=np.int32)
def get_label(self, idx):
label_file = self.root_split_path / 'label_2' / ('%s.txt' % idx)
assert label_file.exists()
return object3d_custom.get_objects_from_label(label_file)
def get_depth_map(self, idx):
"""
Loads depth map for a sample
Args:
idx: str, Sample index
Returns:
depth: (H, W), Depth map
"""
depth_file = self.root_split_path / 'depth_2' / ('%s.png' % idx)
assert depth_file.exists()
depth = io.imread(depth_file)
depth = depth.astype(np.float32)
depth /= 256.0
return depth
def get_calib(self, idx):
calib_file = self.root_split_path / 'calib' / ('%s.txt' % idx)
assert calib_file.exists()
return calibration_kitti.Calibration(calib_file)
def get_road_plane(self, idx):
plane_file = self.root_split_path / 'planes' / ('%s.txt' % idx)
if not plane_file.exists():
return None
with open(plane_file, 'r') as f:
lines = f.readlines()
lines = [float(i) for i in lines[3].split()]
plane = np.asarray(lines)
# Ensure normal is always facing up, this is in the rectified camera coordinate
if plane[1] > 0:
plane = -plane
norm = np.linalg.norm(plane[0:3])
plane = plane / norm
return plane
def get_fov_flag(pts_rect, img_shape, calib):
"""
Args:
pts_rect:
img_shape:
calib:
Returns:
"""
pts_img, pts_rect_depth = calib.rect_to_img(pts_rect)
val_flag_1 = np.logical_and(pts_img[:, 0] >= 0, pts_img[:, 0] < img_shape[1])
val_flag_2 = np.logical_and(pts_img[:, 1] >= 0, pts_img[:, 1] < img_shape[0])
val_flag_merge = np.logical_and(val_flag_1, val_flag_2)
pts_valid_flag = np.logical_and(val_flag_merge, pts_rect_depth >= 0)
return pts_valid_flag
def get_infos(self, num_workers=4, has_label=True, count_inside_pts=True, sample_id_list=None):
import concurrent.futures as futures
def process_single_scene(sample_idx):
print('%s sample_idx: %s' % (self.split, sample_idx))
info = {}
pc_info = {'num_features': 7, 'lidar_idx': sample_idx}
info['point_cloud'] = pc_info
image_info = {'image_idx': sample_idx, 'image_shape': self.get_image_shape(sample_idx)}
info['image'] = image_info
calib = self.get_calib(sample_idx)
P2 = np.concatenate([calib.P2, np.array([[0., 0., 0., 1.]])], axis=0)
R0_4x4 = np.zeros([4, 4], dtype=calib.R0.dtype)
R0_4x4[3, 3] = 1.
R0_4x4[:3, :3] = calib.R0
V2C_4x4 = np.concatenate([calib.V2C, np.array([[0., 0., 0., 1.]])], axis=0)
calib_info = {'P2': P2, 'R0_rect': R0_4x4, 'Tr_velo_to_cam': V2C_4x4}
info['calib'] = calib_info
if has_label:
obj_list = self.get_label(sample_idx)
annotations = {}
annotations['name'] = np.array([obj.cls_type for obj in obj_list])
#annotations['truncated'] = np.array([obj.truncation for obj in obj_list])
annotations['occluded'] = np.array([obj.occlusion for obj in obj_list])
annotations['alpha'] = np.array([obj.alpha for obj in obj_list])
annotations['bbox'] = np.concatenate([obj.box2d.reshape(1, 4) for obj in obj_list], axis=0)
annotations['dimensions'] = np.array([[obj.l, obj.h, obj.w] for obj in obj_list]) # lhw(camera) format
annotations['location'] = np.concatenate([obj.loc.reshape(1, 3) for obj in obj_list], axis=0)
annotations['rotation_y'] = np.array([obj.ry for obj in obj_list])
annotations['score'] = np.array([obj.score for obj in obj_list])
annotations['difficulty'] = np.array([obj.level for obj in obj_list], np.int32)
num_objects = len([obj.cls_type for obj in obj_list if obj.cls_type != 'DontCare'])
num_gt = len(annotations['name'])
index = list(range(num_objects)) + [-1] * (num_gt - num_objects)
annotations['index'] = np.array(index, dtype=np.int32)
loc = annotations['location'][:num_objects]
dims = annotations['dimensions'][:num_objects]
rots = annotations['rotation_y'][:num_objects]
loc_lidar = calib.rect_to_lidar(loc)
l, h, w = dims[:, 0:1], dims[:, 1:2], dims[:, 2:3]
loc_lidar[:, 2] += h[:, 0] / 2
gt_boxes_lidar = np.concatenate([loc_lidar, l, w, h, -(np.pi / 2 + rots[..., np.newaxis])], axis=1)
annotations['gt_boxes_lidar'] = gt_boxes_lidar
info['annos'] = annotations
if count_inside_pts:
points = self.get_lidar(sample_idx)
calib = self.get_calib(sample_idx)
pts_rect = calib.lidar_to_rect(points[:, 0:3])
fov_flag = self.get_fov_flag(pts_rect, info['image']['image_shape'], calib)
pts_fov = points[fov_flag]
corners_lidar = box_utils.boxes_to_corners_3d(gt_boxes_lidar)
num_points_in_gt = -np.ones(num_gt, dtype=np.int32)
for k in range(num_objects):
flag = box_utils.in_hull(pts_fov[:, 0:3], corners_lidar[k])
num_points_in_gt[k] = flag.sum()
annotations['num_points_in_gt'] = num_points_in_gt
return info
sample_id_list = sample_id_list if sample_id_list is not None else self.sample_id_list
with futures.ThreadPoolExecutor(num_workers) as executor:
infos = executor.map(process_single_scene, sample_id_list)
return list(infos)
def create_groundtruth_database(self, info_path=None, used_classes=None, split='train'):
import torch
database_save_path = Path(self.root_path) / ('gt_database' if split == 'train' else ('gt_database_%s' % split))
db_info_save_path = Path(self.root_path) / ('custom_dbinfos_%s.pkl' % split)
database_save_path.mkdir(parents=True, exist_ok=True)
all_db_infos = {}
with open(info_path, 'rb') as f:
infos = pickle.load(f)
for k in range(len(infos)):
print('gt_database sample: %d/%d' % (k + 1, len(infos)))
info = infos[k]
sample_idx = info['point_cloud']['lidar_idx']
points = self.get_lidar(sample_idx)
annos = info['annos']
names = annos['name']
difficulty = annos['difficulty']
bbox = annos['bbox']
gt_boxes = annos['gt_boxes_lidar']
num_obj = gt_boxes.shape[0]
point_indices = roiaware_pool3d_utils.points_in_boxes_cpu(
torch.from_numpy(points[:, 0:3]), torch.from_numpy(gt_boxes)
).numpy() # (nboxes, npoints)
for i in range(num_obj):
filename = '%s_%s_%d.bin' % (sample_idx, names[i], i)
filepath = database_save_path / filename
gt_points = points[point_indices[i] > 0]
gt_points[:, :3] -= gt_boxes[i, :3]
with open(filepath, 'w') as f:
gt_points.tofile(f)
if (used_classes is None) or names[i] in used_classes:
db_path = str(filepath.relative_to(self.root_path)) # gt_database/xxxxx.bin
db_info = {'name': names[i], 'path': db_path, 'image_idx': sample_idx, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0],
'difficulty': difficulty[i], 'bbox': bbox[i], 'score': annos['score'][i]}
if names[i] in all_db_infos:
all_db_infos[names[i]].append(db_info)
else:
all_db_infos[names[i]] = [db_info]
for k, v in all_db_infos.items():
print('Database %s: %d' % (k, len(v)))
with open(db_info_save_path, 'wb') as f:
pickle.dump(all_db_infos, f)
def generate_prediction_dicts(batch_dict, pred_dicts, class_names, output_path=None):
"""
Args:
batch_dict:
frame_id:
pred_dicts: list of pred_dicts
pred_boxes: (N, 7), Tensor
pred_scores: (N), Tensor
pred_labels: (N), Tensor
class_names:
output_path:
Returns:
"""
def get_template_prediction(num_samples):
ret_dict = {
'name': np.zeros(num_samples),
'occluded': np.zeros(num_samples), 'alpha': np.zeros(num_samples),
'bbox': np.zeros([num_samples, 4]), 'dimensions': np.zeros([num_samples, 3]),
'location': np.zeros([num_samples, 3]), 'rotation_y': np.zeros(num_samples),
'score': np.zeros(num_samples), 'boxes_lidar': np.zeros([num_samples, 7])
}
return ret_dict
def generate_single_sample_dict(batch_index, box_dict):
pred_scores = box_dict['pred_scores'].cpu().numpy()
pred_boxes = box_dict['pred_boxes'].cpu().numpy()
pred_labels = box_dict['pred_labels'].cpu().numpy()
pred_dict = get_template_prediction(pred_scores.shape[0])
if pred_scores.shape[0] == 0:
return pred_dict
calib = batch_dict['calib'][batch_index]
image_shape = batch_dict['image_shape'][batch_index].cpu().numpy()
pred_boxes_camera = box_utils.boxes3d_lidar_to_kitti_camera(pred_boxes, calib)
pred_boxes_img = box_utils.boxes3d_kitti_camera_to_imageboxes(
pred_boxes_camera, calib, image_shape=image_shape
)
pred_dict['name'] = np.array(class_names)[pred_labels - 1]
pred_dict['alpha'] = -np.arctan2(-pred_boxes[:, 1], pred_boxes[:, 0]) + pred_boxes_camera[:, 6]
pred_dict['bbox'] = pred_boxes_img
pred_dict['dimensions'] = pred_boxes_camera[:, 3:6]
pred_dict['location'] = pred_boxes_camera[:, 0:3]
pred_dict['rotation_y'] = pred_boxes_camera[:, 6]
pred_dict['score'] = pred_scores
pred_dict['boxes_lidar'] = pred_boxes
return pred_dict
annos = []
for index, box_dict in enumerate(pred_dicts):
frame_id = batch_dict['frame_id'][index]
single_pred_dict = generate_single_sample_dict(index, box_dict)
single_pred_dict['frame_id'] = frame_id
annos.append(single_pred_dict)
if output_path is not None:
cur_det_file = output_path / ('%s.txt' % frame_id)
with open(cur_det_file, 'w') as f:
bbox = single_pred_dict['bbox']
loc = single_pred_dict['location']
dims = single_pred_dict['dimensions'] # lhw -> hwl
for idx in range(len(bbox)):
print('%s -1 -1 %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f %.4f'
% (single_pred_dict['name'][idx], single_pred_dict['alpha'][idx],
bbox[idx][0], bbox[idx][1], bbox[idx][2], bbox[idx][3],
dims[idx][1], dims[idx][2], dims[idx][0], loc[idx][0],
loc[idx][1], loc[idx][2], single_pred_dict['rotation_y'][idx],
single_pred_dict['score'][idx]), file=f)
return annos
def evaluation(self, det_annos, class_names, **kwargs):
if 'annos' not in self.kitti_infos[0].keys():
return None, {}
from .kitti_object_eval_python import eval as kitti_eval
eval_det_annos = copy.deepcopy(det_annos)
eval_gt_annos = [copy.deepcopy(info['annos']) for info in self.kitti_infos]
ap_result_str, ap_dict = kitti_eval.get_official_eval_result(eval_gt_annos, eval_det_annos, class_names)
return ap_result_str, ap_dict
def __len__(self):
if self._merge_all_iters_to_one_epoch:
return len(self.kitti_infos) * self.total_epochs
return len(self.kitti_infos)
def __getitem__(self, index):
# index = 4
if self._merge_all_iters_to_one_epoch:
index = index % len(self.kitti_infos)
info = copy.deepcopy(self.kitti_infos[index])
sample_idx = info['point_cloud']['lidar_idx']
img_shape = info['image']['image_shape']
calib = self.get_calib(sample_idx)
get_item_list = self.dataset_cfg.get('GET_ITEM_LIST', ['points'])
input_dict = {
'frame_id': sample_idx,
'calib': calib,
}
if 'annos' in info:
annos = info['annos']
annos = common_utils.drop_info_with_name(annos, name='DontCare')
loc, dims, rots = annos['location'], annos['dimensions'], annos['rotation_y']
gt_names = annos['name']
gt_boxes_camera = np.concatenate([loc, dims, rots[..., np.newaxis]], axis=1).astype(np.float32)
gt_boxes_lidar = box_utils.boxes3d_kitti_camera_to_lidar(gt_boxes_camera, calib)
input_dict.update({
'gt_names': gt_names,
'gt_boxes': gt_boxes_lidar
})
if "gt_boxes2d" in get_item_list:
input_dict['gt_boxes2d'] = annos["bbox"]
road_plane = self.get_road_plane(sample_idx)
if road_plane is not None:
input_dict['road_plane'] = road_plane
if "points" in get_item_list:
points = self.get_lidar(sample_idx)
if self.dataset_cfg.FOV_POINTS_ONLY:
pts_rect = calib.lidar_to_rect(points[:, 0:3])
fov_flag = self.get_fov_flag(pts_rect, img_shape, calib)
points = points[fov_flag]
input_dict['points'] = points
if "images" in get_item_list:
input_dict['images'] = self.get_image(sample_idx)
if "depth_maps" in get_item_list:
input_dict['depth_maps'] = self.get_depth_map(sample_idx)
if "calib_matricies" in get_item_list:
input_dict["trans_lidar_to_cam"], input_dict["trans_cam_to_img"] = custom_utils.calib_to_matricies(calib)
input_dict['calib'] = calib
data_dict = self.prepare_data(data_dict=input_dict)
data_dict['image_shape'] = img_shape
return data_dict
def create_custom_infos(dataset_cfg, class_names, data_path, save_path, workers=4):
dataset = CustomDataset(dataset_cfg=dataset_cfg, class_names=class_names, root_path=data_path, training=False)
train_split, val_split = 'train', 'val'
train_filename = save_path / ('custom_infos_%s.pkl' % train_split)
val_filename = save_path / ('custom_infos_%s.pkl' % val_split)
trainval_filename = save_path / 'custom_infos_trainval.pkl'
test_filename = save_path / 'custom_infos_test.pkl'
print('---------------Start to generate data infos---------------')
dataset.set_split(train_split)
custom_infos_train = dataset.get_infos(num_workers=workers, has_label=True, count_inside_pts=True)
with open(train_filename, 'wb') as f:
pickle.dump(custom_infos_train, f)
print('Kitti info train file is saved to %s' % train_filename)
dataset.set_split(val_split)
custom_infos_val = dataset.get_infos(num_workers=workers, has_label=True, count_inside_pts=True)
with open(val_filename, 'wb') as f:
pickle.dump(custom_infos_val, f)
print('Kitti info val file is saved to %s' % val_filename)
with open(trainval_filename, 'wb') as f:
pickle.dump(custom_infos_train + custom_infos_val, f)
print('Kitti info trainval file is saved to %s' % trainval_filename)
dataset.set_split('test')
custom_infos_test = dataset.get_infos(num_workers=workers, has_label=False, count_inside_pts=False)
with open(test_filename, 'wb') as f:
pickle.dump(custom_infos_test, f)
print('Kitti info test file is saved to %s' % test_filename)
print('---------------Start create groundtruth database for data augmentation---------------')
dataset.set_split(train_split)
dataset.create_groundtruth_database(train_filename, split=train_split)
print('---------------Data preparation Done---------------')
if __name__ == '__main__':
import sys
if sys.argv.__len__() > 1 and sys.argv[1] == 'create_custom_infos':
import yaml
from pathlib import Path
from easydict import EasyDict
dataset_cfg = EasyDict(yaml.safe_load(open(sys.argv[2])))
ROOT_DIR = (Path(__file__).resolve().parent / '../../../').resolve()
create_custom_infos(
dataset_cfg=dataset_cfg,
class_names=['Car', 'Pedestrian', 'Cyclist'],
data_path=ROOT_DIR / 'data' / 'custom',
save_path=ROOT_DIR / 'data' / 'custom'
)
框架数据集初始化文件
在/pcdet/datasets中,打开初始化文件,加入我们新创建的类,注意逗号等细节问题
1
2from .custom.custom_dataset import CustomDataset
'CustomDataset': CustomDataset
数据载入
于是就到了验证成果的时候了,生成序列化数据,在OpenPCDet文件夹下:
1
python -m pcdet.datasets.custom.custom_dataset create_custom_infos tools/cfgs/dataset_configs/custom_dataset.yaml
训练
在OpenPCDet/pcdet/models/detectors/detector3d_template.py中61行vfe.__all__[self.model_cfg.VFE.NAME]注释掉grid元素,在43、62 行注释掉depth_downsample_factor,60行删去逗号,这是构造函数的参数引起的冲突,详见Q&A。
进入tools文件夹: 1
2
3
4//后台
nohup python -u train.py --cfg_file cfgs/custom_models/pointpillar.yaml > log.file 2>&1 &
//前台
python train.py --cfg_file cfgs/custom_models/pointpillar.yaml
评估
首先去除截断信息truncate,在pcdet/datasets/custom/kitti_object_eval_python/eval.py注释掉截断标注:truncate:L56、L573
1
python test.py --cfg_file /root/autodl-tmp/opcnet/OpenPCDet/tools/cfgs/custom_models/pointpillar.yaml --batch_size 16 --ckpt /root/autodl-tmp/opcnet/OpenPCDet/output/custom_models/pointpillar/default/ckpt/checkpoint_epoch_80.pth
 官方论文中给出的参考数据是:
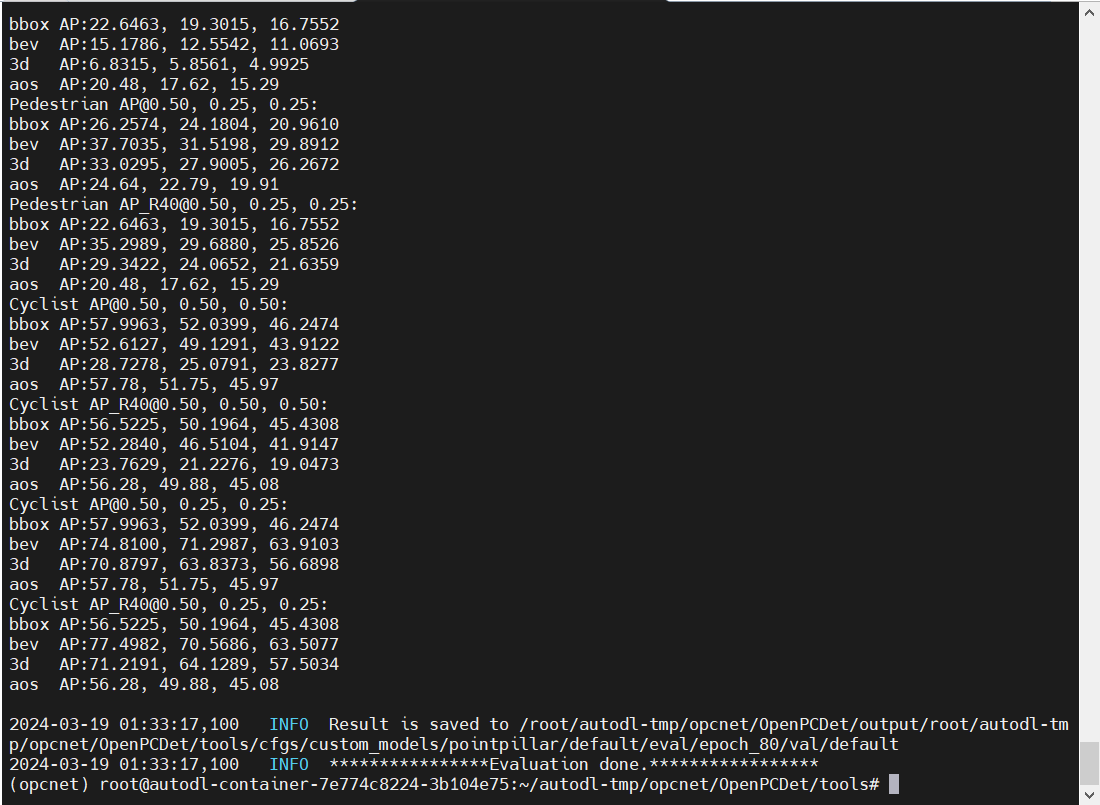
官方论文中给出的参考数据是: 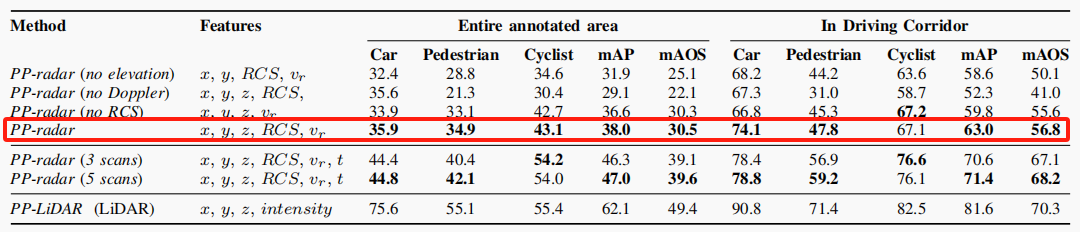 以3D框标注为准,汽车需要50%重叠,行人、骑行者需要25%重叠认为检测成功,我们80轮训练的评估结果是汽车:32-37%对35.9/74.1,行人26.2-27.7%对34.9/67.1,骑行者56.6898-63.8373%对43,1/67.1(注意这不是严谨的比较),可见行人是训练结果较差的,当然汽车、行人、骑行者都比不上激光雷达70-90的准确率。
以3D框标注为准,汽车需要50%重叠,行人、骑行者需要25%重叠认为检测成功,我们80轮训练的评估结果是汽车:32-37%对35.9/74.1,行人26.2-27.7%对34.9/67.1,骑行者56.6898-63.8373%对43,1/67.1(注意这不是严谨的比较),可见行人是训练结果较差的,当然汽车、行人、骑行者都比不上激光雷达70-90的准确率。
可视化
修改:demo.py:L48, 改为7维:reshape(-1,7);运行 1
2//随便找几张看看
python demo.py --cfg_file /root/autodl-tmp/opcnet/OpenPCDet/tools/cfgs/custom_models/pointpillar.yaml --ckpt /root/autodl-tmp/opcnet/OpenPCDet/output/custom_models/pointpillar/default/ckpt/checkpoint_epoch_80.pth --data_path /root/autodl-tmp/opcnet/OpenPCDet/data/custom/testing/velodyne/06471.bin
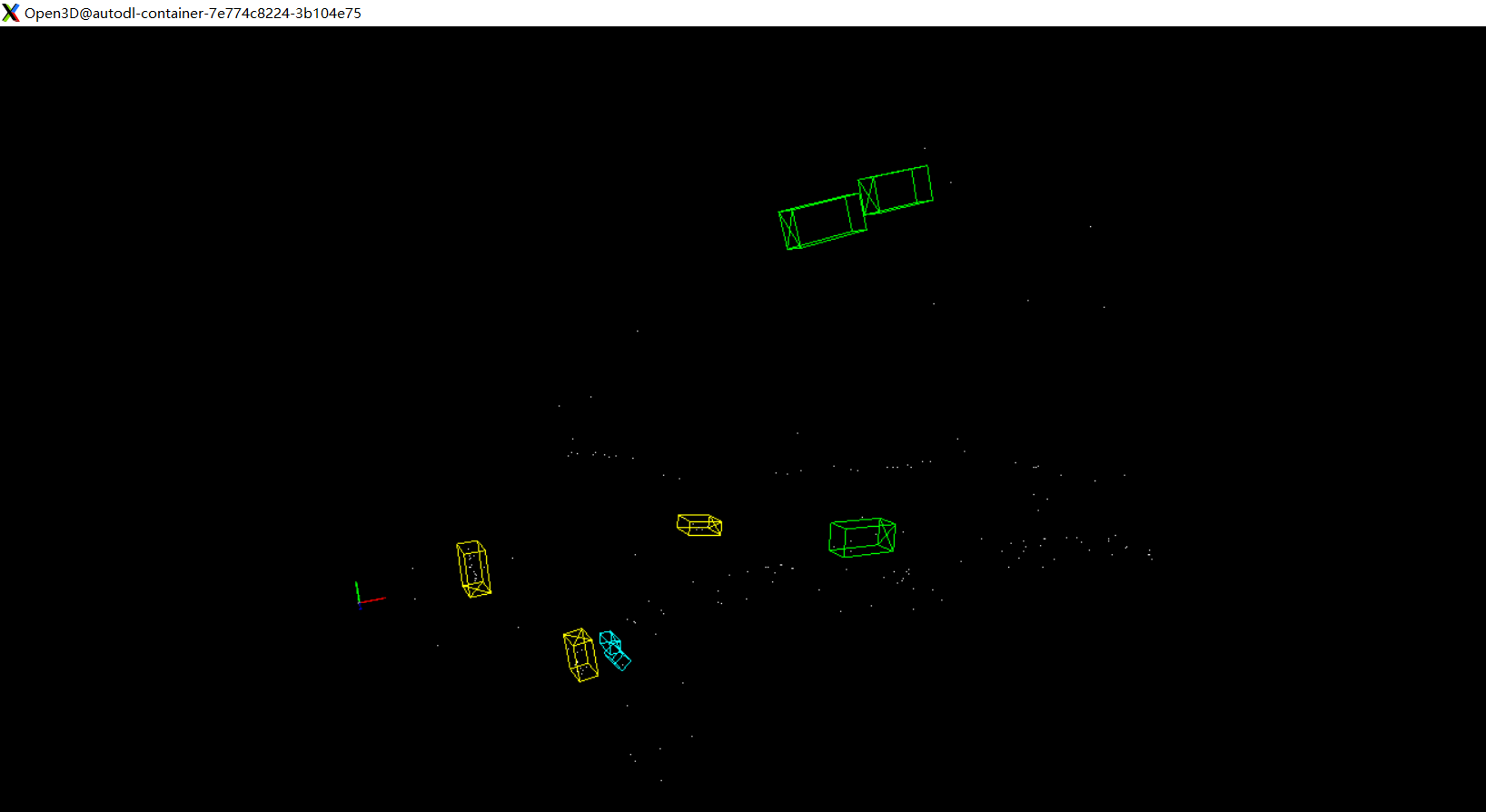 可见误检测的框是比较多的,点云也十分稀疏。
可见误检测的框是比较多的,点云也十分稀疏。
Q&A
- 数据载入命令报错: /root/miniconda3/envs/opcnet/lib/python3.8/runpy.py:125: RuntimeWarning: 'pcdet.datasets.custom.custom_dataset' found in sys.modules after import of package 'pcdet.datasets.custom', but prior to execution of 'pcdet.datasets.custom.custom_dataset'; this may result in unpredictable behaviour
理由是生成数据字典命令和dataset里面生成数据名称不对应,如kitti和custom,应该检查你的kitti是不是全部变成custom了。
- 训练时,有grid报错:init() got an unexpected keyword argument 'grid_size'?
理由是初始化函数不应该有grid_size,却传入了grid_size,导致参数不匹配。解决方法按照前文注释即可。拓展:grid_size是划分网格的数量,开始时以为是配置没有传入,但是KITTI中配置也没有传入,原来是在processor中根据POINT_CLOUD_RANGE和VOXEL_SIZE自动计算的,_processor.py中有点到体素的计算方法。
